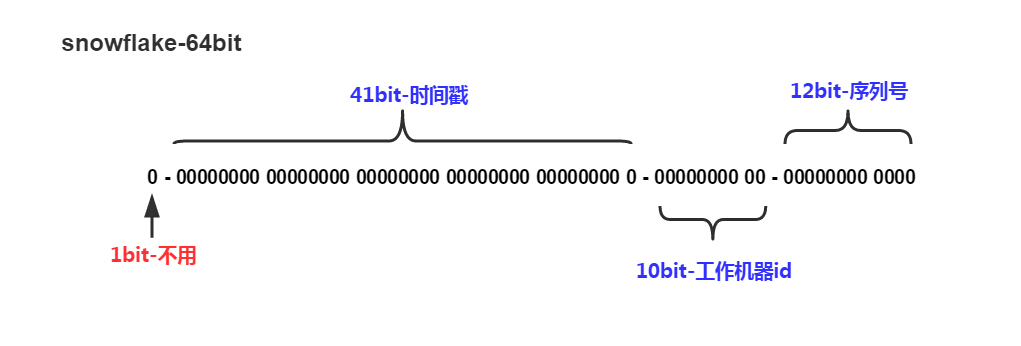
算法比较简单,每个id-generator负责生成的ID由3部分组成,41位时间戳可以表示到毫秒,10bit worker-id内部可自行划分,比如3位表示IDC,7位表示机器。最后12位是在一毫秒的递增id,也就是每毫秒算法可以产生2^12 = 4096个id,QPS 400多万;
snowflake保证1)产生的id分布式系统内全局唯一,2)id趋势递增;不是严格递增,因为集群的机器时间不同步问题
该算法存在一个最严重的问题,是时间回退。比如一台机器A,在t产生一个id,但时钟被调回了t-15,则再次生成的id存在重复的可能。
思考了一个解决这个问题的方法,
在单一id-generator服务上,每ms生成id时,检测current_ms,或<= last_ms则等待last_ms-current_ms后,再开始正常服务。这样若id-generator重启后依然有问题,因为没有地方记录last_ms。并且因为400w的高qps,也无法将其持久化。
我们引入一个第3方,如zookeeper或redis,id-generator服务启动时atomic increase一个key,并将结果用作worker-id。。。
oops!貌似不行,只支持重启1024次