1.Map接口

2.HashMap的遍历方式
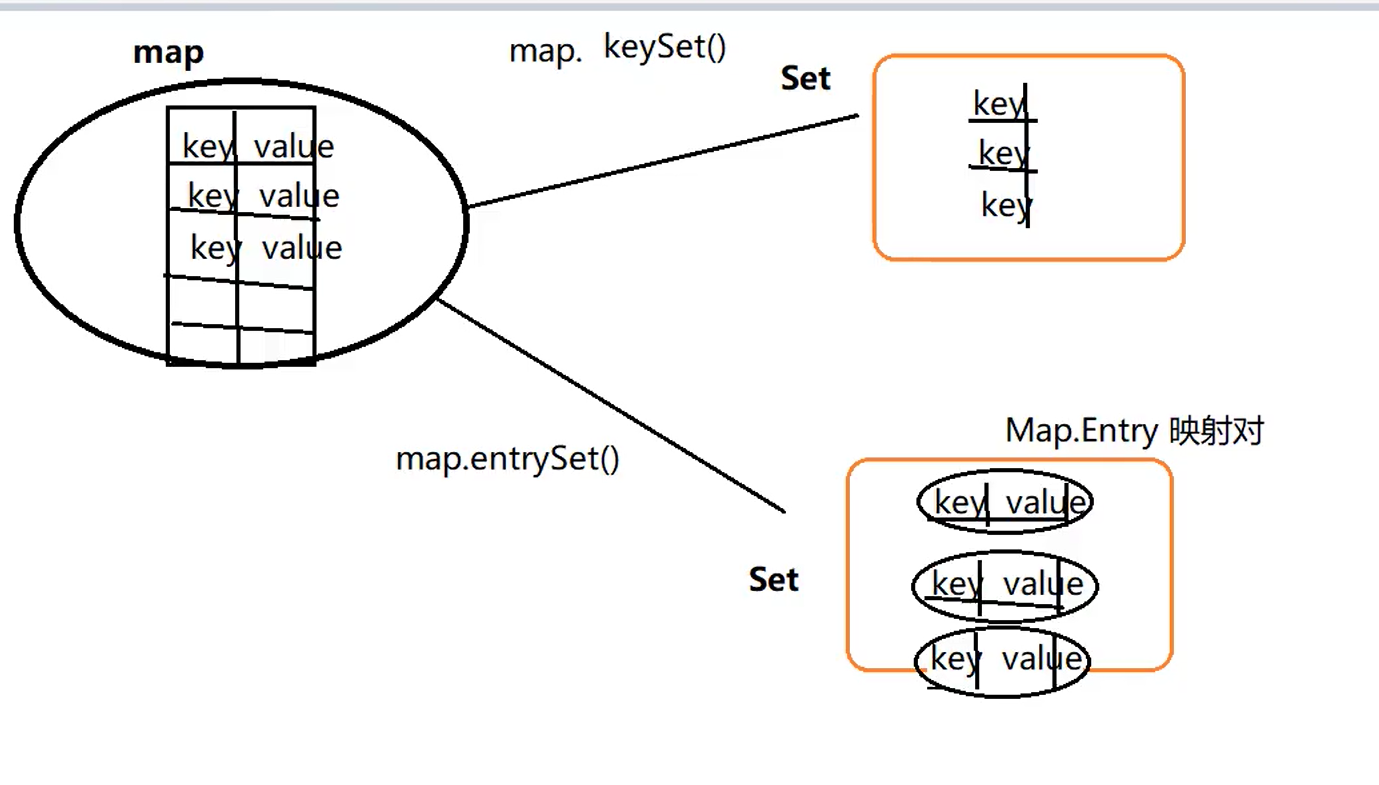
(1)keySet()方法
通过map.keySet()方法 进行将所有的key变为一个集合set。然后通过遍历set集合(可以使用foreach或者迭代器)
得到每一个key 然后通过map.get(key)通过map得到value
(2)entrySet()方法
Entry是一个键值对类型。
通过此方法能得到一个全是entry类型(也就是全为键值对的)集合set
然后我们通过foreach将集合set里面的键值对取出来 进行getKey() getValue()方法。
public static void main(String[] args) { HashMap<String,String> map=new HashMap<>(); map.put("ch","中国"); map.put("uk","英国"); map.put("us","美国"); Set<String> kset = map.keySet(); System.out.println("keySet=========="); System.out.println("==========1============="); for (String s : kset) { System.out.println(s+" "+map.get(s)); } System.out.println("==========2============="); Iterator<String> iterator = kset.iterator(); while(iterator.hasNext()){ String s=iterator.next(); System.out.println(s+" "+map.get(s)); } System.out.println("entrySet============"); Set<Map.Entry<String, String>> entries = map.entrySet(); for (Map.Entry<String,String> s: entries) { System.out.println(s.getKey()+" "+s.getValue()); } }
3.map实现类

4.继承结构

5.Node结构 (实现了map的Entry接口 键值对 )
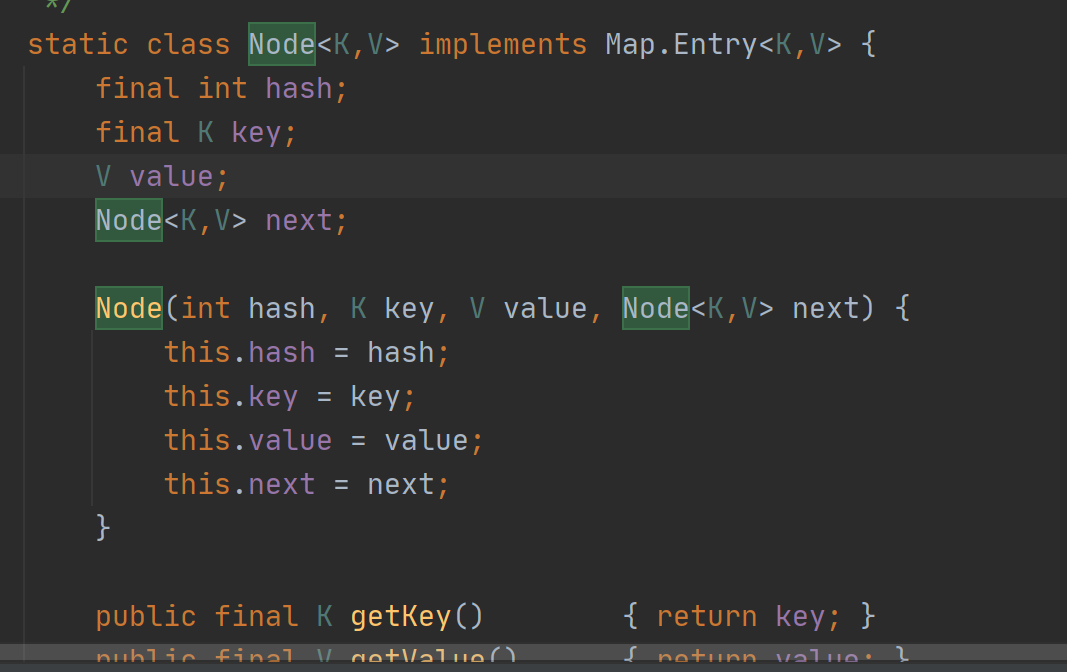
这里面的next是使用哈希表(拉链法)是需要链表。
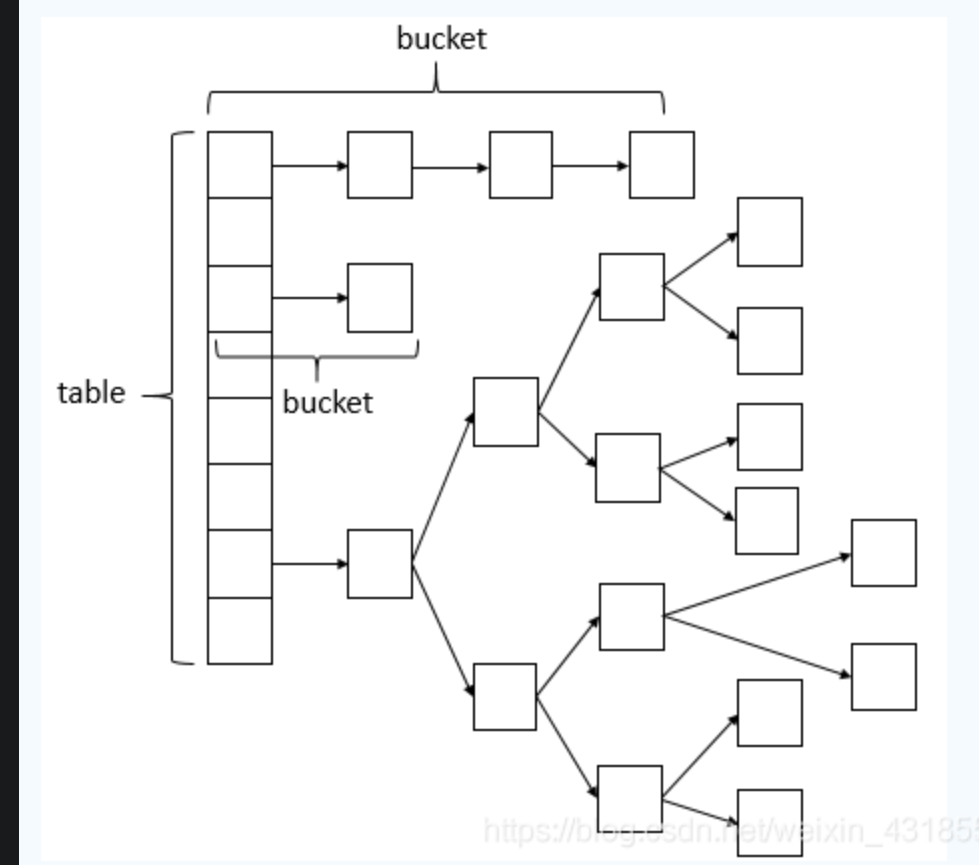
6.HashMap底层结构及变化
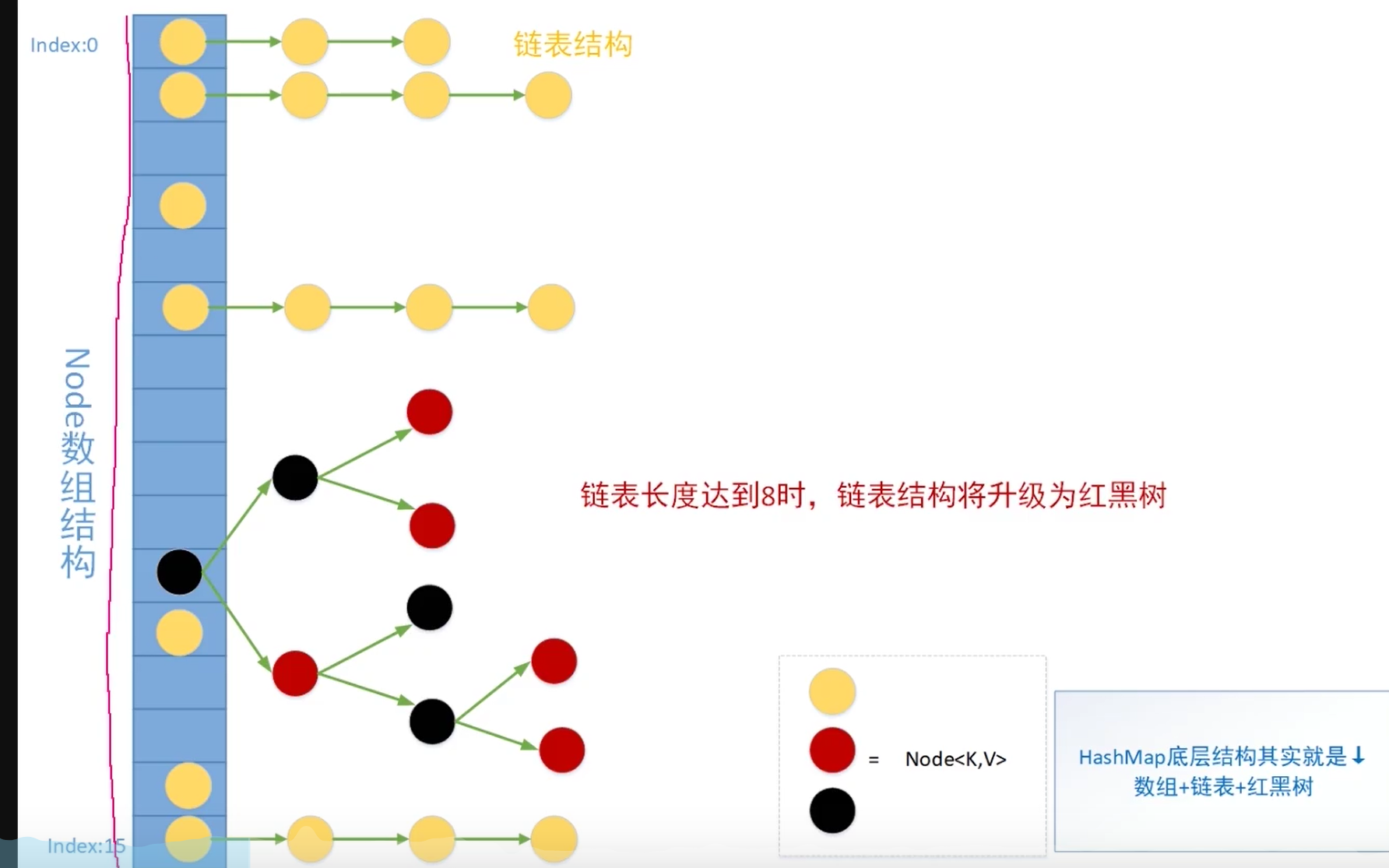
7.插入图例

8.HashMap属性
HashMap的实例有两个参数影响其性能。
初始容量:哈希表中桶的数量
加载因子:哈希表在其容量自动增加之前可以达到多满的一种尺度
当哈希表中条目数超出了当前容量*加载因子(其实就是HashMap的实际容量)时,则对该哈希表进行rehash操作,将哈希表扩充至两倍的桶数。
Java中默认初始容量为16,加载因子为0.75。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 static final float DEFAULT_LOAD_FACTOR = 0.75f;
1)loadFactor加载因子
定义:loadFactor译为装载因子。装载因子用来衡量HashMap满的程度。loadFactor的默认值为0.75f。loadFactor=size/capacity
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,
浪费很多空间,这样也不好,所以在hashMap中loadFactor的初始值就是0.75,一般情况下不需要更改它。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
2)桶
根据前面画的HashMap存储的数据结构图,你这样想,数组中每一个位置上都放有一个桶,每个桶里就是装一个链表,链表中可以有很多个元素(entry),这就是桶的意思。也就相当于把元素都放在桶中。
3)capacity
capacity译为容量代表的数组的容量,也就是数组的长度,同时也是HashMap中桶的个数。默认值是16。
一般第一次扩容时会扩容到64,之后好像是2倍。总之,容量都是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
4)size的含义
size就是在该HashMap的实例中实际存储的元素的个数
5)threshold的作用
threshold = capacity * loadFactor,当Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是衡量数组是否需要扩增的一个标准。扩容阈值
注意这里说的是考虑,因为实际上要扩增数组,除了这个size>=threshold条件外,还需要另外一个条件。
什么时候会扩增数组的大小?在put一个元素时先size>=threshold并且还要在对应数组位置上有元素,这才能扩增数组。
int threshold;
我们通过一张HashMap的数据结构图来分析:

9.构造方法

1)HashMap()
//看上面的注释就已经知道,DEFAULT_INITIAL_CAPACITY=16,DEFAULT_LOAD_FACTOR=0.75
//初始化容量:也就是初始化数组的大小
//加载因子:数组上的存放数据疏密程度。
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
2)HashMap(int)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);//初始容量
}
3)HashMap(int,float)

public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值,否则为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充因子不能小于或等于0,不能为非数字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化填充因子
this.loadFactor = loadFactor;
// 初始化threshold大小
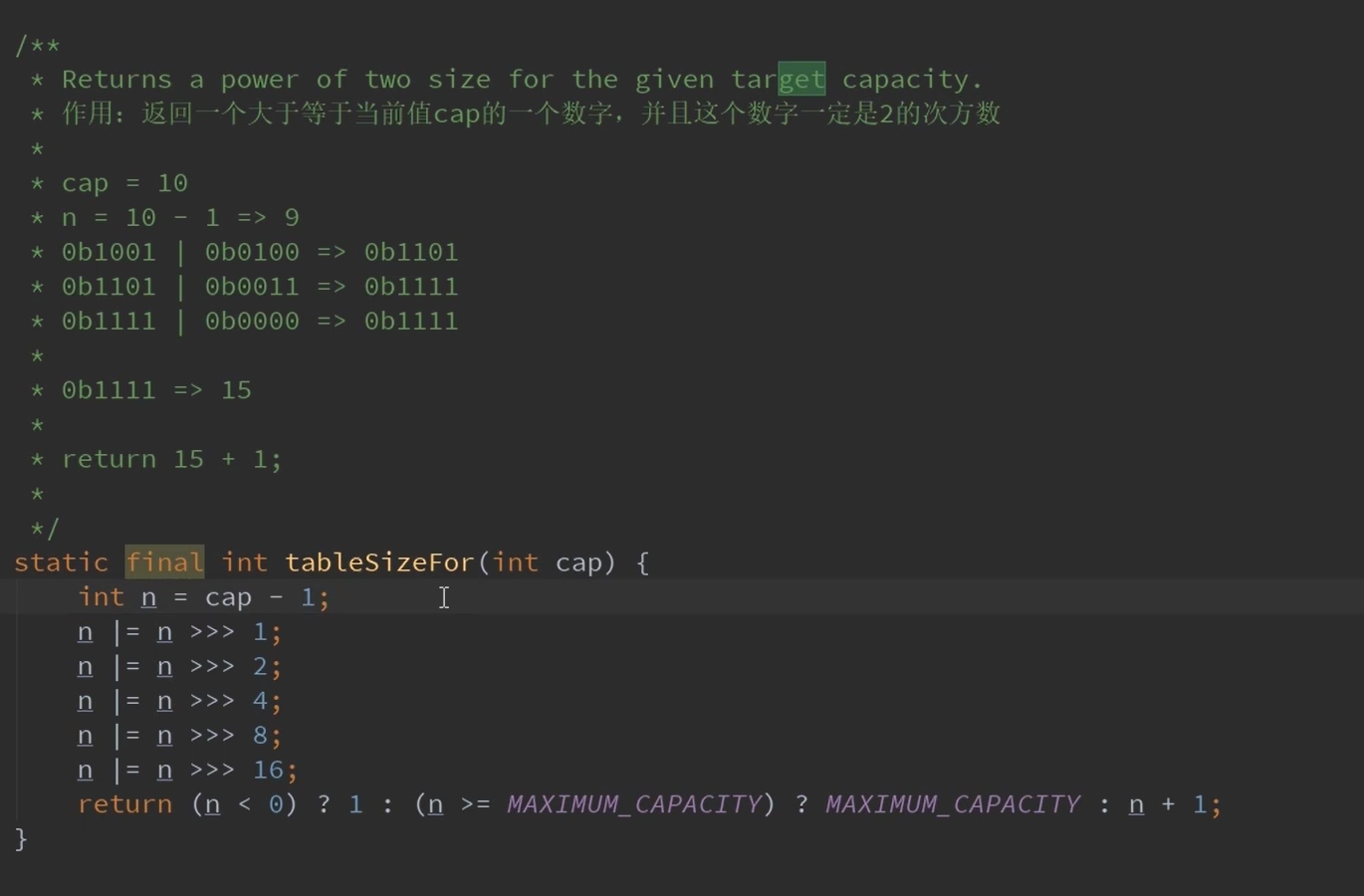
this.threshold = tableSizeFor(initialCapacity);
}
4)HashMap(Map<? extends K, ? extends V> m)
public HashMap(Map<? extends K, ? extends V> m) {
// 初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 将m中的所有元素添加至HashMap中
putMapEntries(m, false);
}
putMapEntries(Map<? extends K, ? extends V> m, boolean evict)函数将m的所有元素存入本HashMap实例中
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}


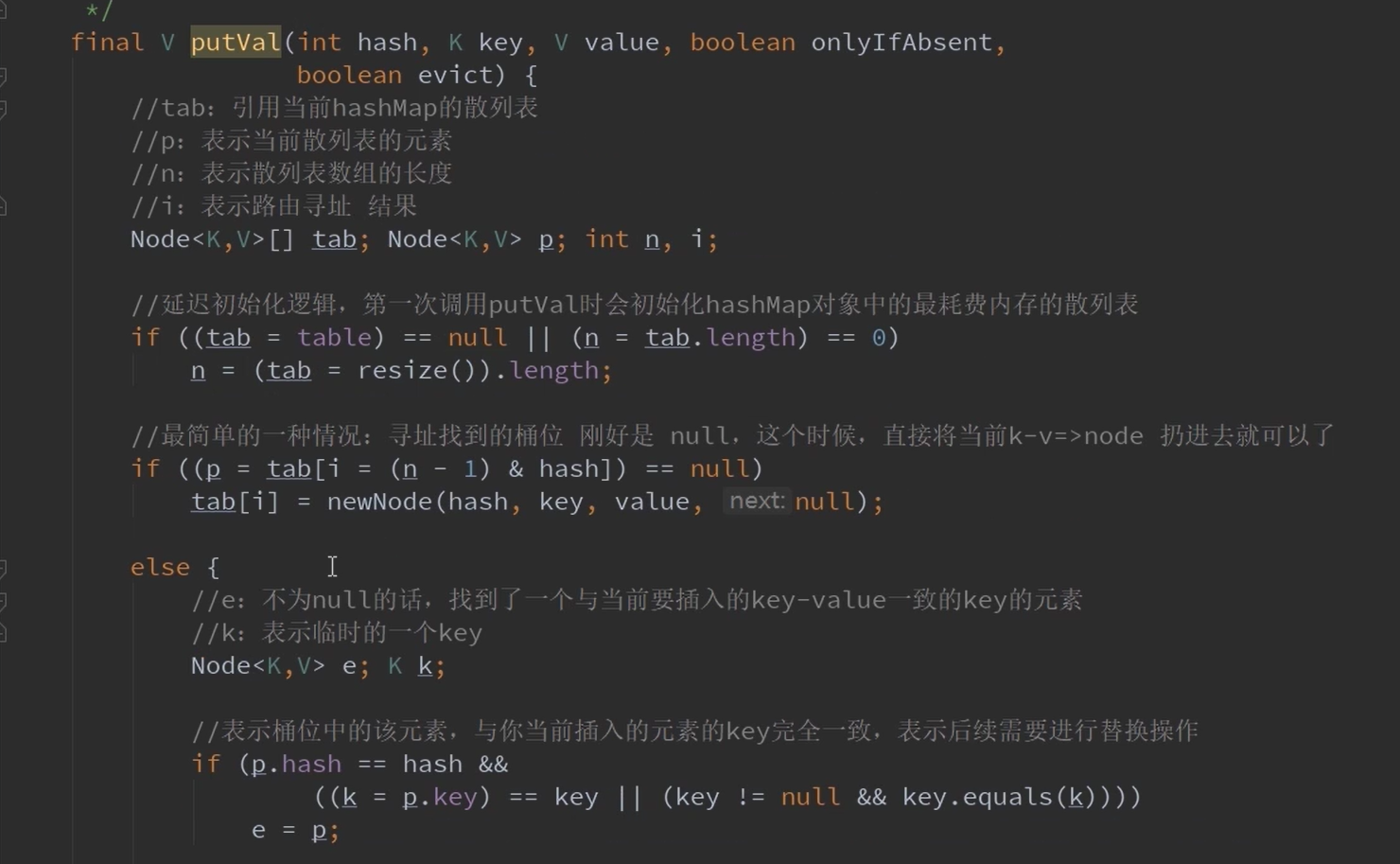
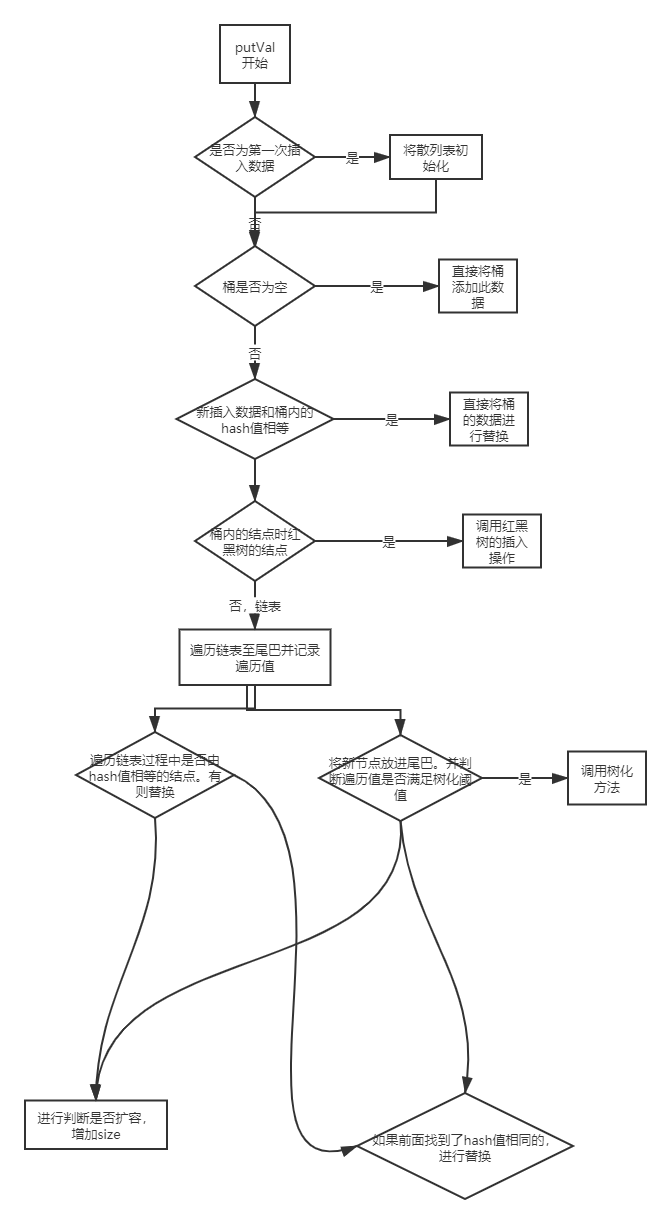
10.put方法

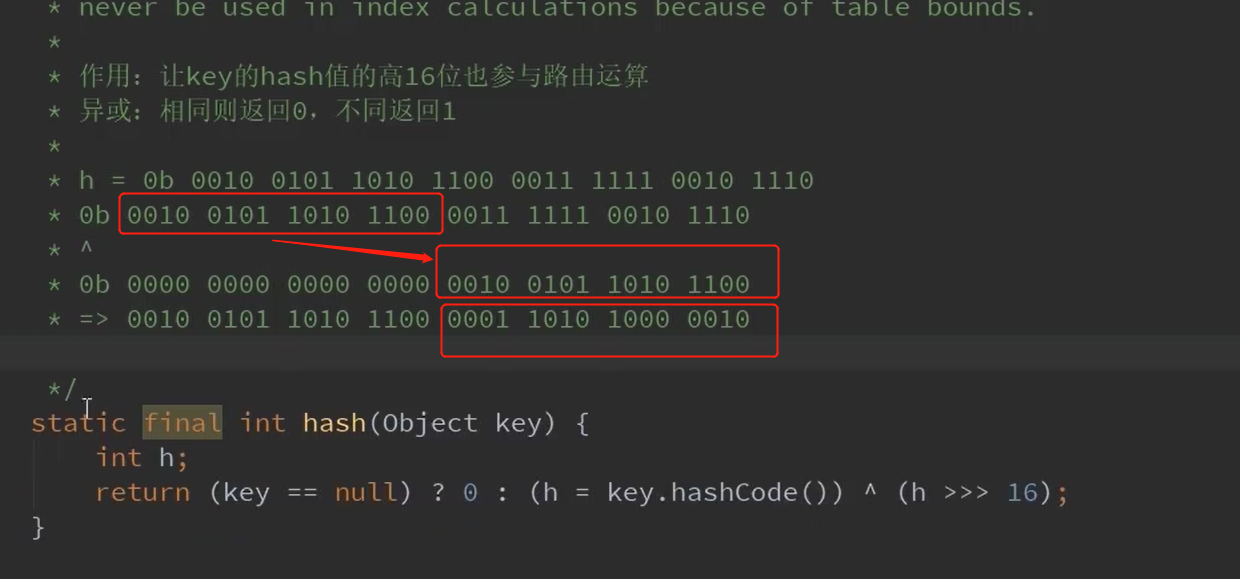
当数组特别小(16、32等) 这样使前16位也参与运算,减少哈希冲突。(哈希扰动) 这里是计算hash值。
在进行插入数组的时候还需要进行(hash&(table.length-1))的计算,这样可以满足在table上。
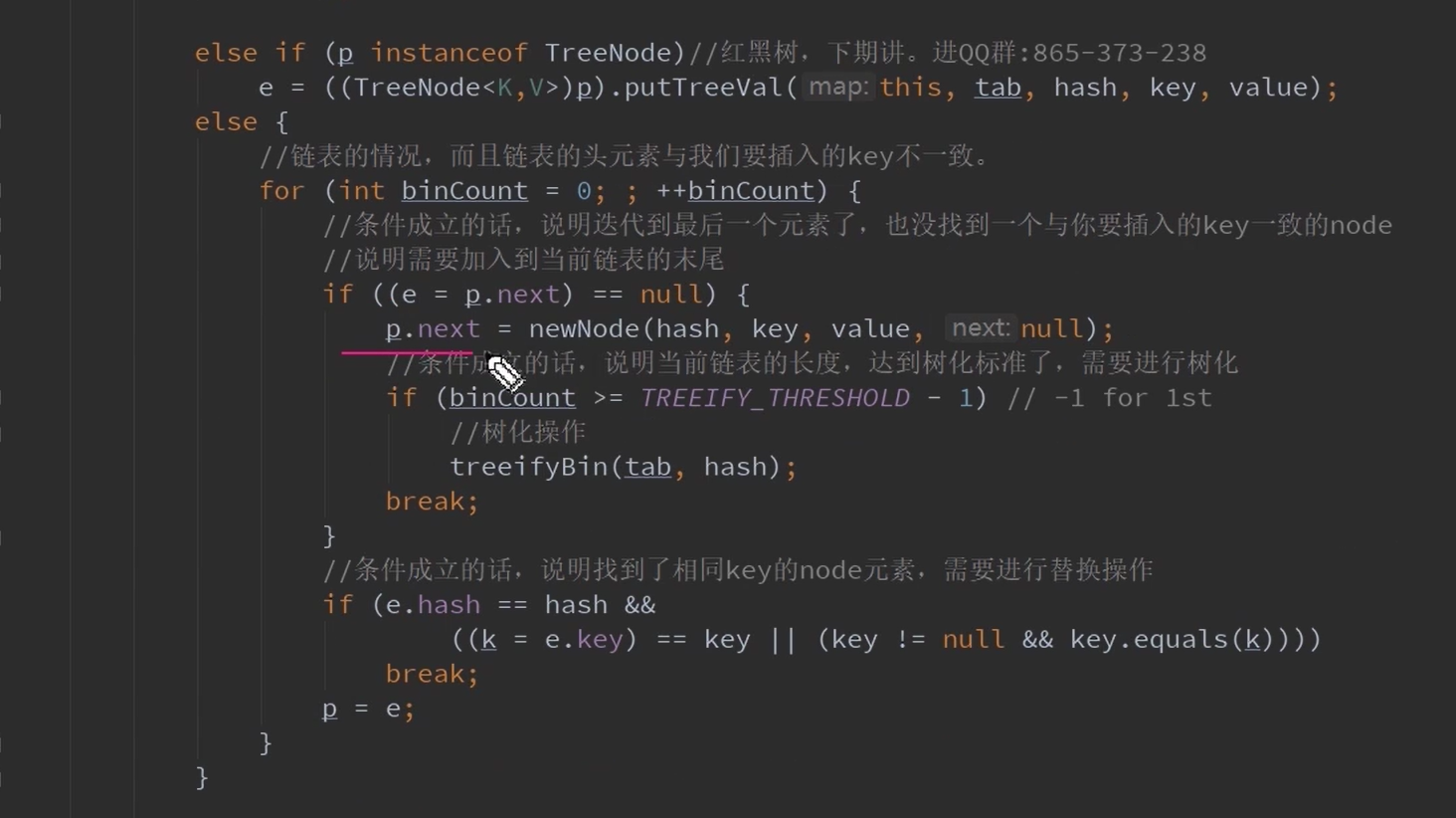
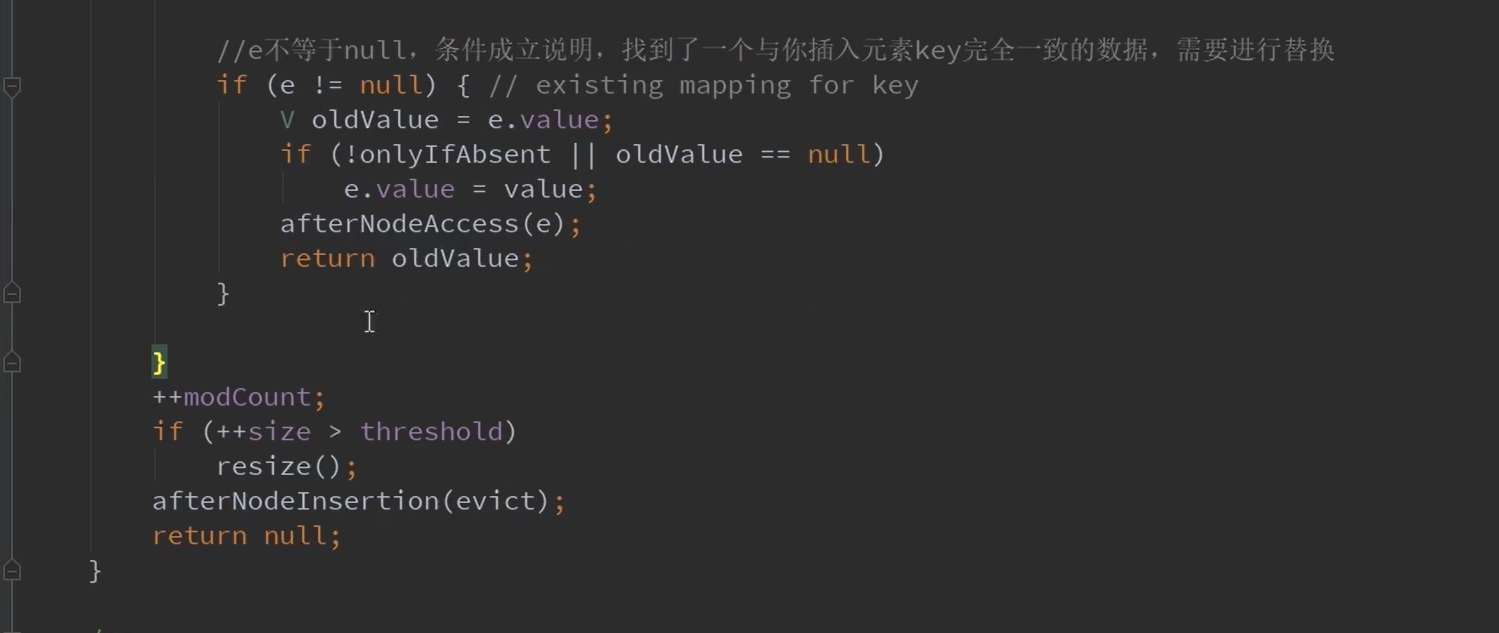
这个if是在上面2种情况(1)桶内直接有一个hash相等的,(2)遍历链表有一个hash值相等的
将oldvalue进行替换
11.哈希寻址算法(hash&(table.length-1))
我们在上面说过key的hash值 是由hashcode方法经扰动得到的。
在数组中寻址的公式是(hash&(table.length-1))
由于key的hash值可能很长,但是&操作 以及数组的大小限制了寻址的范围
例子:
0111 1111 hash
1111 table的长度为16(16-1=15)
=
1111 位置在数组的第15位上 table[15]
因为&操作,让无论你hash值多少位,碰上了我的table长度,前面都为0(因为table长度 1前面都是0 与操作=0)
由此引出了 扩容之后的寻址过程。
假设上面的例子进行了扩容。因为扩容是左移1位,16位变32位。
0111 1111 hash
1 1111 table(32)
=
1 1111 位置(在table第31位table[31])
由此我们可以看出扩容之后 各个结点是如何进行再次寻址的。
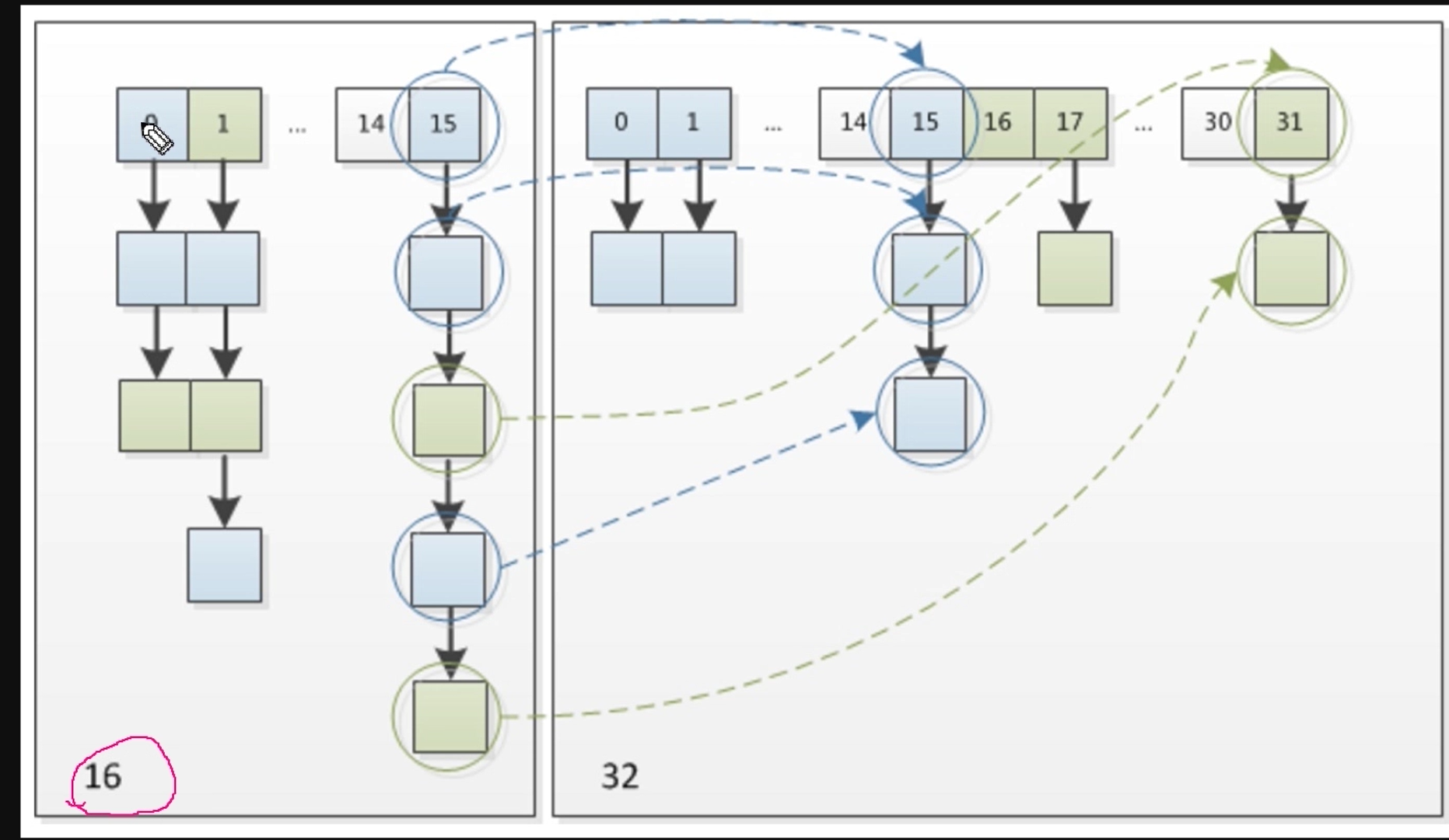
12.resize()扩容方法
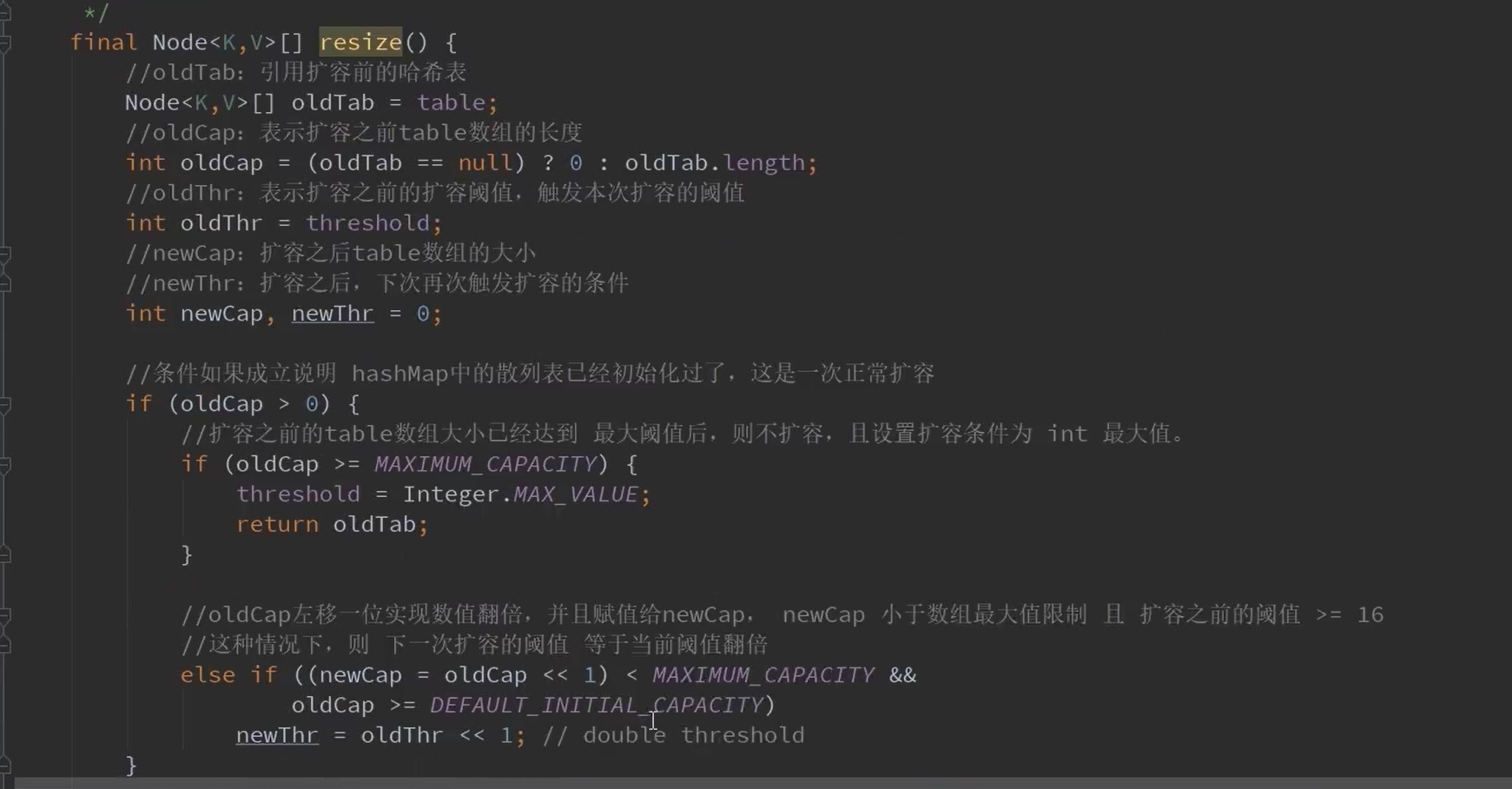
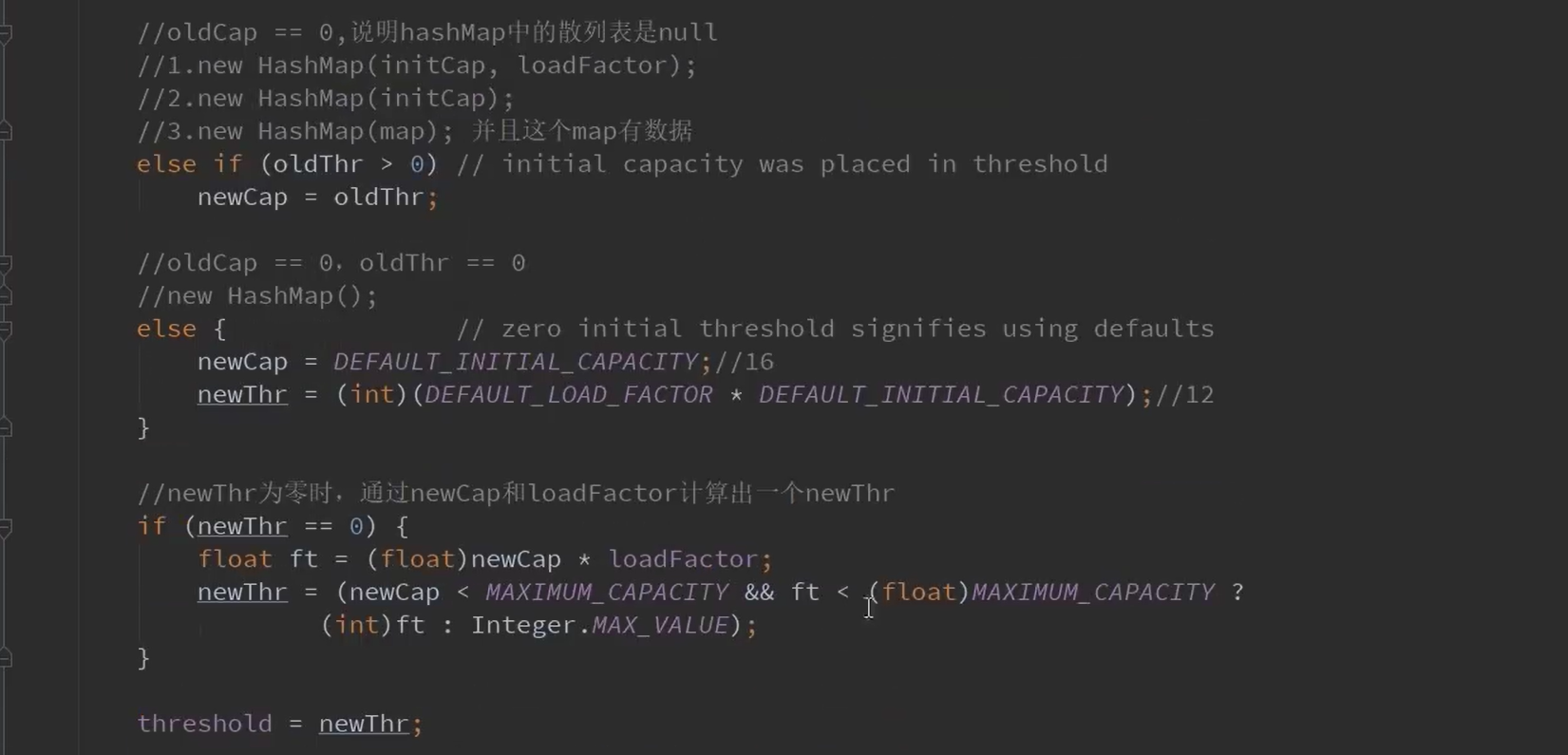
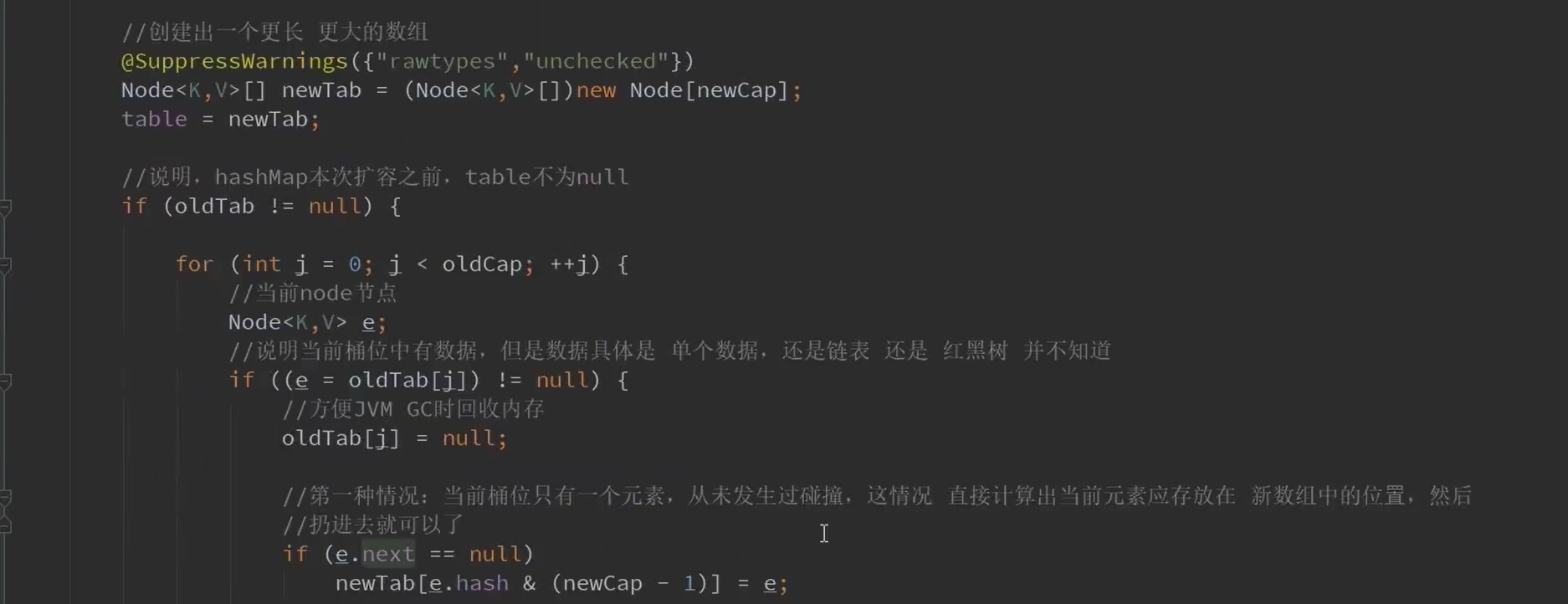
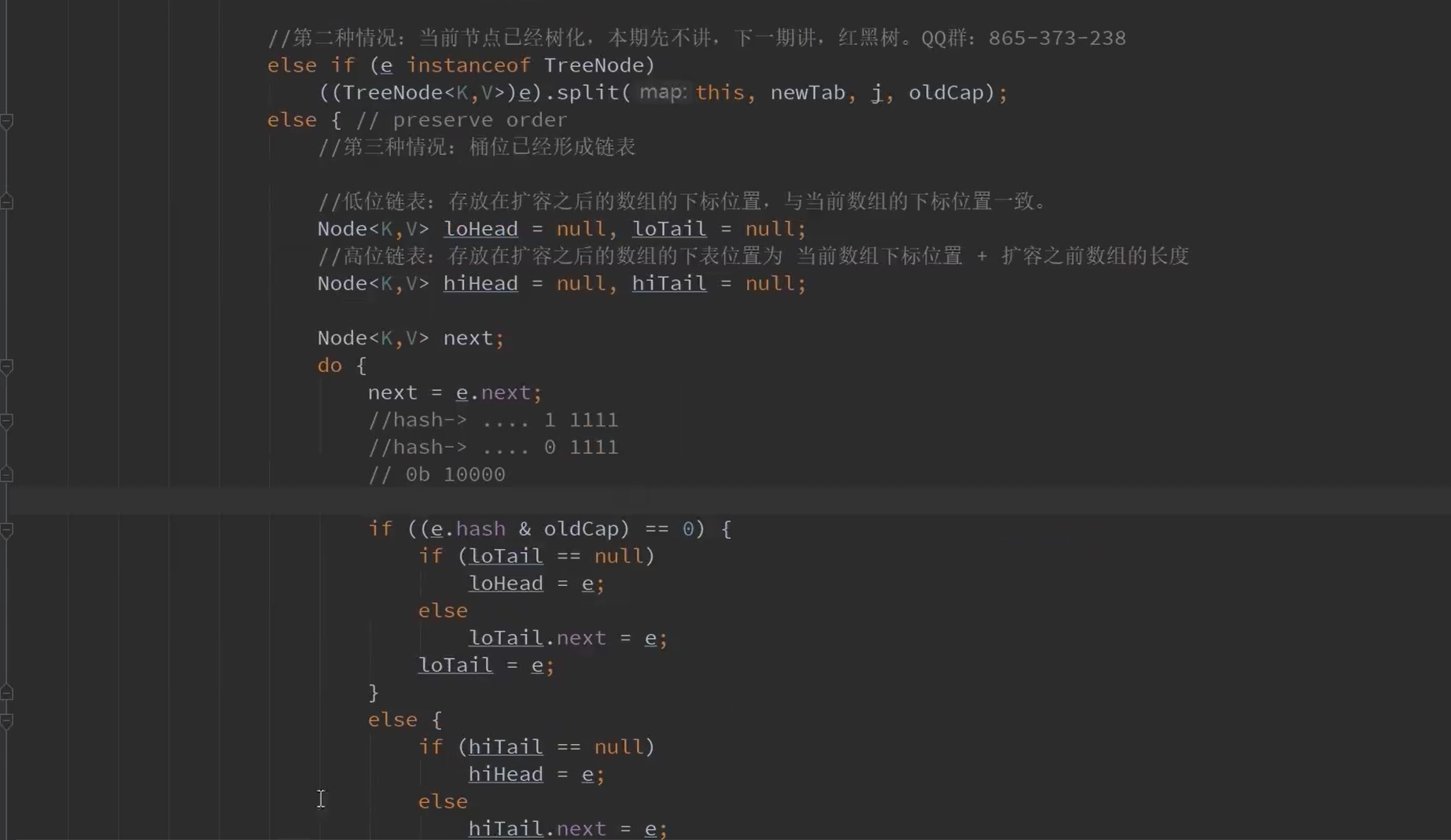
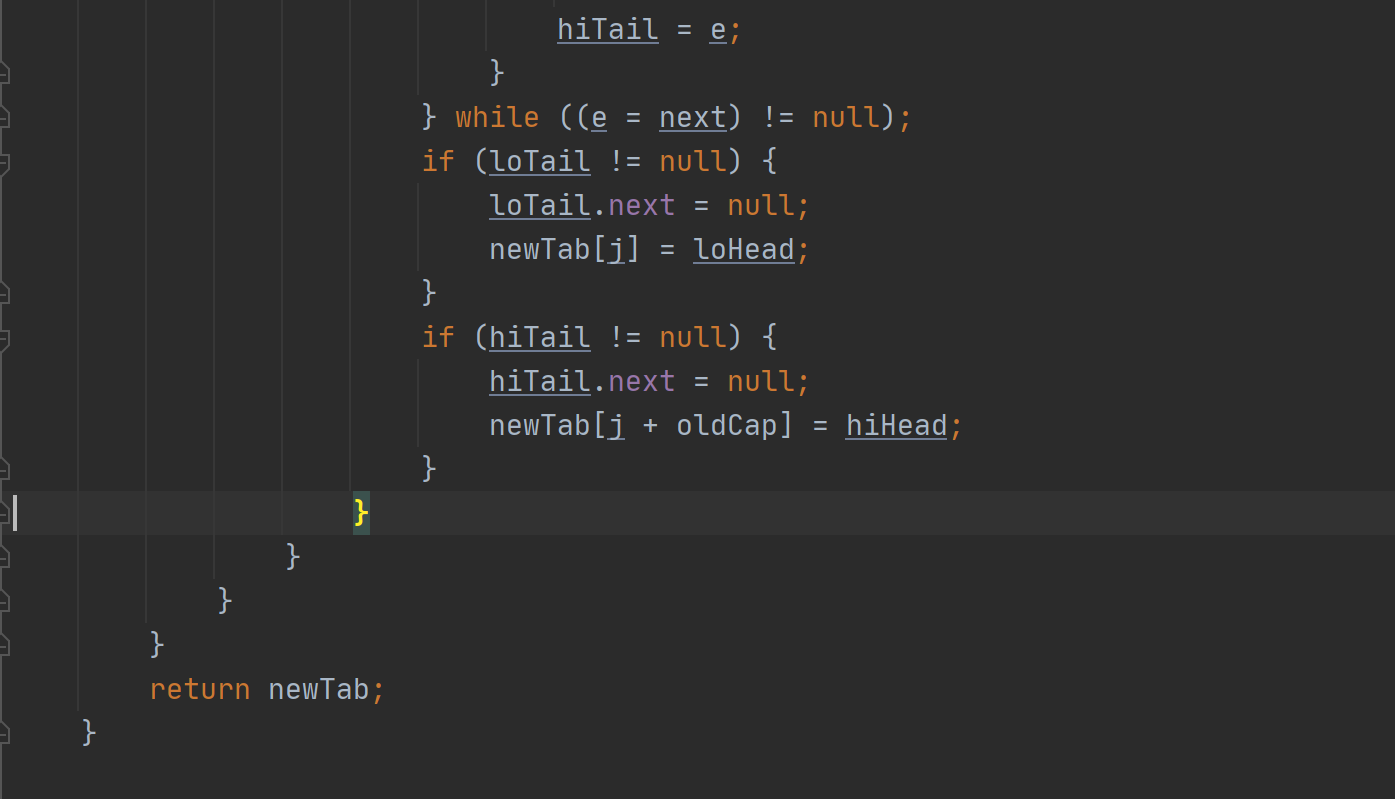
以上是讲解般的resize方法
我感觉有一点很重要,就是如何判断一个链表里面的结点是还属于这个桶的还是新扩容出来的桶的。
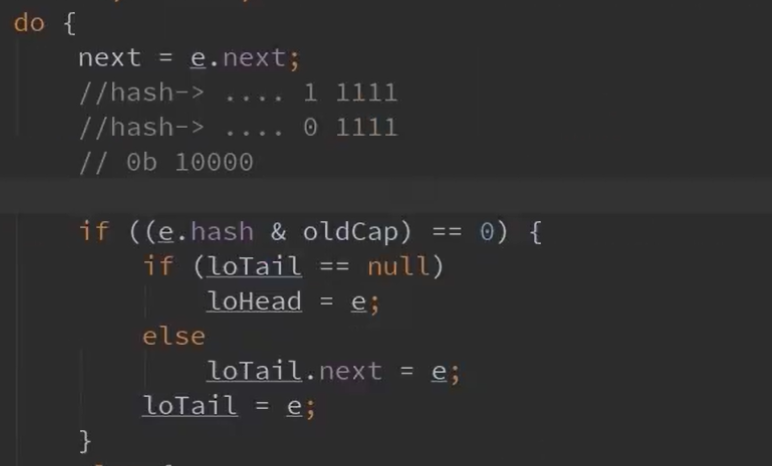
我们知道新桶的容量肯定是2的倍数。
oldCap肯定是 100000这样的形式的。
在11点我们将的寻址算法那里,也就是说key的hash值的 第n位(n为 oldCap为1的那位)决定了在旧桶还是在新桶。
例子:
0001 1111 hash
0000 1111 (oldCap-1的二进制形式)
=
0000 1111在容量为16的桶的第16位(table[15])
在扩容时计算新桶时
0001 1111 hash
0001 0000 oldCap的二进制
=
0001 0000 !=0 因为其不等于0 说明属于新桶的。
13.concurrentHashMap
构造方法
无参构造方法 无参构造不会进行初始化 在第一次put时才初始化 16个大小

有参构造
1.7 传参大小为32 数组就为32
1.8 传参大小为32 数组为64(最靠近 32+16+1 的二次幂)


CAS自旋检查sizeCtl是否为当前值。是当前值则置为-1(sizeCtl=-1表示正在初始化)

<< >>以及<<<的区别
<<表示左移移,不分正负数,低位补0;
>>表示右移,如果该数为正,则高位补0,若为负数,则高位补1;
>>>表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0
sizeCtl

如下图例子 碰到在初始化 或者扩容 则进行让出cpu。

hash扰动算法。最后得到肯定是正的,因为hash_bits是一个首位为0(代表正数)的16进制数


13.cunrrentHashMap的版本变化
JDK8之前:使用segment实现“分段锁”。结构和JDK8之前的红黑树一样(链表+数组)

JDK8:将数组的每个元素分配一把锁。
put()方法(不允许空键 空值)
