事实表设计
什么是事实表
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度
和与业务过程有关的度量。
事实表中一条记录所表达的业务细节程度被称为粒度。
通常粒度可以通过两种方式来表述:
- 一种是维度属性组合所表示的细节程度
- 一种是所表示的具体业务含义
作为度量业务过程的事实,一般为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型。
-
可加性事实指可以按照与事实表关联的任意维度进行汇总
-
半可加性事实只能按照特定维度汇总,不能对所有维度汇总
比如库存可以按照地点和商品进行汇总,而按时间维度把一年中每个月的库存累加起来则毫无意义
-
度量完全不具备可加性
比如比率型事实。对于不可加性事实可分解为可加的组件来实现聚集。
相对维表来说,通常事实表要细长得多,行的增加速度也比维表快很多。
维度属性也可以存储到事实表中,这种存储到事实表中的维度列被称为“退化维度”。与其他存储在维表中的维度一样,退化维度也可以用来进行事实表的过滤查询、实现聚合操作等。
事实表类型
事务事实表
事务事实表用来描述业务过程,跟踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为“原子事实表“
周期快照事实表
周期快照事实表以具有规律性的、可预见的时间间隔记录事实,时间间隔如每天、每月、每年等。
累计快照事实表
累积快照事实表用来表述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点, 当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。
事实表设计原则
原则1 :尽可能包含所有与业务过程相关的事实
事实表设计的目的是为了度量业务过程,所以分析哪些事实与业务过程有关是设计中非常重要的关注点。在事实表中应该尽量包含所有与
业务过程相关的事实,即使存在冗余,但是因为事实通常为数字型,带来的存储开销也不会很大。
原则2 :只选择与业务过程相关的事实
在选择事实时,应该注意只选择与业务过程有关的事实。比如在订单的下单这个业务过程的事实表设计中,不应该存在支付金额这个表示
支付业务过程的事实。
原则3 : 分解不可加性事实为可加的组件
对于不具备可加性条件的事实,需要分解为可加的组件。比如订单的优惠率,应该分解为订单原价金额与订单优惠金额两个事实存储在事
实表中。
原则4 :在选择维度和事实之前必须先声明粒度
粒度的声明是事实表设计中不可忽视的重要一步,粒度用于确定事实表中一行所表示业务的细节层次,决定了维度模型的扩展性,在选择
维度和事实之前必须先声明粒度,且每个维度和事实必须与所定义的粒度保持一致。
在设计事实表的过程中,粒度定义得越细越好,建议从最低级别的原子粒度开始,因为原子粒度提供了最大限度的灵活性,可以支持无法预期的各种细节层次的用户需求。
在事实表中,通常通过业务描述来表述粒度,但对于聚集性事实表的粒度描述,可采用维度或维度属性组合的方式。
原则5 : 在同一个事实表中不能有多种不同粒度的事实
事实表中的所有事实需要与表定义的粒度保持一致,在同一个事实表中不能有多种不同粒度的事实。
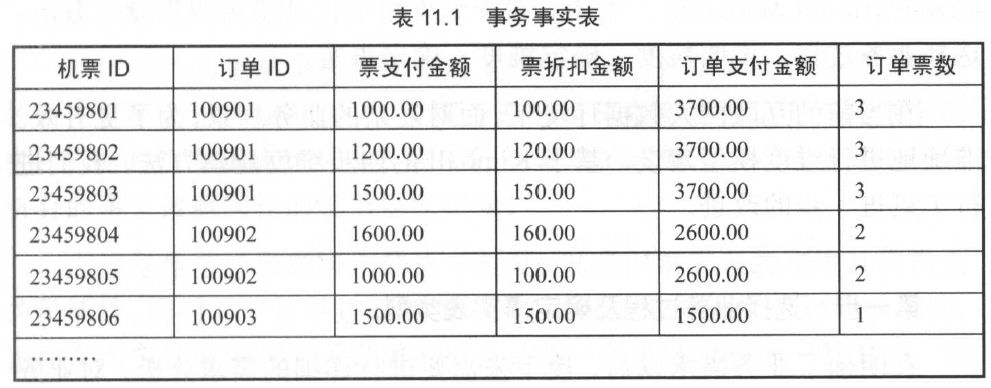
如上表所示为机票支付成功事务事实表,粒度为票一级的,而在实际业务中,一个订单可以同时支付多张票,如 ID 为100901 的订单包含三张机票, ID 为100902 的订单包含两张机票, ID 为100903 的订单包含一张机票。
在该事实表的设计中,票支付金额和票折扣金额两个事实与表定义的粒度一致,并且支持按表的任意维度汇总,可以添加进该事实表中。
而订单支付金额和订单票数作为上一层粒度的订单级事实,与该票级事实表的粒度不一致,且不能进行汇总。比如订单 ID 为100901 的订单支付金额为3700 元,订单票数为 3 张,如果这两个度量在该表进行汇总计算总订单金额和总票数,则会造成重复计算的问题,所以不能作为该表的度量选人。
原则6 :事实的单位要保持一致
对于同一个事实表中事实的单位,应该保持一致。比如原订单金额、订单优惠金额、订单运费金额这三个事实,应该采用一致的计量单位,统一为元或分,以方便使用。
原则7 : 对事实的 null 值要处理
对于事实表中事实度量为 null 值的处理,因为在数据库中 null 值对常用数字型字段的 SQL 过滤条件都不生效,比如大于、小于、等于、大于或等于、小于或等于,建议用零值填充。
原则8 :使用退化维度提高事实表的易用性
在 Kimball 的维度建模中,通常按照星形模型的方式来设计,对于维度的获取采用的是通过事实表的外键关联专门的维表的方式,谨慎使
用退化维度。
而在大数据领域的事实表设计中,则大量采用退化维度的方式,在事实表中存储各种类型的常用维度信息。这样设计的目的主要是为了减少下游用户使用时关联多个表的操作,直接通过退化维度实现对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等。通过增加冗余存储的方式减少计算开销,提高使用效率。
事实表设计方法
第一步: 选择业务过程及确定事实表类型
在明确了业务需求以后,接下来需要进行详细的需求分析,对业务的整个生命周期进行分析,明确关键的业务步骤,从而选择与需求有关
的业务过程。
以淘宝的正向订单流转为例:
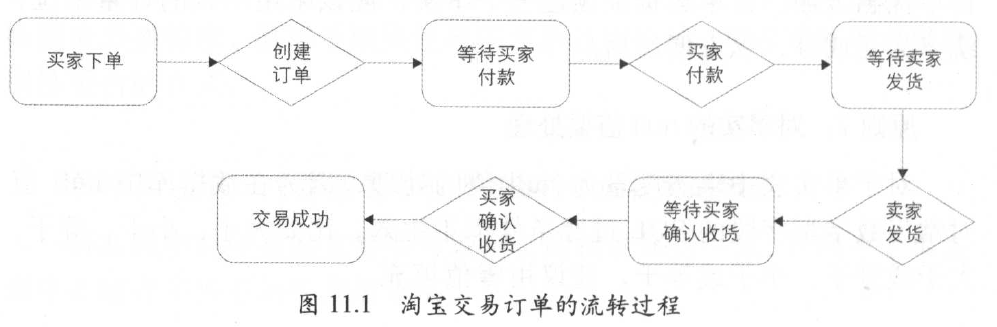
业务过程通常使用行为动词表示业务执行的活动。比如上图中的淘宝订单流转的业务过程有四个:创建订单、买家付款、卖家发货、买家确认收货。
在明确了流程所包含的业务过程后,需要根据具体的业务需求来选择与维度建模有关的业务过程。比如是选择买家付款这个业务过程,还是选择创建订单和买家付款这两个业务过程,具体根据业务情况来确定。
在选择了业务过程以后,相应的事实表类型也随之确定了。
比如选择买家付款这个业务过程,那么事实表应为只包含买家付款这一个业务过程的单事务事实表;如果选择的是所有四个业务过程,并且需要分析各个业务过程之间的时间间隔,那么所建立的事实表应为包含了所有四个业务过程的累积快照事实表。
第二步: 声明粒度
粒度的声明是事实表建模非常重要的一步,意味着精确定义事实表的每一行所表示的业务含义,粒度传递的是与事实表度量有关的细节层
次。明确的粒度能确保对事实表中行的意思的理解不会产生混淆,保证所有的事实按照同样的细节层次记录。
应该尽量选择最细级别的原子粒度,以确保事实表的应用具有最大的灵活性。同时对于订单过程而言,粒度可以被定义为最细的订单级别。
比如在淘宝订单中有父子订单的概念,即一个子订单对应一种商品,如果拍下了多种商品,则每种商品对应一个子订单:这些子订单一同结算的话,则会生成一个父订单。那么在这个例子中,事实表的粒度应该选择为子订单级别。
第三步: 确定粒度
完成粒度声明以后,也就意味着确定了主键,对应的维度组合以及相关的维度字段就可以确定了,应该选择能够描述清楚业务过程所处的
环境的维度信息。
比如在淘宝订单付款事务事实表中,粒度为子订单,相关的维度有买家、卖家、商品、收货人信息、业务类型、订单时间等维度。
第四步: 确定事实
事实可以通过回答“过程的度量是什么”来确定。应该选择与业务过程有关的所有事实,且事实的粒度要与所声明的事实表的粒度一致。事实有可加性、半可加性、非可加性三种类型, 需要将不可加性事实分解为可加的组件。
比如在淘宝订单付款事务事实表中,同粒度的事实有子订单分摊的支付金额、邮费、优惠金额等。
第五步: 冗余维度
在传统的维度建模的星形模型中,对维度的处理是需要单独存放在专门的维表中的,通过事实表的外键获取维度。这样做的目的是为了减
少事实表的维度冗余,从而减少存储消耗。
而在大数据的事实表模型设计中,考虑更多的是提高下游用户的使用效率,降低数据获取的复杂性,减少关联的表数量。所以通常事实表中会冗余方便下游用户使用的常用维度,以实现对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等操作。
比如在淘宝订单付款事务事实表中,通常会冗余大量的常用维度字段,以及商品类目、卖家店铺等维度信息。