本次作业主要由以下内容构成
• (1)JML语言理论基础、应用工具链
• (2)SMT Solver
• (3)JMLUnitNG/JMLUnit
针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
• (4)架构设计梳理以及重构
• (5)作业bug和修复
• (6)规格撰写体会
一、JML语言理论基础和工具链
JML注释结构.
JML有两种注释结构,一种是 //@ 另一种是 /*@ @ @*/ 类型。两种注释结构是完全等价的。但是在实际操作中发现IntelliJ的插件只支持//@注释结构。
一个简单的JML规格应该由几部分构成:
normal_behavior(表示正常情况下的JML)
...
also
expcetional_behavior(表示异常处理部分的JML)
分别介绍在正常和异常两种场景下的结构。
正常场景:
- 前置条件 : requires + 逻辑表达式(真) 要求调用者必须满足的条件。
- 后置条件:ensures + 逻辑表达式(真) 要求该方法调用后必须满足的条件。
- 负作用范围 : 通常使用assignable + 变量名 表示允许在方法中修改的类成员变量。
异常场景:
三个条件和正常场景相同,区别在于,异常场景往往伴随着 signals (异常) 逻辑表达 来要求某种情况下必须抛出的异常。
JML语言中的常用语法(转义字符)
- esult 表示方法的返回值,old 表示方法调用前的某个变量
- forall 和 exist 通常和遍历语法一起使用,如 (forall int i;i<a.length; a[i]>0) 表示数组a[]中的每个元素都必须大于3.
- ==>, <==> 表示命题的逻辑关系,如推出和等价等,便于规格更方便的描述集合。
有了以上的语言规格就可以写出一些基本的方法规格,并且进行形式化的验证。
举例说明,下述规格表示集合对称差的方法规格,其中正常情况下的规格三要素都具有了,异常情景下只有抛出异常的规格要求。
1 /*@ public normal_behavior 2 @ requires this.size()>0 && a.size()>0; 3 @ assignable othing 4 @ ensures (forall int i; i<a.size(); !this.isIn(a.ia[i]))==> 5 (exist int i;i< esult.length; esult[i] == a.ia[i]); 6 @ ensures (forall int i; i<this.size(); !a.isIn(ia[i]))==> 7 (exist int i;i< esult.length; esult[i] == ia[i]); 8 @ ensures (forall int i; i < esult.length; 9 (a.isIn( esult[i])&&!isIn( esult[i]))||(!a.isIn( esult[]i)&&isIn( esult[i]))); 10 @ exceptional_behavior 11 @ signals (NullPointerException e) this.size() <= 0 12 @ signals (NullPointerException e) a.size()<=0 13 @ */
JML 工具链
OpenJML 在IntelliJ中安装openJML插件,可以调用SMT solver 理论上可以进行规格的检查(但是实际应用过程中发现bug诸多,故作业伊始便没有走形式验证,直接弃用)
JMLUnit 在IntelliJ中配置相应jar包,自动生成测试样例测试规格的正确性。
二、SMT Solver
在openJML 的插件中具有SMT-Solver 在各个环境(Mac,Linux,Windows) 的执行文件,但是都不work。
三、JMLUnitNG/JMLUnit
openJML 测试
Jmluniting 的使用参数说明 (来源:http://insttech.secretninjaformalmethods.org/software/jmlunitng/usage.html)
命令行选项 调用JMLUnitNG,因为java -jar jmlunitng.jar [OPTIONS] path-listwhere path-list是一个以空格分隔的文件系统路径列表(到文件或目录),[OPTIONS]是0或更多以下命令行选项。除了JMLUnitNG生成的那些之外,递归地指定路径中的所有Java文件都根据命令行选项进行处理。 -d, --dest [DIRECTORY]: DIRECTORY用作生成的类的输出目录。如果未指定,则在与测试的类相同的目录中生成测试类。 -cp , --classpath:javac在解析过程中使用给定的目录列表和Jar文件(格式为 )作为类路径。默认情况下,使用CLASSPATH环境变量。 -sp , --specspath:javac在解析过程中使用给定的目录列表和Jar文件(格式为 )作为specspath。默认情况下,使用SPECSPATH环境变量。 --rac-version:为指定的JML RAC版本生成RAC处理代码。openjml对于OpenJML RAC ,默认值为' '。对于JML2和JML4 RAC(分别),其他支持的值是' jml2'和' jml4'。 --deprecation:为不推荐使用的方法生成测试。使用@DeprecatedJava注释检测不推荐使用的方法(而不是在当前版本的JMLUnitNG中,通过 @deprecatedJavadoc标记)。默认情况下,此选项处于禁用状态,这意味着不会测试弃用的方法。 --inherited:为继承的方法生成测试。默认情况下,此选项处于禁用状态,这意味着不会为其主体从父类继承的方法生成测试。打开它会导致为每个被测试的类中的所有(具体)方法生成测试。 --public:仅为公共方法生成测试。这是JMLUnitNG的默认行为。 --protected :为受保护和公共方法生成测试。 --package :生成包(无保护修饰符),受保护和公共方法的测试。 --parallel:生成默认为并行运行的数据提供程序。默认情况下,此选项处于关闭状态,这意味着相同方法的多个测试将按顺序运行(无论您的TestNG设置如何); 打开它可以使它们与适当的TestNG设置并行运行。 --reflection:反射生成测试数据。默认情况下,此选项处于关闭状态,这意味着不会自动生成调用测试方法的对象; 打开它会导致生成这样的对象。 --children:对于所有参数,不仅使用参数类而且还使用在生成测试时探索的该类的任何子级生成测试数据。这允许许多方法自动测试接口/抽象类参数。 --literals :使用类和方法中的文字作为默认数据值来测试这些类和方法(在方法之外找到的文字,例如在静态字段中,用于所有方法)。 --spec-literals :使用类和方法规范中的文字作为默认数据值来测试这些类和方法(类规范中的文字用于所有方法)。 --clean:从目标路径中删除所有旧的JMLUnitNG生成的文件,包括任何手动修改。如果未设置目标路径,path-list则清除所有文件和目录。应谨慎使用此选项,因为它会在目标路径中以递归方式删除所有 JMLUnitNG生成的文件,或者 path-list无论何时/如何生成它们。 --no-gen:不要生成测试。此选项通常与不需要的JMLUnitNG生成的文件一起使用 --clean或--prune删除,而不会生成新的文件。 --dry-run:显示有关将执行但不修改文件系统的操作的状态/进度信息。当与任何其他选项集一起使用时,--dry-run使JMLUnitNG运行整个测试生成过程并显示步骤,但不生成输出; 它看到的文件将与被删除是有用的--clean或--prune,或者用什么方法将有选项特定集合为它们生成的测试。 -v, --verbose :显示状态/进度信息。 -h, --help :显示带有缩写文档的命令行选项列表
jmlunitNG的典型用法
1 通过java -jar jmlunitng.jar使用适当的命令行选项运行JMLUnitNG()来生成测试类。 2 (可选)修改测试数据生成策略以添加自定义测试数据(有关生成的文件本身的信息,请参阅下文)。如果不更改测试数据生成策略,它们将使用默认数据。基本类型数据默认值与JMLUnit相同(例如,-1 / 0/1 int); 3 使用常规Java编译器编译生成的类,使用适当的JML运行时Jar和JMLUnitNG Jar CLASSPATH。如果使用的是OpenJML RAC,则只需要JMLUnitNG Jar CLASSPATH,因为JMLUnitNG Jar包含OpenJML。 4 运行测试。这可以通过编写一个 testng.xml文件来运行所有测试,通过从命令行单独运行测试类(每个测试类都有一个main方法),或者从命令行运行TestNG并将其指向测试类来完成。
本着重在探索和体验的想法,使用jmluniting测试MyPath类中不含有exists或forall规格的方法,getNode方法和size()方法:
在Demo中实现这两个方法的检验
public class Demo {
public ArrayList<Integer> nodes = new ArrayList<>();
// @ public normal_behaviour
// @ ensures
esult = nodes.size();
public /*@pure@*/ int size(){
return nodes.size();
}
// @ public normal_behaviour
// @ requires index >= 0 && index < size();
// @ assignable
othing;
// @ ensures
esult == nodes.get(index);
public /*@pure@*/ int getNode(int index) {
if (index < 0 || index >= size()) {
return -1;
}
return nodes.get(index);//[index];
}
public static void main(String[] args) {
Demo d = new Demo();
d.nodes.add(1);
d.nodes.add(2);
int x = d.size();
System.out.println(x);
int y = d.getNode(1);
}
}
1.首先使用 jmlunitng 生成测试文件

2.使用openJML自带的SMT-Solver 执行编译 源文件Demo.java
3.然后编译该测试文件,对这两个方法进行测试
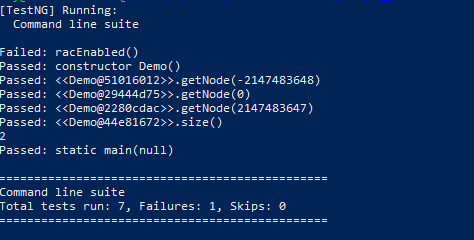
可以看出测试getNode()的时候自动生成的数据为0,正负MAX_Integer等几个特殊的样例。
测试size()则之际使用了主类中的结果进行了验证,并且这些验证都可以通过。
四、架构设计梳理以及重构
在第一次作业中由于思维定势,受规格数据结构的约束,没有使用效率比较高的HashMap,而是使用了ArrayList,所以导致强测有个别点超时。所以在第二次作业,使用HashMap后,MyPath类就不需要修改了。第二次作业吸取了之前重构的经验,首先保证效率上是高效的,其次把存储部分封装成一张图,内置各种方法,在第三次作业时只需要将图类重新设置边权并且实例化多个类即可,充分的实现了代码复用。
具体设计:
第一次作业
MyPath 使用了arrayList,根据最简单实现原则, 各个统计都是简单实现的。
MyPathContainer 同样根据最简实现原则,直接统计相应信息。
1 private static int id = 1; 2 private ArrayList<Path> paList = new ArrayList<>(); 3 private ArrayList<Integer> pidList = new ArrayList<>(); 4 private HashMap<Integer,Integer> disNodes = new HashMap<>();
第二次作业
MyPath 类中使用三个HashMap,disNode是节点在图中出现的次数,path2Id是路径到其Id的映射而id2Path,则是通过id 找到该路径的引用。每次添加/删除一条新路径的时候,在相应的HashMap 上做修改。
MyGraph 类中,根据图同一时刻不会超过120个点的性质,设置HashMap,将节点的ID映射到0-300.由于增删路径(图结构变动指令)较少,所以每次增删路径只需要重新构图。然后计算出相应的最短路即可。将isEdge,isConnected,getShortestPathLength三个需求统一到一个本质的数据结构上,dist[][],如果dist[x][y]=1,则x,y,之间有一条边,如果dist[x][y]!=-1 则x y相连,同样的dist[x][y] 表示x到y的最短路径。
//@ public instance model non_null Path[] paList; //@ public instance model non_null int[] id2Path; private final int anInt = 300; private static int id = 1; // 这是为Graph类提供支持的 private int nodeNum; private NextList next = new NextList(); //private NextList next = new NextList(); private int[][] dist = new int[anInt][anInt]; private HashMap<Integer, Integer> nodeHash = new HashMap<>(); //private HashMap<Integer, Integer> nodeTime = new HashMap<>(); //本类所需变量 private HashMap<Integer, Path> id2Path = new HashMap<>(); private HashMap<Integer, Integer> disNodes = new HashMap<>(); private HashMap<Path, Integer> path2Id = new HashMap<>();
第三次作业
第三次作业针对换乘问题,认为不同路径上的相同点作为不同的节点,所以新的HashMap 为(pathId,nodeId)->(newNodeId) ,由于路径数目不会超过50,所以总节点不会超过80*50 = 4000. 但是4000*4000 的矩阵还是太浪费空间,所以需要根据节点本身进行压缩存储,即dist[|nodeID|][|nodeID|] 大小的数组即可。
最原始的构图代码如下:
// 构建 四种 图 //(1) 构建普通长度的图 // 普通长度的图中,不需使用分身节点,只需要普通节点边权是1即可完成. // 所以在这里面一律使用真名id(像第10次作业一样) lenGraph.add(x, y, 1); lenGraph.add(y, x, 1); //(2) 构建换乘的图 node1 = new NodeClass(path.getNode(i - 1), pathId); node2 = new NodeClass(pathNode, pathId); x = nodeHash.get(node1); y = nodeHash.get(node2); transGraph.add(x, y, 0); transGraph.add(y, x, 0); //(3) 构建票价的图 ticketGraph.add(x, y, 1); ticketGraph.add(y, x, 1); //(4) 构建肥宅快乐图 int up1 = path.getUnpleasantValue(path.getNode(i - 1)); int up2 = path.getUnpleasantValue(pathNode); int weight = Math.max(up1, up2); pleasantGraph.add(x, y, weight); pleasantGraph.add(y, x, weight);
建图时,首先设置同一线路上的边权值,路径长度1,换乘次数0,不满意度H(x,y),票价1.
然后设置(pathId_i,nodeId) 相同节点在不同路径上 构成的新节点之间的边权。
路径长度0,换乘次数1,不满意度32,票价2.
在求最短路径,最少换成次数,最小不满意度,最小票价时只需要使用最短路算法的结果即可。
下面为第三次作业使用的数据结构,GraphInstance为自己构建的类
1 private static int id = 1; 2 private int nodeNum; 3 private HashMap<NodeClass, Integer> nodeHash = new HashMap(); 4 private HashMap<Integer, ArrayList<NodeClass>> hashNode = new HashMap(); 5 private HashMap<Integer, Integer> nodeSet = new HashMap(); 6 private GraphInstance lenGraph; 7 private GraphInstance ticketGraph; 8 private GraphInstance pleasantGraph; 9 private GraphInstance transGraph; 10 private boolean[][] edgeMatrix; 11 private HashMap<Integer, Path> id2Path; 12 private HashMap<Integer, Integer> disNodes; 13 private HashMap<Path, Integer> path2Id;
五、作业bug和修复
三次作业commit历史截图如下
第一次作业(1)在path类中路径比较函数中的Compare类中没有考虑两个路径长度不相等的情况,进行了修复。(2)在统计图的不同节点数时采用了N^2的暴力算法, 修复至O(N) (不算bug最后仍然超时TAT)
第二次作业(1)修复了自环的bug,如果路径1->1->1->2 则[1,1]isConnect is true.[2,2] isConnect is false. (2) 1->1 的最短路径是0,即使1->1->2 [1,1] 有自环 (3) 对路径中重复的节点进行了优化(不算bug)
第三次作业(1)修复了数组开小了的bug,最短路算法执行的最短距离数组至少要开|(pathId,nodeId)|,而不是|nodeId| 大小。
六、规格撰写体会
撰写规格的体会,在撰写规格时好处是能够以一种形式化的语言描述方法的功能要求和副作用,比较方便进行测试。在上课的时候讲,规格能够提供给编程者以程序化的思维,但是就本单元作业来看,规格提供的作用更多的是厘清指导书中没有说明的问题。更适合作为指导书的一个补充,如果只看规格,虽然能比较清楚类的作用,但是太繁琐的规格会导致程序员不好理解,同时为了理解规格,可能需要写很多无用的函数来进行补充规格。所以在写规格的时候也应考虑到,规格不仅是一种形式化的验证,更是一种约人沟通的语言,必须保持清晰、简短、有力的特点。