感知器(PLA——Perceptron Learning Algorithm),也叫感知机,处理的是机器学习中的分类问题,通过学习得到感知器模型来对新实例进行预测,因此属于判别模型。感知器于1957年提出,是神经网络的基础。
模型
以最简单的二分类为例,假设医院需要根据肿瘤患者的病患特征(x1肿瘤大小,x2肿瘤颜色),判断肿瘤是良性(+1)还是恶性(-1),那么所有数据集都可以在一个二维空间表示;如果能找到一条直线将所有1和-1分开,这个数据集就是线性可分的,否则就是线性不可分。将两个特征向量分别用x1, x2表示,θ是权重,分隔直线的函数是:
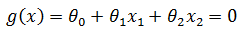
也许用初中的知识更容易说明,常见的直线函数:

感知器的假设函数(hypothesis function) hθ(x):
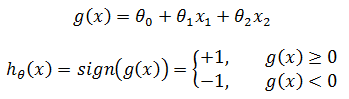

θ称为感知器的模型参数。需要注意的是,上图中左右两侧的g(x)不是直线,它们的x1和x2都是具体的特征值,是一个具体的实数数值;直线是g(x) = θ0 + θ1x1 + θ2x2 = 0,它的x1和x2才是变量。
我们需要做的就是根据训练集中的样本数据计算出恰当的θ,以使得直线f(x) 最终能够正确地分开数据集中的所有1和-1(对于线性不可分问题是找到最好的直线以划分尽可能多的1和-1)。
感知器也可以扩展到多维数据,比如判断肿瘤时除了大小和颜色外还有发病时间、以前是否有过类似肿瘤等。对于三维空间,最终将找到一个平面;对于更多维的空间,最终将找到一个超平面。超平面是一个概念,可以将多维数据的正负例一分为二,但很难在平面媒体中呈现。
现在,对于n维空间的一个样本,xn表示一个样本中的第n个特征向量,θn表示xn对应的权重,感知器的假设函数hθ(x):
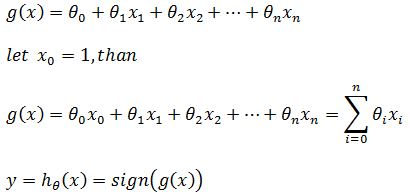
如果g(x)写成下面形式,则g(x)可以看作多维空间的“直线”:
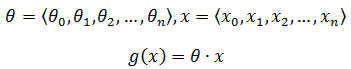
也可以写成矩阵的形式:

后续文章将混用这两种表达。
学习策略
我们的最终目标是找到最佳的θ,这就需要制定一个学习策略,即定义一个用来计算误分类的损失函数,使损失函数极小化,从而通过优化的手段求解θ。
现在设J(θ)是损失函数,第一感觉很自然会将误分类数量作为损失函数:
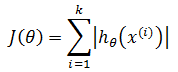
上式表示在样本集中对于特定的感知器参数,共有k个样本被误判,上标 i 表示误分类集中的第 i 个样本。然而这样做存在问题,该函数的结果可能是0,1,2,3……,是离散而非连续数据;因为J(θ)不是连续的,不连续的函数必定不可导,不可导的函数也不易优化,所以没有办法根据这样的J(θ) 制定算法。(关于导数和利用导数求极值的问题,可参考《单变量微积分》中的相关章节)。
下面的图片由其他网友提供,忘记了来源,它很形象地说明了连续和可导的关系:

现在需要将J(θ) 变成连续函数,以分类点到直线超平面的总距离作为损失函数,每个误分类点到超平面的距离是:

关于点到平面的距离可参考《线性代数笔记5——平面方程与矩阵》。
由于是误分类,所有正确结果是1的被判定为-1,-1的被判定为1,用y表示正确的分类结果(实际结果),可以用下面的方法将绝对值符号去掉:

损失函数也就是所有误分类点的总距离:
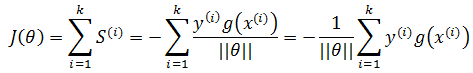
将上式中的S表示几何间隔,是点到平面距离。在感知机中,使用函数间隔(也就是去掉S的二阶范数)来近似地表示距离,从而简化问题:

损失函数是非负的,如果没有误分类点,损失函数为0;误分类点越少,误分类点离超平面越近,损失函数越小,J(θ) 是关于θ 的连续可导函数。
现在有一个问题,如下图所示:
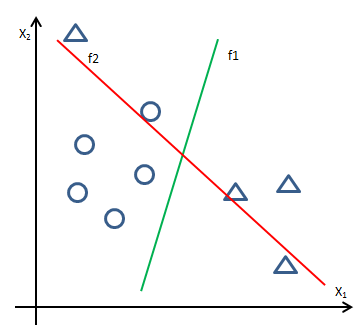
在两条分隔线中,f1分错了一个样本,f2分错了两个,f1的准确率高于f2,但是根据损失函数,f2的误分类点距离之和小于f1,这样算法就会判断f2是最终结果。为了应对这类问题,喂给模型的训练数据需要经过一定的过滤从而去掉其中的噪声,就想我们预测房价时需要过滤掉一些明显的内部价格。
算法
原始形式
现在感知器学习问题转换为求解损失函数的最优化问题,也就是在训练样本线性不可分的情况下,通过优化算法使得对于全体训练样本来说J(θ) 最小。
使用随机梯度下降法求解模型参数θ(梯度下降可参考《ML(附录1)——梯度下降》),选择一个误分类样本(x(j), y(j)),初始的θ可以全部设置为0:
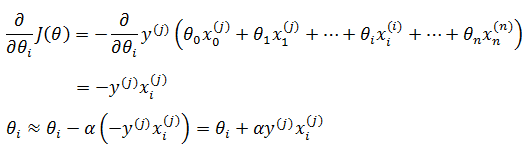
反复迭代,每次随机选取第j个样本,达到阈值或迭代一定次数后停止迭代。需要注意的是,每次迭代后都将产生新的模型,该模型会得到新的误分类集,新一轮迭代选取的样本都是从新的误分类集合中选取的。
对于任意θ,用矩阵的写法:
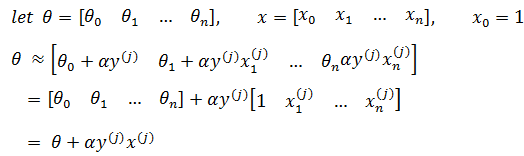
所以感知器的原始形态可化简为:
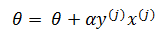
这种算法被称为感知器学习算法的原始形态,其基本思想是:当一个实例点被误分类,即位于分类超平面错误的一侧时,则调整θ,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。这种感知机学习算法得到的模型参数不是唯一的,它会由于采用不同的参数初始值或选取不同的误分类点,而导致解不同。
二分类训练集x中的每个样本都是n维向量,其分类结果是y = ±1,现在利用PLA训练数据,得到模型hθ(x) = sign(g(x)),原始形态的求解步骤如下:
1) 初始化α、θ,令θ是0向量
2) 利用hθ(x)从训练集x中选择误分类数据,形成误分类集errDatas
3) 从errDatas中随机选取一个误分类样本x(j),用该样本重新计算θ: θ = θ + αy(j)x(j)
4) 使用新θ,利用sign(hθ(x))检测是否还有误分类点,如果没有,计算结束,否则跳转到2;或判断是否达到指定阈值(或循环次数),如果是,计算结束,否则跳转到2
对偶形式
简单的理解,可以将感知器的对偶形态看作感知器的另一种学习算法,是对原始形态的优化。
在原始形态中:

我们每次都随机选取误分类集中的第j个样本进行θ的迭代。如果这个被选中的样本x(j)在原始训练集中的序号是i,那么对于每次迭代能够建立这样的映射:

i对应原始训练集的样本序号,j对误分类集的样本序号。需要注意的是,由于误分类集在每次迭代后都有所变化,但是误分类样本在原始训练集中的序号是不变的。比如对于原始集的样本x(5),i = 5,在其中一次迭代后被判做误分类,此时它是误分类集中的第4条数据,j = 4;在另一次迭代后仍然是误分类,此时变成了误分类集中第2条数据,j = 2;随后被分类正确,不在误分类集中。
由此我们看到,对于多次被误分类的原始集中的第i号样本(靠近分隔线的样本),设它被选中(因为使用随机梯度下降)参与迭代的次数是mi,对于一个从未被误分的样本(远离分隔线的样本),mi = 0。对于每次迭代,参与计算的原始集的x(i)对应的mi += 1。如果令θ是0向量,对于含有n个样本的训练集:
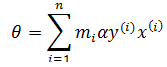
如果令βi = miα,则:
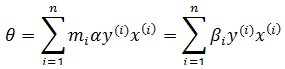
现在,在误分类集中对于第j个误分类的判断变成了:
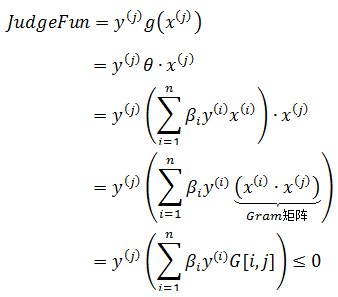
注意JudgeFun的点积,如果我们事先用矩阵运算计出所有的样本之间的点积,那么在算法运行时就可以直接得到结果,这就使算法节省了计算g(x)的时间,也是对偶形态的关键。样本的点积矩阵称为Gram矩阵,记作 G = [x(i)∙x(j)]。
为了便于理解,上式中j表示误分类集的第j个数据,i表示原始集的第i个数据。刚才我撒了谎,实际上Gram矩阵需要知道的是j在原始集中的位置k,即 G = [x(i)∙x(k)],这样才能有效缓存数据。
二分类训练集x中的每个样本都是n维向量,其分类结果是y = ±1,现在利用PLA训练数据,得到模型hθ(x),对偶形态的求解步骤如下:
1) 初始化α、θ,令θ是0向量
2) 为所有样本添加x0 = 1,计算所有数据样本的点积,形成Gram矩阵
3) 利用JudgeFun从训练集x中随机选出一个误分类样本x(j),j是原始集中的第i个数据。在误分类判断时使用Gram矩阵快速查询点积的值
4) 更新βi,βi = α(mi + 1) = αmi + α,即βi += α
5) 利用JudgeFun检测是否还有误分类点,如果没有,计算θ,算法结束,否则跳转到3;或判断是否达到指定阈值(或循环次数),如果是,计算θ,算法结束,否则跳转到3
代码实现
原始形式
1 from __future__ import division 2 import random 3 import numpy as np 4 import matplotlib.pyplot as plt 5 6 # 使用随机梯度下降法训练模型 7 # trainDatas 训练数据 8 # iterateNum 迭代次数 9 # alpha 学习率 10 def train(trainDatas, iterateNum = 50, alpha = 0.01): 11 theta = [0, 0, 0] 12 13 for i in range(iterateNum): 14 # 对误分类的点进行迭代 15 errDatas = [ex for ex in trainDatas if classify(theta, ex) != ex[2]] 16 # 检测是否还存在误分类点 17 if len(errDatas) == 0: 18 break 19 20 x1, x2, y = random.choice(errDatas) 21 theta[0] += alpha * y 22 theta[1] += alpha * y * x1 23 theta[2] += alpha * y * x2 24 25 return theta 26 27 def classify(theta, data): 28 return np.sign(theta[0] + theta[1] * data[0] + theta[2] * data[1]) 29 30 def getGlobalFun(theta): 31 globalFun = 'g(x) = ' 32 for i, t in enumerate(theta): 33 if t > 0: 34 globalFun += ' +{theta}x{xIdx}'.format(theta=round(float(t), 2), xIdx=i) 35 elif t < 0: 36 globalFun += ' {theta}x{xIdx}'.format(theta=round(float(t), 2), xIdx=i) 37 38 globalFun = globalFun.replace('x0', '') 39 40 return globalFun 41 42 def plot_points(trainDatas,theta): 43 plt.figure() 44 45 # 绘制分隔直线 g = θ0 + θ1x1 + θ2x2 = 0 46 x1 = np.linspace(0, 8, 2) 47 # θ0 + θ1x1 + θ2x2 = 0 => x2 = -(θ0 + θ1x1)/θ2 48 x2 = (-theta[0] - theta[1] * x1) / theta[2] 49 plt.xlabel('x1') 50 plt.ylabel('x2') 51 plt.title('PLA: ' + getGlobalFun(theta)) 52 plt.plot(x1, x2, color='b') 53 54 # 绘制数据点 55 datasLen = len(trainDatas) 56 for i in range(datasLen): 57 if (trainDatas[i][-1] == 1): 58 plt.scatter(trainDatas[i][0], trainDatas[i][1], s=50, color='g') 59 else: 60 plt.scatter(trainDatas[i][0], trainDatas[i][1], marker='x', s=50, color='r') 61 plt.show() 62 63 if __name__ == '__main__': 64 trainDatas = [[1, 3, 1], [2, 2, 1], [3, 4, 1], [2, 5, 1],[2, 1, -1], [4, 1, -1], [6, 2, -1], [5, 3, -1]] 65 theta = train(trainDatas) 66 plot_points(trainDatas, theta)

对偶形式
1 from __future__ import division 2 import random 3 import numpy as np 4 import matplotlib.pyplot as plt 5 6 def get_train_data(): 7 # 构造100个2维正例点 8 m, n = 100, 2 9 x_positive = np.random.random((m, n)) 10 y_positive = np.ones(m) 11 12 # 构造100个2维负例点 13 x_negetive = np.random.random((m, n)) - 0.7 14 y_negetive = np.ones(m) * (-1) 15 16 # 将所有正例点和负例点拼接在一起 17 x = np.vstack((x_positive, x_negetive)) 18 y = np.hstack((y_positive, y_negetive)) 19 20 return x, y 21 22 # Gram矩阵的计算 23 def get_Gram(x): 24 (m, n) = x.shape 25 G = np.zeros((m, m)) 26 for i in range(m): 27 for j in range(m): 28 G[i, j] = np.dot(x[i][:n], x[j][:n]) 29 30 return G 31 32 # 使用随机梯度下降法训练模型 33 # x 训练数据特征集 34 #y 训练数据结果集 35 # iterateNum 迭代次数 36 # alpha 学习率 37 def train(x, y, iterateNum=50, alpha=0.01): 38 theta = [0, 0, 0] 39 m, n = x.shape 40 # β记录每个数据出错的次数 41 beta = np.zeros(m) 42 # 记录误判数据的索引 43 44 # 将x0 = 1 添加到x 45 x = np.c_[np.ones(m), x] 46 # 计算Gram矩阵 47 G = get_Gram(x) 48 for t in range(iterateNum): 49 # 误分类数据集的序号 50 err_datas_idx = [j for j in range(m) if judge_fun(x, y, beta, j, G) <= 0] 51 if len(err_datas_idx) == 0: 52 break 53 54 # 从误分类集随机选择一个数据,更新βj 55 j = random.choice(err_datas_idx) 56 beta[j] += alpha 57 58 # 计算模型函数 59 for t in range(n + 1): 60 theta[t] = sum([beta[i] * y[i] * x[i, t] for i in range(m)]) 61 62 return theta 63 64 def judge_fun(x, y, beta, j, G): 65 return y[j] * sum([beta[i] * y[i] * G[j, i] for i in range(x.shape[0])]) 66 67 # 数据可视化 68 def plot_points(x, y, theta): 69 m = x.shape[0] 70 71 # 绘制分隔直线 g = θ0 + θ1x1 + θ2x2 = 0 72 x1 = np.linspace(-1, 1, 2) 73 # θ0 + θ1x1 + θ2x2 = 0 => x2 = -(θ0 + θ1x1)/θ2 74 x2 = (-theta[0] - theta[1] * x1) / theta[2] 75 plt.xlabel('x1') 76 plt.ylabel('x2') 77 plt.title('PLA: ' + getGlobalFun(theta)) 78 plt.plot(x1, x2) 79 80 # 正例和反例 81 positive_x1 = [x[i, 0] for i in range(m) if y[i] == 1] 82 positive_x2 = [x[i, 1] for i in range(m) if y[i] == 1] 83 negetive_x1 = [x[i, 0] for i in range(m) if y[i] == -1] 84 negetive_x2 = [x[i, 1] for i in range(m) if y[i] == -1] 85 86 # 绘制数据点 87 plt.scatter(positive_x1, positive_x2, c='green') 88 plt.scatter(negetive_x1, negetive_x2, marker='x', c='red') 89 plt.show() 90 91 def getGlobalFun(theta): 92 globalFun = 'g(x) = ' 93 for i, t in enumerate(theta): 94 if t > 0: 95 globalFun += ' +{theta}x{xIdx}'.format(theta=t, xIdx=i) 96 elif t < 0: 97 globalFun += ' {theta}x{xIdx}'.format(theta=t, xIdx=i) 98 99 globalFun = globalFun.replace('x0', '') 100 101 return globalFun 102 103 def get_rate(x, y, threta): 104 m = x.shape[0] 105 right_num = len([i for i in range(m) if np.sign(threta[0] + np.dot(threta[1:], x[i])) == y[i]]) 106 return right_num / m 107 108 109 if __name__ == '__main__': 110 x, y = get_train_data() 111 threta = train(x, y) 112 plot_points(x, y, threta)
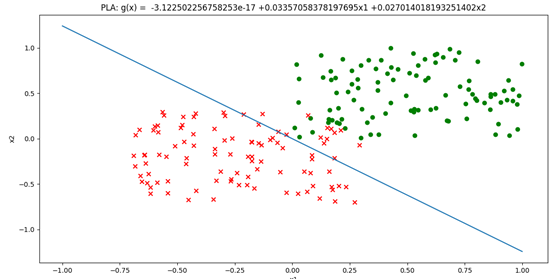
sklearn实现
1 from __future__ import division 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn.datasets import make_classification 5 from sklearn.linear_model import Perceptron 6 7 def train(x, y, iterateNum=50, alpha=0.001): 8 # 定义感知机, Perceptron中的alpha默认值0.0001 9 clf = Perceptron(fit_intercept=False, n_iter=iterateNum, alpha=alpha, shuffle=False) 10 # 使用训练数据进行训练 11 clf.fit(x, y) 12 # 得到训练结果,权重矩阵[θ0, θ1,θ2] 13 #超平面的截距clf.intercept_, 权重clf.coef_ 14 theta = [clf.intercept_[0], clf.coef_[0][0],clf.coef_[0][1]] 15 16 return theta 17 18 def plot_points(x, y,theta): 19 # 正例和反例 20 positive_x1 = [x[i, 0] for i in range(1000) if y[i] == 1] 21 positive_x2 = [x[i, 1] for i in range(1000) if y[i] == 1] 22 negetive_x1 = [x[i, 0] for i in range(1000) if y[i] == 0] 23 negetive_x2 = [x[i, 1] for i in range(1000) if y[i] == 0] 24 25 # 绘制分隔直线 g = θ0 + θ1x1 + θ2x2 = 0 26 x1 = np.linspace(-4, 4, 2) 27 # θ0 + θ1x1 + θ2x2 = 0 => x2 = -(θ0 + θ1x1)/θ2 28 x2 = (-theta[0] - theta[1] * x1) / theta[2] 29 plt.xlabel('x1') 30 plt.ylabel('x2') 31 plt.title('PLA: ' + getGlobalFun(theta)) 32 plt.plot(x1, x2, color='b') 33 34 # 绘制数据点 35 plt.scatter(positive_x1, positive_x2, c='green') 36 plt.scatter(negetive_x1, negetive_x2, marker='x', c='red') 37 plt.show() 38 39 def getGlobalFun(theta): 40 globalFun = 'g(x) = ' 41 for i, t in enumerate(theta): 42 if t > 0: 43 globalFun += ' +{theta}x{xIdx}'.format(theta=float(t), xIdx=i) 44 elif t < 0: 45 globalFun += ' {theta}x{xIdx}'.format(theta=float(t), xIdx=i) 46 47 globalFun = globalFun.replace('x0', '') 48 49 return globalFun 50 51 if __name__ == '__main__': 52 # n_samples:生成样本的数量 53 # n_features=2:生成样本的特征数,特征数=n_informative() + n_redundant + n_repeated 54 # n_informative:多信息特征的个数 55 # n_redundant:冗余信息,informative特征的随机线性组合 56 # n_clusters_per_class :某一个类别是由几个cluster构成的 57 x, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=1, n_clusters_per_class=1) 58 theta = train(x, y) 59 plot_points(x, y, theta)
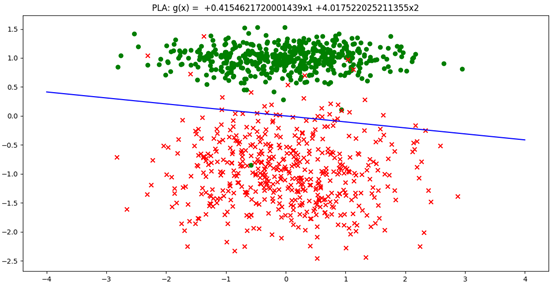
参考:
1.《统计学习方法》李航
2. 吴恩达斯坦福公开课 http://open.163.com/movie/2008/1/B/O/M6SGF6VB4_M6SGHJ9BO.html
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公众号“我是8位的”
