粒子群优化算法
粒子群优化(PSO, particle swarm optimization)算法是计算智能领域,除了蚁群算法,鱼群算法之外的一种群体智能的优化算法,该算法最早由Kennedy和Eberhart在1995年提出的,该算法源自对鸟类捕食问题的研究。 粒子群算法通过设计一种无质量的粒子来模拟鸟群中的鸟,粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子在搜索空间中单独的搜寻最优解,并将其记为当前个体极值,并将个体极值与整个粒子群里的其他粒子共享,找到最优的那个个体极值作为整个粒子群的当前全局最优解,粒子群中的所有粒子根据自己找到的当前个体极值和整个粒子群共享的当前全局最优解来调整自己的速度和位置。
PSO算法流程:
- PSO算法首先在可行解空间中初始化一群粒子,每个粒子都代表极值优化问题的一个潜在最优解,用位置、速度和适应度值三项指标表示该粒子特征。
- 粒子在解空间中运动,通过跟踪个体极值Pbest和群体极值Gbest更新个体位置,个体极值Pbest是指个体所经历位置中计算得到的适应度值最优位置,群体极值Gbest是指种群中的所有粒子搜索到的适应度最优位置。
- 粒子每更新一次位置,就计算一次适应度值,并且通过比较新粒子的适应度值和个体极值、群体极值的适应度值更新个体极值Pbest和群体极值Gbest位置。

在每一次迭代过程中,粒子通过个体极值和群体极值更新自身的速度和位置
更新公式
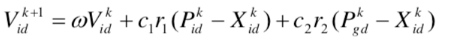
matlab代码:

防止陷入局部最优:

随机产生的数大于0.98(这个概率是很小的,仅有2%)修改这个数的值,这步是为了增加种群的丰富度,可以在迭代趋于平缓时,再次寻找到更优秀的点,跳出局部最优
参数比对:
加速因子与惯性权重的关系
c1 -->加速因子 (相信自己),初期大家都是懵懂,所以可以设置的大一些,后期社会规则建立完善,更多的要相信社会,所以后期c2值增大,c1减小
c2 -->加速因子 (相信社会)
w -->惯性权重 粒子移动速度,初期高可以快速移动,使得粒子四处移动,后期不能太高,否则会造成粒子在最优值附近来回震动
进行修改这三者参数,进行以10次为一周期的测试,取10次结果的平均值记录(因为存在rand函数,会有随机性,所以要取平均值)
function 1:
c1 = 1.49445;%加速因子---->0.1
c2 = 1.49445;------>2
w=0.8 %惯性权重------>0.2
最优适应度 达到最优适应度的迭代次数
0.000000 95
0.000000 510
0.000000 200
0.000000 490
... ...
... ...
... ...
c1会随着迭代次数慢慢减小到0.1,c2会随着迭代次数慢慢增大到2,w会随着迭代次数慢慢减小到0.2
达到最优适应度的迭代次数的平均值为320次,我是使用线性的修改参数方式,即c1、c2、w都是随着迭代次数进行递增或递减,可见过分缩小c1或过多增加c2都会造成迭代次数的增加,更难达到最有适应度。
w的值初始的时候大一些反而更方便找到最有适应度,但是越往后则是越小越能更快接近最有适应度
c1 = 2;%加速因子---->1
c2 = 1;------>2
w=0.8 %惯性权重------>0.2
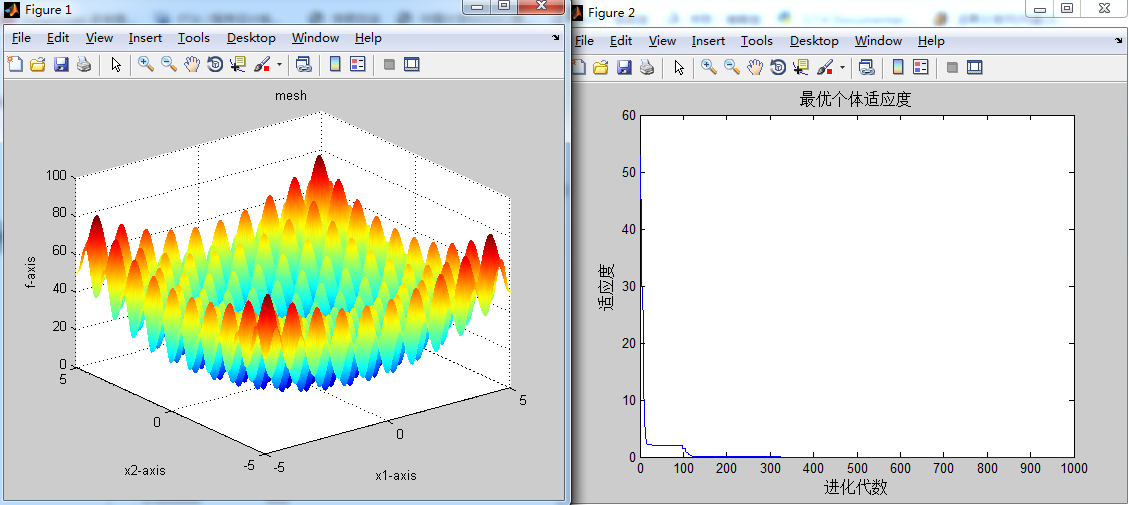
最优适应度 迭代次数达到最优
0.994959 590
0.000000 180
0.000000 710
0.000000 460
... ...
... ...
... ...
c1会随着迭代次数慢慢减小到0.1,c2会随着迭代次数慢慢增大到2,w会随着迭代次数慢慢减小到0.2
测试10次后取平均值:在经过495达到最优适应度,由于初始的c1设置的过大,过分的相信自己,而忽略了社会规则,则会导致需要迭代很久才能找到最有适应度,所以c1的初始值不应过大
c1 = 1.49445;%加速因子---->0.1
c2 = 1.49445;------>2
w=0.2 %惯性权重------>0.8
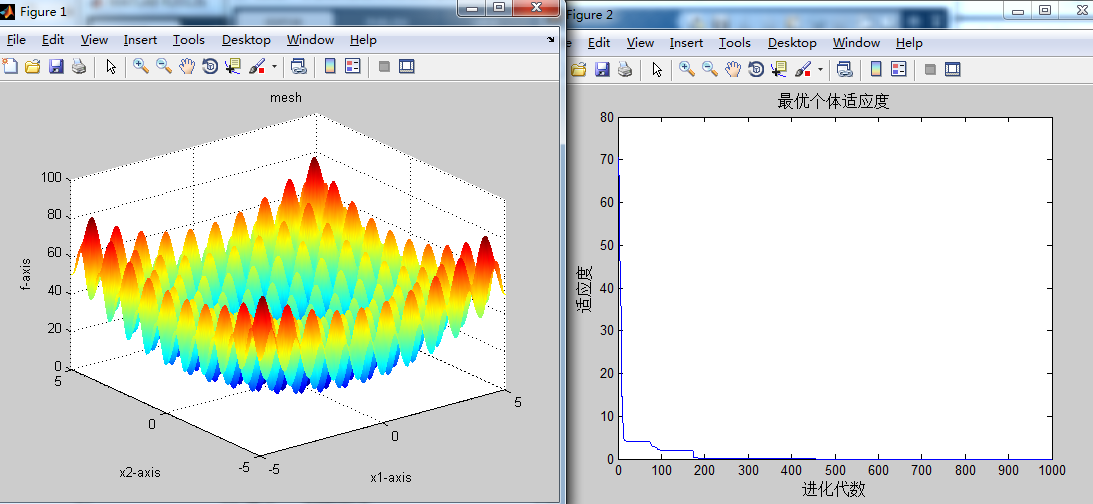
最优适应度 迭代次数达到最优
0.994959 100
0.000000 10
0.000000 50
0.000000 80
... ...
... ...
... ...
迭代了70次左右就能达到最有适应度,与第一组进行对比,区别在于将w--->惯性权重的值设置成由0.2慢慢增长至0.8,由小到大,虽然迭代次数减少了不少,但是波动明显更大了。
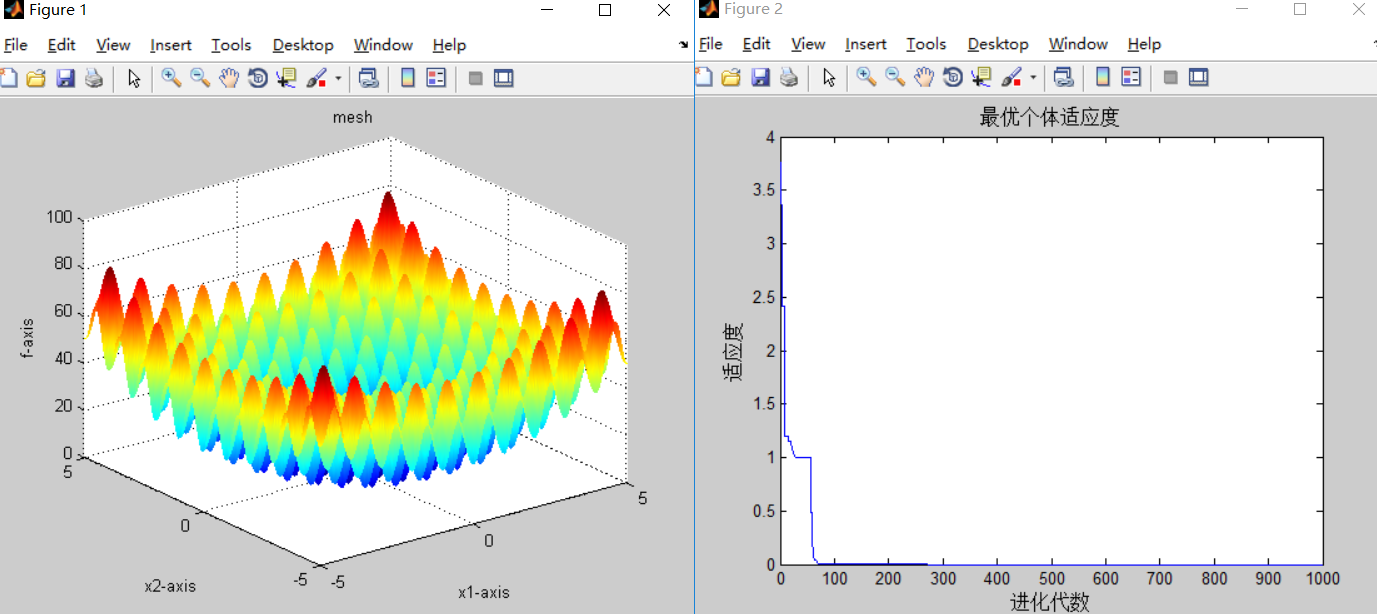
同样对比第一组,仅仅修改种群规模,将sizepop--->种群规模增加至800

最优适应度 迭代次数达到最优
0.000000 200
0.000000 4
0.000000 80
0.000000 120
... ...
... ...
... ...
经过110次左右的迭代能达到最优适应度,虽然迭代次数减少了一些,但是迭代时间大大增加,明显需要等待才能得到结果,所以适量增加种群数量能少量减少迭代次数,但是代价是运行的时间成本
同理,将sizepop缩小,则迭代时间减小,但是迭代次数又上去了。
dim--->适应度函数维数减小,运行时间并不会收到太大影响,但是找到最优值的迭代次数会有所减少
fuction 2:
c1 = 1.49445;%加速因子---->0.1
c2 = 1.49445;------>2
w=0.8 %惯性权重------>0.2

最优适应度 迭代次数达到最优
-1.000000 10
-1.000000 18
-1.000000 7
-1.000000 5
... ...
... ...
... ...
c1会随着迭代次数慢慢减小到0.1,c2会随着迭代次数慢慢增大到2,w会随着迭代次数慢慢减小到0.2,平均迭代次数:12
c1 = 2;%加速因子---->1
c2 = 1;------>2
w=0.8 %惯性权重------>0.2
最优适应度 迭代次数达到最优
-1.000000 10
-1.000000 5
-1.000000 3
-1.000000 8
... ...
... ...
... ...
c1会随着迭代次数慢慢减小到1,c2会随着迭代次数慢慢增大到2,w会随着迭代次数慢慢减小到0.2,平均迭代次数:7
fuction 3:
c1 = 1.49445;%加速因子---->0.1
c2 = 1.49445;------>1.9
w=0.8 %惯性权重------>0.2
最优适应度 迭代次数达到最优
0.000000 5
0.000000 8
0.000000 10
0.000000 20
... ...
... ...
... ...
c1会随着迭代次数慢慢减小到0.1,c2会随着迭代次数慢慢增大到2,w会随着迭代次数慢慢减小到0.2,平均迭代次数:9
c1 = 2;%加速因子---->1
c2 = 1;------>2
w=0.8 %惯性权重------>0.2
最优适应度 迭代次数达到最优
0.000000 5
0.000000 6
0.000000 9
0.000000 12
... ...
... ...
... ...
c1会随着迭代次数慢慢减小到1,c2会随着迭代次数慢慢增大到2,w会随着迭代次数慢慢减小到0.2,平均迭代次数:7
粒子群算法的寻优算法总结:
1. 
设定速度的上下限,因为:
- 过大速度会导致最优解被越过
- 过小速度会导致求解速度过慢
2.sizepop-->种群规模的取值范围可以适当的少一些,PSO算法对种群大小不敏感。
3.w--->惯性权重的取值范围可以设置为0.5~0.8,这个参数是反映个体历史成绩对现有成绩的影响,初始的时候应当大一些,方便粒子快速移动,后续则应慢慢降低,否则会导致粒子一直在最优适应度附近震动
4.初始的c1值不应该过大,而c2的值则应该大一些,越往后迭代,c1的值越要慢慢降低,c2的值越要慢慢增加,但是也不应过大过小,c1在1-1.5之间,c2在1.5-1.8之间即可。
5.PSO算法的计算速度非常快,全局搜索能力也很强,运行的速度远远快于GA和蚁群算法
6.POS算法虽然计算速度很快,但是容易陷入局部最优,因此添加一个变异种子很必要
matlab代码:
function Drawfunc(label)
x=-5:0.05:5;%41列的向量
if label==1
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Rastrigin([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==2
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Schaffer([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==3
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Griewank([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
function y = fun(x,label) %函数用于计算粒子适应度值 %x input 输入粒子 %y output 粒子适应度值 if label==1 y=Rastrigin(x); elseif label==2 y=Schaffer(x); else y= Griewank(x); end
function y = fun(x) %函数用于计算粒子适应度值 %x input 输入粒子 %y output 粒子适应度值 y=-20*exp(-0.2*sqrt((x(1)^2+x(2)^2)/2))-exp((cos(2*pi*x(1))+cos(2*pi*x(2)))/2)+20+exp(1); %y=x(1)^2-10*cos(2*pi*x(1))+10+x(2)^2-10*cos(2*pi*x(2))+10;
function y=Griewank(x) %Griewan函数 %输入x,给出相应的y值,在x=(0,0,…,0)处有全局极小点0. %编制人: %编制日期: [row,col]=size(x); if row>1 error('输入的参数错误'); end y1=1/4000*sum(x.^2); y2=1; for h=1:col y2=y2*cos(x(h)/sqrt(h)); end y=y1-y2+1; %y=-y;
%% 清空环境 clc clear %% 参数初始化 %粒子群算法中的三个参数 c1 = 1.49445;%加速因子 c2 = 1.49445; w=0.2 %惯性权重 maxgen=1000; % 进化次s数 sizepop=200; %种群规模 Vmax=1; %限制速度围 Vmin=-1; popmax=5; %变量取值范围 popmin=-5; dim=3; %适应度函数维数 func=1; %选择待优化的函数,1为Rastrigin,2为Schaffer,3为Griewank Drawfunc(func);%画出待优化的函数,只画出二维情况作为可视化输出 %% 产生初始粒子和速度 for i=1:sizepop %随机产生一个种群 pop(i,:)=popmax*rands(1,dim); %初始种群 V(i,:)=Vmax*rands(1,dim); %初始化速度 %计算适应度 fitness(i)=fun(pop(i,:),func); %粒子的适应度 end %% 个体极值和群体极值 [bestfitness bestindex]=min(fitness); gbest=pop(bestindex,:); %全局最佳 pbest=pop; %个体最佳 fitnesspbest=fitness; %个体最佳适应度值 fitnessgbest=bestfitness; %全局最佳适应度值 %% 迭代寻优 for i=1:maxgen fprintf('第%d代,',i); fprintf('最优适应度%f ',fitnessgbest); for j=1:sizepop %速度更新 V(j,:) = w*V(j,:) + c1*rand*(pbest(j,:) - pop(j,:)) + c2*rand*(gbest - pop(j,:)); %根据个体最优pbest和群体最优gbest计算下一时刻速度 V(j,find(V(j,:)>Vmax))=Vmax; %限制速度不能太大 V(j,find(V(j,:)<Vmin))=Vmin; %种群更新 pop(j,:)=pop(j,:)+0.5*V(j,:); %位置更新 pop(j,find(pop(j,:)>popmax))=popmax;%坐标不能超出范围 pop(j,find(pop(j,:)<popmin))=popmin; if rand>0.98 %加入变异种子,用于跳出局部最优值 pop(j,:)=rands(1,dim); end %更新第j个粒子的适应度值 fitness(j)=fun(pop(j,:),func); if c1>0.1 c1=c1-0.001 end if c2<2 c2=c2+0.001 end if w<0.8 w=w+0.0006 end end for j=1:sizepop %个体最优更新 if fitness(j) < fitnesspbest(j) pbest(j,:) = pop(j,:); fitnesspbest(j) = fitness(j); end %群体最优更新 if fitness(j) < fitnessgbest gbest = pop(j,:); fitnessgbest = fitness(j); end end yy(i)=fitnessgbest; end %% 结果分析 figure; plot(yy) title('最优个体适应度','fontsize',12); xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
%% 清空环境 clc clear %% 参数初始化 %粒子群算法中的两个参数 c1 = 1.49445; c2 = 1.49445; maxgen=500; % 进化次数 sizepop=100; %种群规模 Vmax=1; Vmin=-1; popmax=5; popmin=-5; %% 产生初始粒子和速度 for i=1:sizepop %随机产生一个种群 pop(i,:)=5*rands(1,2); %初始种群 V(i,:)=rands(1,2); %初始化速度 %计算适应度 fitness(i)=fun(pop(i,:)); %染色体的适应度 end %% 个体极值和群体极值 [bestfitness bestindex]=min(fitness); zbest=pop(bestindex,:); %全局最佳 gbest=pop; %个体最佳 fitnessgbest=fitness; %个体最佳适应度值 fitnesszbest=bestfitness; %全局最佳适应度值 %% 迭代寻优 for i=1:maxgen for j=1:sizepop %速度更新 V(j,:) = V(j,:) + c1*rand*(gbest(j,:) - pop(j,:)) + c2*rand*(zbest - pop(j,:)); V(j,find(V(j,:)>Vmax))=Vmax; V(j,find(V(j,:)<Vmin))=Vmin; %种群更新 pop(j,:)=pop(j,:)+0.5*V(j,:); pop(j,find(pop(j,:)>popmax))=popmax; pop(j,find(pop(j,:)<popmin))=popmin; if rand>0.98 pop(j,:)=rands(1,2); end %适应度值 fitness(j)=fun(pop(j,:)); end for j=1:sizepop %个体最优更新 if fitness(j) < fitnessgbest(j) gbest(j,:) = pop(j,:); fitnessgbest(j) = fitness(j); end %群体最优更新 if fitness(j) < fitnesszbest zbest = pop(j,:); fitnesszbest = fitness(j); end end yy(i)=fitnesszbest; end %% 结果分析 plot(yy) title('最优个体适应度','fontsize',12); xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
function y = Rastrigin(x) % Rastrigin函数 % 输入x,给出相应的y值,在x = ( 0 , 0 ,…, 0 )处有全局极小点0. % 编制人: % 编制日期: [row,col] = size(x); if row > 1 error( ' 输入的参数错误 ' ); end y =sum(x.^2-10*cos(2*pi*x)+10); %y =-y;
function y=Schaffer(x) [row,col]=size(x); if row>1 error('输入的参数错误'); end y1=x(1,1); y2=x(1,2); temp=y1^2+y2^2; y=0.5-(sin(sqrt(temp))^2-0.5)/(1+0.001*temp)^2; y=-y;