论文:Chinese NER Using Lattice LSTM
论文链接:https://arxiv.org/abs/1805.02023
论文作者:Yue Zhang∗and Jie Yang∗
项目链接:https://github.com/jiesutd/LatticeLSTM
论文翻译:转自机器之心 https://www.jiqizhixin.com/articles/ACL2018-Chinese-NER-Using-Lattice-LSTM
一、摘要
该篇论文是基于字符的LSTM,以Lattice嵌入为输入的模型,该模型对输入字符序列和所有匹配词典的潜在词汇进行编码。
优点:
- 与基于字符的方法相比,该模型显性地利用词和词序信息。
- 与基于词的方法相比,lattice LSTM 不会出现分词错误。
- 门控循环单元使得模型能够从句子中选择最相关的字符和词,以生成更好的 NER 结果。
最终的结果是在多个数据集上的实验证明 lattice LSTM 优于基于词和基于字符的 LSTM 基线模型,达到了最优的结果。它在MSRA数据集上实现了93.18%的F1值。
二、研究介绍
在已有的研究中,中文 NER 中,基于字符的方法表现要优于基于词的方法(He and Wang, 2008; Liu et al., 2010; Li et al., 2014),但是基于字符的 NER 的一个缺陷在于无法充分利用显性的词和词序信息。
实验思路:研究者利用 lattice LSTM 来表征句子中的 lexicon word,从而将潜在词信息整合到基于字符的 LSTM-CRF 中。研究者使用一个大型自动获取的词典来匹配句子,进而构建基于词的 lattice。
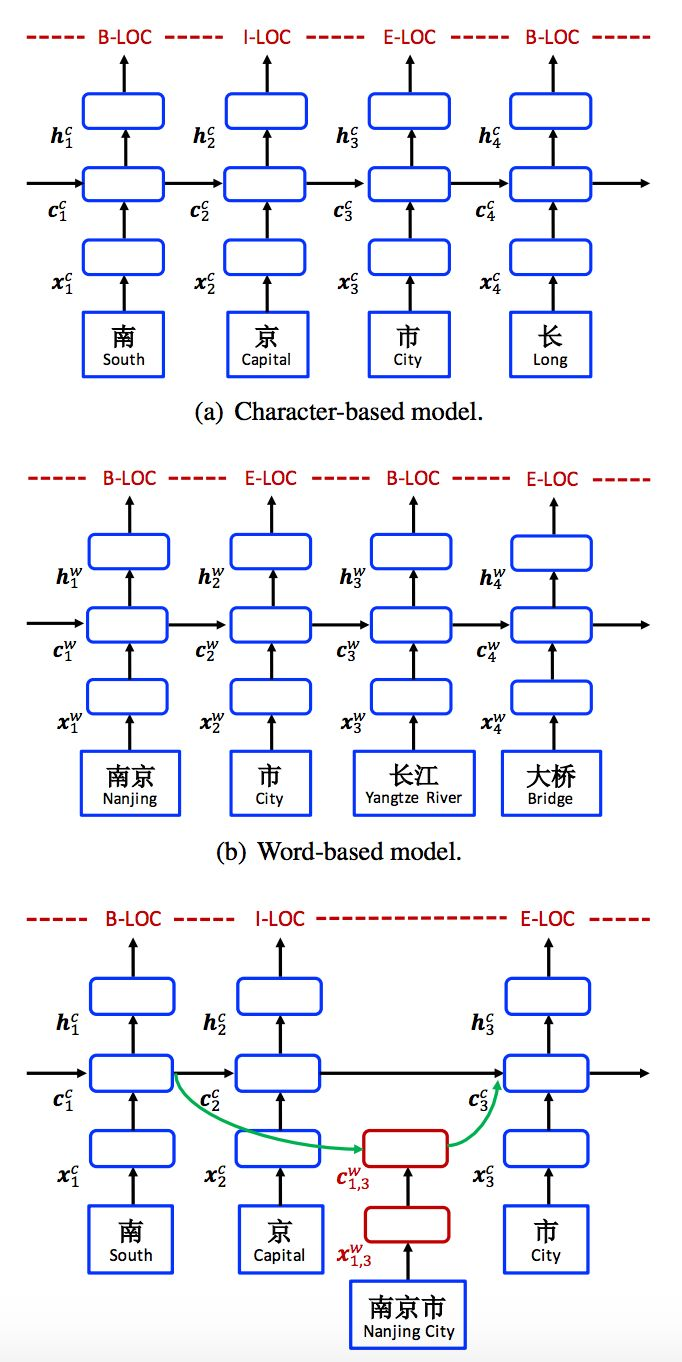
如下图所示,门控单元用于将来自不同路径的信息动态传送到每个字符。在 NER 数据上训练后,lattice LSTM 能够学会从语境中自动找到更有用的词,以取得更好的 NER 性能。

三、模型
在目前,英文 NER 的最高水准是使用 LSTM-CRF 模型实现的,研究者同样使用了 LSTM-CRF 作为主要网络结构。
形式上,指定输入句子为 s = c_1, c_2, . . . , c_m,其中 c_j 指第 j 个字符。s 还可以作为词序列 s = w_1, w_2, . . . , w_n,其中 w_i 指句子中的第 i 个词,使用中文分词器获得。使用 t(i, k) 来指句子第 i 个词中第 k 个字符的索引 j。
以图 1 中的句子为例。如果分词是「南京市 长江大桥」,索引从 1 开始,则 t(2, 1) = 4 (长),t(1, 3) = 3 (市)。研究者使用 BIOES 标记规则(Ratinov and Roth, 2009)进行基于词和基于字符的 NER 标记。
四、实验
数据集:本文使用了四个数据集,其中包括
- Onto Notes 4(Weischedel等,2011)
- MSRA(Levow,2006)
- 微博NER(Peng和Dredze,2015; He和Sun,2017a)https://www.weibo.com/
- 研究者注释的中文简历数据集。http://finance.sina.com.cn/stock/index.shtml
分词模型: 对于微博和简历,研究者采用杨等人的最佳模型(2017a,https://github.com/jiesutd/Rich Word Segmentor)现成的,使用CTB 6.0训练。
词嵌入:研究者使用word2vec(Mikolov等,2013)对自动分割的中文Giga-Word (https://catalog.ldc.upenn.edu/LDC2011T13),预先训练单词嵌入,在最后一个词典中获得704.4k个单词。 在NER训练期间,可以对字嵌入进行微调。 字符和字符双字母嵌入使用word2vec在中文Giga-word上进行预训练,并在模型训练中进行微调。。
超参数设置:嵌入大小(embedding sizes)设置为50,LSTM模型的隐藏大小(hidden size)设置为200. Dropout(Srivastava等,2014)应用于单词和字符嵌入,速率为0.5。 随机梯度下降(SGD)用于优化,初始学习率(initial learning rate)为0.015,衰减率(decay rate)为0.05。
五、结论
与word + char + bichar和char + bichar + softword相比,lattice模型对句子长度的增加表现出更强的鲁棒性,证明了词语信息的更有效使用。
研究者凭经验研究了中文NER的lattice LSTM-CRF表示,发现它与不同领域的word-based 和 character-based LSTM-CRF相比具有始终如一的优越性能。 由于在NER消歧的上下文中选择词典单词的自由度,lattice方法完全独立于分词,但在使用单词信息方面更有效。