2.5 RDD 中的函数传递
在实际开发中我们往往需要自己定义一些对于 RDD 的操作,那么此时需要主要的
是,初始化工作是在 Driver 端进行的,而实际运行程序是在 Executor 端进行的,这就涉及
到了跨进程通信,是需要序列化的。下面我们看几个例子:
2.5.1 传递一个方法
1.创建一个类
class Search(s:String){ //过滤出包含字符串的数据 def isMatch(s: String): Boolean = { s.contains(query) } //过滤出包含字符串的 RDD def getMatch1 (rdd: RDD[String]): RDD[String] = { rdd.filter(isMatch) } //过滤出包含字符串的 RDD def getMatche2(rdd: RDD[String]): RDD[String] = { rdd.filter(x => x.contains(query)) } }
2.创建 Spark 主程序
object SeriTest { def main(args: Array[String]): Unit = { //1.初始化配置信息及 SparkContext val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(sparkConf) //2.创建一个 RDD val rdd: RDD[String] = sc.parallelize(Array("hadoop", "spark", "hive", "atguigu")) //3.创建一个 Search 对象 val search = new Search() //4.运用第一个过滤函数并打印结果 val match1: RDD[String] = search.getMatche1(rdd) match1.collect().foreach(println) } }
3.运行程序
Exception in thread "main" org.apache.spark.SparkException: Task not serializable at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298) at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCle aner.scala:288) at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:108) at org.apache.spark.SparkContext.clean(SparkContext.scala:2101) at org.apache.spark.rdd.RDD$$anonfun$filter$1.apply(RDD.scala:387) at org.apache.spark.rdd.RDD$$anonfun$filter$1.apply(RDD.scala:386) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:362) at org.apache.spark.rdd.RDD.filter(RDD.scala:386) at com.atguigu.Search.getMatche1(SeriTest.scala:39) at com.atguigu.SeriTest$.main(SeriTest.scala:18) at com.atguigu.SeriTest.main(SeriTest.scala) Caused by: java.io.NotSerializableException: com.atguigu.Search
4.问题说明
//过滤出包含字符串的 RDD def getMatch1 (rdd: RDD[String]): RDD[String] = { rdd.filter(isMatch) }
在这个方法中所调用的方法 isMatch()是定义在 Search 这个类中的,实际上调用的是
this. isMatch(),this 表示 Search 这个类的对象,程序在运行过程中需要将 Search 对象序列
化以后传递到 Executor 端。
5.解决方案
使类继承 scala.Serializable 即可。
class Search() extends Serializable{...}
2.5.2 传递一个属性
1.创建 Spark 主程序
object TransmitTest { def main(args: Array[String]): Unit = { //1.初始化配置信息及 SparkContext val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(sparkConf) //2.创建一个 RDD val rdd: RDD[String] = sc.parallelize(Array("hadoop", "spark", "hive", "atguigu")) //3.创建一个 Search 对象 val search = new Search() //4.运用第一个过滤函数并打印结果 val match1: RDD[String] = search.getMatche2(rdd) match1.collect().foreach(println) } }
2.运行程序
Exception in thread "main" org.apache.spark.SparkException: Task not serializable at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298) at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCle aner.scala:288) at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:108) at org.apache.spark.SparkContext.clean(SparkContext.scala:2101) at org.apache.spark.rdd.RDD$$anonfun$filter$1.apply(RDD.scala:387) at org.apache.spark.rdd.RDD$$anonfun$filter$1.apply(RDD.scala:386) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:362) at org.apache.spark.rdd.RDD.filter(RDD.scala:386) at com.atguigu.Search.getMatche1(SeriTest.scala:39) at com.atguigu.SeriTest$.main(SeriTest.scala:18) at com.atguigu.SeriTest.main(SeriTest.scala) Caused by: java.io.NotSerializableException: com.atguigu.Search
3.问题说明
//过滤出包含字符串的 RDD def getMatche2(rdd: RDD[String]): RDD[String] = { rdd.filter(x => x.contains(query)) }
在这个方法中所调用的方法 query 是定义在 Search 这个类中的字段,实际上调用的是
this. query,this 表示 Search 这个类的对象,程序在运行过程中需要将 Search 对象序列化以
后传递到 Executor 端。
4.解决方案
1)使类继承 scala.Serializable 即可。
class Search() extends Serializable{...}
2)将类变量 query 赋值给局部变量
修改 getMatche2 为
//过滤出包含字符串的 RDD def getMatche2(rdd: RDD[String]): RDD[String] = { val query_ : String = this.query//将类变量赋值给局部变量 rdd.filter(x => x.contains(query_)) }
2.6 RDD 依赖关系
2.6.1 Lineage
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列
Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据
信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和
恢复丢失的数据分区。
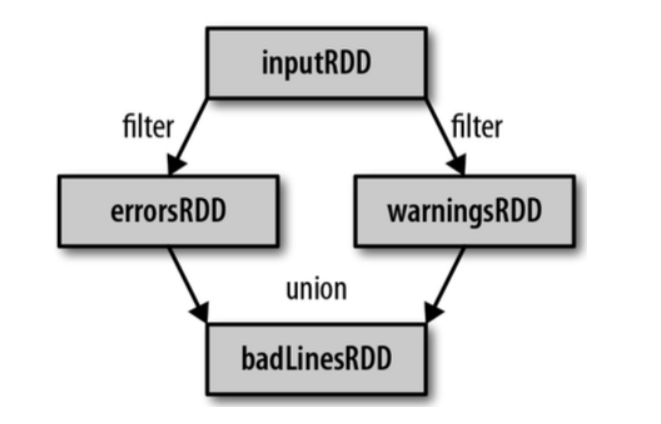
(1)读取一个 HDFS 文件并将其中内容映射成一个个元组
scala> val wordAndOne = sc.textFile("/fruit.tsv").flatMap(_.split(" ")).map((_,1)) wordAndOne: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[22] at map at <console>:24
(2)统计每一种 key 对应的个数
scala> val wordAndCount = wordAndOne.reduceByKey(_+_) wordAndCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[23] at reduceByKey at <console>:26
(3)查看“wordAndOne”的 Lineage
scala> wordAndOne.toDebugString res5: String = (2) MapPartitionsRDD[22] at map at <console>:24 [] | MapPartitionsRDD[21] at flatMap at <console>:24 [] | /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 [] | /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
(4)查看“wordAndCount”的 Lineage
scala> wordAndCount.toDebugString res6: String = (2) ShuffledRDD[23] at reduceByKey at <console>:26 [] +-(2) MapPartitionsRDD[22] at map at <console>:24 [] | MapPartitionsRDD[21] at flatMap at <console>:24 [] | /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 [] | /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
(5)查看“wordAndOne”的依赖类型
scala> wordAndOne.dependencies res7: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@5d5db92b)
(6)查看“wordAndCount”的依赖类型
scala> wordAndCount.dependencies res8: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@63f3e6a8)
注意:RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(narrow
dependency)和宽依赖(wide dependency)。
2.6.2 窄依赖
窄依赖指的是每一个父 RDD 的 Partition 最多被子 RDD 的一个 Partition 使用,
窄依赖我们形象的比喻为独生子女

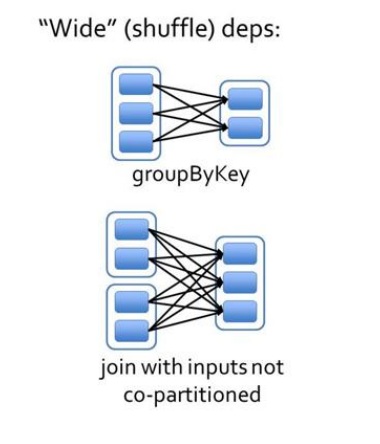
2.6.3 宽依赖
宽依赖指的是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition,会引起 shuffle,
总结:宽依赖我们形象的比喻为超生

2.6.4 DAG
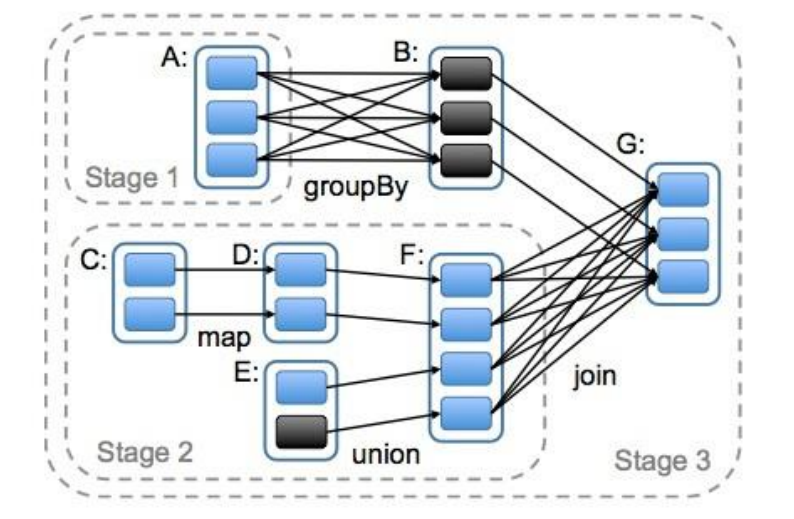
DAG(Directed Acyclic Graph)叫做有向无环图,原始的 RDD 通过一系列的转换就就
形成了 DAG,根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage,对于窄依
赖,partition 的转换处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能
在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
2.6.5 任务划分(面试重点)
RDD 任务切分中间分为:Application、Job、Stage 和 Task
1)Application:初始化一个 SparkContext 即生成一个 Application(一个 jar 包相当于一个 Application)
一个 Application 可以有多个 Job。
2)Job:一个 Action 算子就会生成一个 Job
一个 Job 中可以有多个 Stage。
3)Stage:根据 RDD 之间的依赖关系的不同将 Job 划分成不同的 Stage,遇到一个宽依赖则划分一个 Stage。
4)Task:Stage 是一个 TaskSet,将 Stage 划分的结果发送到不同的 Executor 执行即为一个 Task。
一个 Task 就是一个并行度,并行度和数据分片有关
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
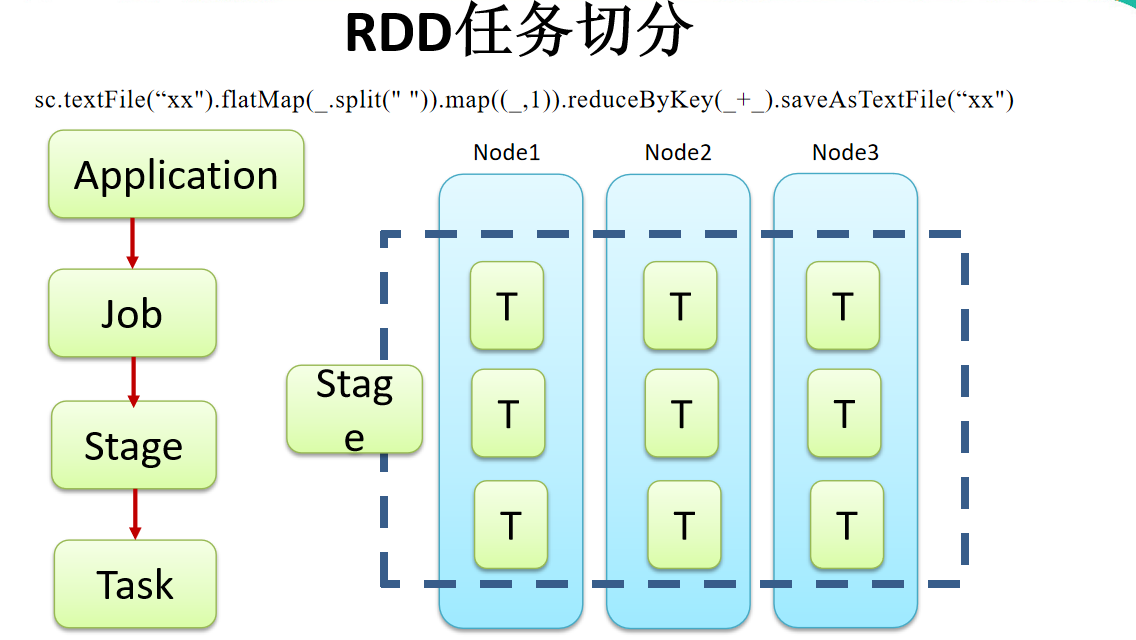
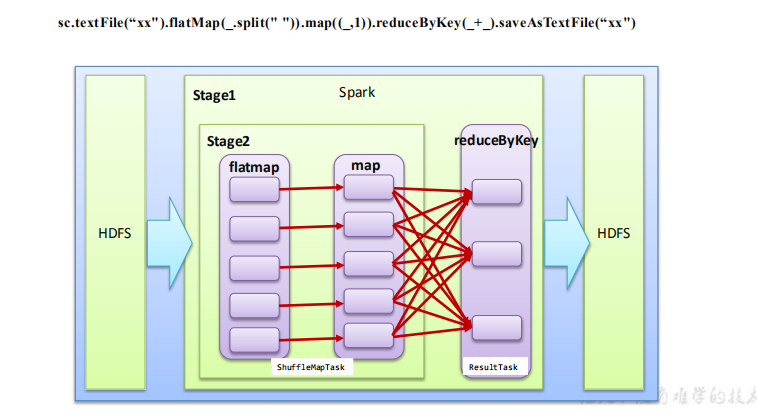
划分 Stage 从后往前划分,遇到一个宽依赖则划分一个 Stage,将其放入栈。
运行从前往后执行。
2.7 RDD 缓存
RDD 通过 persist 方法或 cache 方法可以将前面的计算结果缓存,默认情况下 persist()
会把数据以序列化的形式缓存在 JVM 的堆空间中。
但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 时,该 RDD 将会
被缓存在计算节点的内存中,并供后面重用。

通过查看源码发现 cache 最终也是调用了 persist 方法,默认的存储级别都是仅在内存
存储一份,Spark 的存储级别还有好多种,存储级别在 object StorageLevel 中定义的。

在存储级别的末尾加上“_2”来把持久化数据存为两份

缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD 的缓存容
错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢
失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部
分即可,并不需要重算全部 Partition。
(1)创建一个 RDD
scala> val rdd = sc.makeRDD(Array("atguigu")) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[19] at makeRDD at <console>:25
(2)将 RDD 转换为携带当前时间戳不做缓存
scala> val nocache = rdd.map(_.toString+System.currentTimeMillis) nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at map at <console>:27
(3)多次打印结果
scala> nocache.collect res0: Array[String] = Array(atguigu1538978275359) scala> nocache.collect res1: Array[String] = Array(atguigu1538978282416) scala> nocache.collect res2: Array[String] = Array(atguigu1538978283199)
(4)将 RDD 转换为携带当前时间戳并做缓存
scala> val cache = rdd.map(_.toString+System.currentTimeMillis).cache cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[21] at map at <console>:27
(5)多次打印做了缓存的结果
scala> cache.collect res3: Array[String] = Array(atguigu1538978435705) scala> cache.collect res4: Array[String] = Array(atguigu1538978435705) scala> cache.collect res5: Array[String] = Array(atguigu1538978435705)
测试:
scala> val rdd = sc.makeRDD(1 to 10) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24 scala> val nocache = rdd.map(_.toString+System.currentTimeMillis) nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at map at <console>:26 scala> val cache = rdd.map(_.toString+System.currentTimeMillis) cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at map at <console>:26 scala> cache.cache res0: cache.type = MapPartitionsRDD[2] at map at <console>:26 scala> nocache.collect res1: Array[String] = Array(11562515465448, 21562515465448, 31562515465448, 41562515465448, 51562515465448, 61562515465448, 71562515465448, 81562515465448, 91562515465448, 101562515465448) scala> nocache.collect res2: Array[String] = Array(11562515494614, 21562515494614, 31562515494613, 41562515494613, 51562515494613, 61562515494613, 71562515494613, 81562515494623, 91562515494623, 101562515494623) scala> cache.collect res3: Array[String] = Array(11562515522191, 21562515522191, 31562515522191, 41562515522201, 51562515522201, 61562515522191, 71562515522191, 81562515522191, 91562515522191, 101562515522191) scala> cache.collect res4: Array[String] = Array(11562515522191, 21562515522191, 31562515522191, 41562515522201, 51562515522201, 61562515522191, 71562515522191, 81562515522191, 91562515522191, 101562515522191)
2.8 RDD CheckPoint
Spark 中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点
(本质是通过将 RDD 写入 Disk 做检查点)是为了通过 lineage 做容错的辅助,lineage 过长
会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而
丢失分区,从做检查点的 RDD 开始重做 Lineage,就会减少开销。检查点通过将数据写入
到 HDFS 文件系统实现了 RDD 的检查点功能。
为当前 RDD 设置检查点。该函数将会创建一个二进制的文件,并存储到 checkpoint 目
录中,该目录是用 SparkContext.setCheckpointDir()设置的。在 checkpoint 的过程中,该
RDD 的所有依赖于父 RDD 中的信息将全部被移除。对 RDD 进行 checkpoint 操作并不会马
上被执行,必须执行 Action 操作才能触发。
案例实操:
(1)设置检查点
scala> sc.setCheckpointDir("hdfs://hadoop102:9000/checkpoint")
(2)创建一个 RDD
scala> val rdd = sc.parallelize(Array("atguigu")) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[14] at parallelize at <console>:24
(3)将 RDD 转换为携带当前时间戳并做 checkpoint
scala> val ch = rdd.map(_+System.currentTimeMillis) ch: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[16] at map at <console>:26 scala> ch.checkpoint
(4)多次打印结果
scala> ch.collect res55: Array[String] = Array(atguigu1538981860336) scala> ch.collect res56: Array[String] = Array(atguigu1538981860504) scala> ch.collect res57: Array[String] = Array(atguigu1538981860504) scala> ch.collect res58: Array[String] = Array(atguigu1538981860504)
测试:
[lxl@hadoop102 ~]$ hadoop fs -mkdir /checkpoint
scala> sc.setCheckpointDir("hdfs://hadoop102:9000/checkpoint") scala> val ch1 = sc.parallelize(1 to 2) ch1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:24 scala> val ch2 = ch1.map(_.toString+"["+System.currentTimeMillis+"]") ch2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at map at <console>:26 scala> val ch3 = ch1.map(_.toString+"["+System.currentTimeMillis+"]") ch3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at map at <console>:26 scala> ch3.checkpoint scala> ch3.collect res7: Array[String] = Array(1[1562516623743], 2[1562516623749]) scala> ch3.collect res8: Array[String] = Array(1[1562516623898], 2[1562516623898]) scala> ch3.collect res9: Array[String] = Array(1[1562516623898], 2[1562516623898]) scala> ch3.collect res10: Array[String] = Array(1[1562516623898], 2[1562516623898]) scala> ch3.collect res11: Array[String] = Array(1[1562516623898], 2[1562516623898]) scala> ch2.collect res12: Array[String] = Array(1[1562516678410], 2[1562516678409]) scala> ch2.collect res13: Array[String] = Array(1[1562516680347], 2[1562516680346]) scala> ch2.collect res14: Array[String] = Array(1[1562516681484], 2[1562516681484]) scala> ch2.collect res15: Array[String] = Array(1[1562516682415], 2[1562516682414])