Redis持久化
因为Redis是内存数据库,它将自己的数据库状态储存在内存里面,所以如果不想办法将储存在内存中的数据库状态保存到磁盘里面,那么一旦服务器进程退出,服务器中的数据库状态也会消失不见。
Redis支持两种持久化方式内存快照RDB(Redis DataBase)和日志AOF(Append-only file)。
一、RDB
为了解决这个问题,Redis提供了RDB持久化功能,这个功能可以将Redis在内存中的数据库状态保存到磁盘里面,避免数据意外丢失。RDB持久化既可以手动执行,也可以根据服务器配置选项定期执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中,RDB持久化功能所生成的RDB文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件时的数据库状态。
- RDB文件的创建
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。
1)SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求。
创建RDB文件的实际工作由rdb.c/rdbSave函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数:
int rdbSave(char *filename, rdbSaveInfo *rsi) { #创建RDB文件 char tmpfile[256]; char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */ FILE *fp; rio rdb; int error = 0; snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid()); fp = fopen(tmpfile,"w"); if (!fp) { char *cwdp = getcwd(cwd,MAXPATHLEN); serverLog(LL_WARNING, "Failed opening the RDB file %s (in server root dir %s) " "for saving: %s", filename, cwdp ? cwdp : "unknown", strerror(errno)); return C_ERR; } /* Make sure data will not remain on the OS's output buffers */ if (fflush(fp) == EOF) goto werr; if (fsync(fileno(fp)) == -1) goto werr; if (fclose(fp) == EOF) goto werr; /* Use RENAME to make sure the DB file is changed atomically only if the generate DB file is ok. */ if (rename(tmpfile,filename) == -1) { char *cwdp = getcwd(cwd,MAXPATHLEN); serverLog(LL_WARNING,"Error moving temp DB file %s on the final " "destination %s (in server root dir %s): %s",tmpfile,filename,cwdp ? cwdp : "unknown",strerror(errno)); unlink(tmpfile); return C_ERR; } serverLog(LL_NOTICE,"DB saved on disk"); server.dirty = 0; server.lastsave = time(NULL); server.lastbgsave_status = C_OK; return C_OK; werr: serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno)); fclose(fp); unlink(tmpfile); return C_ERR; }
2)和SAVE命令直接阻塞服务器进程的做法不同,BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求。
#创建子进程 pid = fork() if pid == 0: #子进程负责创建RDB文件 rdbSave() #完成之后向父进程发送信号 signal_parent() elif pid > 0: #父进程继续处理命令请求,并通过轮询等待子进程的信号 handle_request_and_wait_signal() else: #处理出错情况 handle_fork_error()
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { pid_t childpid; long long start; if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR; server.dirty_before_bgsave = server.dirty; server.lastbgsave_try = time(NULL); openChildInfoPipe(); start = ustime(); if ((childpid = fork()) == 0) { int retval; /* Child */ closeListeningSockets(0); redisSetProcTitle("redis-rdb-bgsave"); retval = rdbSave(filename,rsi); if (retval == C_OK) { size_t private_dirty = zmalloc_get_private_dirty(-1); if (private_dirty) { serverLog(LL_NOTICE, "RDB: %zu MB of memory used by copy-on-write", private_dirty/(1024*1024)); } server.child_info_data.cow_size = private_dirty; sendChildInfo(CHILD_INFO_TYPE_RDB); } exitFromChild((retval == C_OK) ? 0 : 1); } else { /* Parent */ server.stat_fork_time = ustime()-start; server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */ latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); if (childpid == -1) { closeChildInfoPipe(); server.lastbgsave_status = C_ERR; serverLog(LL_WARNING,"Can't save in background: fork: %s", strerror(errno)); return C_ERR; } serverLog(LL_NOTICE,"Background saving started by pid %d",childpid); server.rdb_save_time_start = time(NULL); server.rdb_child_pid = childpid; server.rdb_child_type = RDB_CHILD_TYPE_DISK; updateDictResizePolicy(); return C_OK; } return C_OK; /* unreached */
- RDB文件的载入
和使用SAVE命令或者BGSAVE命令创建RDB文件不同,RDB文件的载入工作是在服务器启动时自动执行的,所以Redis并没有专门用于载入RDB文件的命令,只要Redis服务器在启动时检测到RDB文件存在,它就会自动载入RDB文件。

因为AOF文件的更新频率通常比RDB文件的更新频率高,所以:
❑如果服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。
❑只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态。
- RDB执行时系统状态
a) SAVE命令执行时的服务器状态
前面提到过,当SAVE命令执行时,Redis服务器会被阻塞,所以当SAVE命令正在执行时,客户端发送的所有命令请求都会被拒绝。
只有在服务器执行完SAVE命令、重新开始接受命令请求之后,客户端发送的命令才会被处理。
b) BGSAVE命令执行时的服务器状态
因为BGSAVE命令的保存工作是由子进程执行的,所以在子进程创建RDB文件的过程中,Redis服务器仍然可以继续处理客户端的命令请求。
- 客户端发送的SAVE命令会被服务器拒绝
- 客户端发送的BGSAVE命令会被服务器拒绝
- BGREWRITEAOF和BGSAVE两个命令不能同时执行
- RDB文件载入时的服务器状态
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
- 自动间隔性保存
因为BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。用户可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。saveparams属性是一个数组,数组中的每个元素都是一个saveparam结构,每个saveparam结构都保存了一个save选项设置的保存条件:
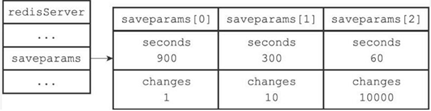
除了saveparams数组之外,redisServer服务器状态还维持着一个dirty计数器,以及一个lastsave属性:
- dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)。
- lastsave属性是一个UNIX时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间。
- RDB文件结构

1.每个非空数据库在RDB文件中都可以保存为SELECTDB、db_number、key_value_pairs三个部分

2.RDB文件中的每个key_value_pairs部分都保存了一个或以上数量的键值对,如果键值对带有过期时间的话,那么键值对的过期时间也会被保存在内。不带过期时间的键值对在RDB文件中由TYPE、key、value三部分组成,

3.RDB文件中的每个value部分都保存了一个值对象,每个值对象的类型都由与之对应的TYPE记录,根据类型的不同,value部分的结构、长度也会有所不同
- 分析RDB文件$ od -c
二、AOF
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的,被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,因为Redis的命令请求协议是纯文本格式AOF文件通过保存所有修改数据库的写命令请求来记录服务器的数据库状态。
- AOF文件的写入与同步
AOF持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾:
def eventLoop(): while True: # 处理文件事件,接收命令请求以及发送命令回复 # 处理命令请求时可能会有新内容被追加到aof_buf缓冲区中 processFileEvents() # 处理时间事件 processTimeEvents() # 考虑是否要将aof_buf中的内容写入和保存到AOF文件里面 flushAppendOnlyFile()
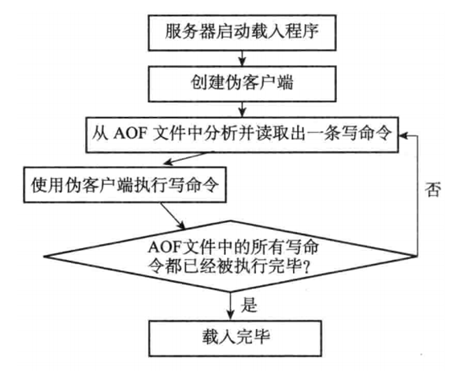
- AOF文件的载入与数据还原
- 创建一个不带网络连接的伪客户端(fake client):因为redis的命令只能在客户端上下文中执行,而载入AOF文件时所使用的命令直接来源于AOF文件而不是网络连接。
- 从AOF文件中分析并读出一条写命令。
- 使用伪客户端执行被读出的写命令。
- 一直执行步骤2和步骤3,直到AOF文件中的所有写命令都被处理完毕为止。
- AOF重写
为了解决AOF文件体积膨胀问题,redis提出了AOF文件重写功能,通过该功能,redis服务器可以创建一个新的AOF文件来替代现有的AOF文件。AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,这个功能是通过读取服务器当前的数据库状态来实现的。AOF重写功能的实现原理:首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令。
aof触发的时机:
1)用户调用BGREWRITEAOF命令
2)aof日志大小超过预设的限额
https://blog.csdn.net/chosen0ne/article/details/44461497
void bgrewriteaofCommand(client *c) { //如果当前正在进行aof rewrite,则返回客户端错误 if (server.aof_child_pid != -1) { addReplyError(c,"Background append only file rewriting already in progress"); } else if (server.rdb_child_pid != -1) { //如果当前正在进行rdb dump,为了避免对磁盘造成压力,将aof_rewrite_scheduled置为1,随后在没有进行aof rewrite和rdb dump时,再开启rewrite server.aof_rewrite_scheduled = 1; addReplyStatus(c,"Background append only file rewriting scheduled"); } else if (rewriteAppendOnlyFileBackground() == C_OK) { //如果当前没有aof rewrite和rdb dump在进行,则调用rewriteAppendOnlyFileBackground进行aof rewrite addReplyStatus(c,"Background append only file rewriting started"); } else { //异常情况,直接返回错误 addReply(c,shared.err); } }
rewrite的大致流程是:
- 创建子进程,获取当前快照,同时将之后的命令记录到aof_rewrite_buf中;
- 子进程遍历db生成aof 临时文件,然后退出;
- 父进程wait子进程,待结束后,将aof_rewrite_buf中的数据追加到该aof文件中;
- 最后重命名该临时文件为正式的aof文件。
id_t childpid; long long start; // <MM> // 避免同时多个进程进行rewrite // </MM> if (server.aof_child_pid != -1) return REDIS_ERR; start = ustime(); if ((childpid = fork()) == 0) { char tmpfile[256]; /* Child */ // <MM> // 子进程不能接受连接 // </MM> closeListeningSockets(0); redisSetProcTitle("redis-aof-rewrite"); // <MM> // 生成临时aof文件名 // </MM> snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid()); if (rewriteAppendOnlyFile(tmpfile) == REDIS_OK) { size_t private_dirty = zmalloc_get_private_dirty(); if (private_dirty) { redisLog(REDIS_NOTICE, "AOF rewrite: %zu MB of memory used by copy-on-write", private_dirty/(1024*1024)); } exitFromChild(0); } else { exitFromChild(1); }
记录当前时间,用于统计fork耗时。然后调用fork,进入子进程的流程。子进程首先关闭监听socket,避免接收客户端连接。同时设置进程的title。然后,生成rewirte要写入的临时文件名。接下来调用rewriteAppendOnlyFile进行rewrite。如果rewrite成功,统计copy-on-write的脏页并记录日志,然后以退出码0退出进程。如果rewrite失败,则退出进程并返回1作为退出码。
} else { /* Parent */ server.stat_fork_time = ustime()-start; server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */ latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); if (childpid == -1) { redisLog(REDIS_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno)); return REDIS_ERR; } redisLog(REDIS_NOTICE, "Background append only file rewriting started by pid %d",childpid); server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL); server.aof_child_pid = childpid; updateDictResizePolicy(); /* We set appendseldb to -1 in order to force the next call to the * feedAppendOnlyFile() to issue a SELECT command, so the differences * accumulated by the parent into server.aof_rewrite_buf will start * with a SELECT statement and it will be safe to merge. */ server.aof_selected_db = -1; replicationScriptCacheFlush(); return REDIS_OK; }
父进程首先统计fork耗时并采样。如果fork失败,记录日志并返回错误。如果fork成功,对aof_rewrite_scheduled清零,记录rewrite开始时间以及aof_child_pid(redis通过这个属性判断是否有aof rewrite在进行)。调用updateDictResizePolicy调整db的key space的rehash策略,由于创建了子进程,避免copy-on-write复制大量内存页,这里会禁止dict的rehash。将aof_selected_db置为-1,目的是,下一条aof会首先生成一条select db的日志,同时会写到aof_rewrite_buf中,这样就可以将aof_rewrite_buf正常的追加到rewrite之后的文件。
} else { /* Parent */ server.stat_fork_time = ustime()-start; server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */ latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); if (childpid == -1) { redisLog(REDIS_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno)); return REDIS_ERR; } redisLog(REDIS_NOTICE, "Background append only file rewriting started by pid %d",childpid); server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL); server.aof_child_pid = childpid; updateDictResizePolicy(); /* We set appendseldb to -1 in order to force the next call to the * feedAppendOnlyFile() to issue a SELECT command, so the differences * accumulated by the parent into server.aof_rewrite_buf will start * with a SELECT statement and it will be safe to merge. */ server.aof_selected_db = -1; replicationScriptCacheFlush(); return REDIS_OK; }
子进程进行aof rewrite的过程,进入rewriteAppendOnlyFile函数。遍历所有key,进行序列化,然后记录到aof文件中:
dictIterator *di = NULL; dictEntry *de; rio aof; FILE *fp; char tmpfile[256]; int j; long long now = mstime(); /* Note that we have to use a different temp name here compared to the * one used by rewriteAppendOnlyFileBackground() function. */ snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid()); fp = fopen(tmpfile,"w"); if (!fp) { redisLog(REDIS_WARNING, "Opening the temp file for AOF rewrite in rewriteAppendOnlyFile(): %s", strerror(errno)); return REDIS_ERR; } //获取当前时间,生成临时文件名并创建该文件。 rioInitWithFile(&aof,fp); if (server.aof_rewrite_incremental_fsync) rioSetAutoSync(&aof,REDIS_AOF_AUTOSYNC_BYTES); //循环,用于遍历redis的每个db,对其进行rewirte char selectcmd[] = "*2 $6 SELECT "; redisDb *db = server.db+j; dict *d = db->dict; if (dictSize(d) == 0) continue; di = dictGetSafeIterator(d); if (!di) { fclose(fp); return REDIS_ERR; } //首先,生成对应db的select命令,然后查看如果db为空的话,就跳过,rewrite下一个db。然后获取该db的迭代器,如果获取失败,直接返回错误。最后将select db的命令写入文件。 if (rioWrite(&aof,selectcmd,sizeof(selectcmd)-1) == 0) goto werr; if (rioWriteBulkLongLong(&aof,j) == 0) goto werr; //循环,用于遍历db的每一个key while ((de = dictNext(di)) != NULL) { // ... } dictReleaseIterator(di);
AOF Rewrite Buffer追加到文件,将临时文件重命名为最终的aof文件。最后,更新状态,异步关闭之前的aof文件。
(1)AOF后台重写提出的原因
因为redis服务器是使用单线程来处理命令请求的,如果由服务器直接调用aof_rewrite函数的话,那么在重写AOF文件期间,服务器将无法处理客户端发来的命令请求,所以,redis决定将AOF重写程序放在子进程里执行,这样就可以同时达到两个目的。
- 一是子进程执行AOF重写期间,服务器进程(父进程)可以继续处理命令请求。
- 二是子进程带有服务器进程的数据副本,使用子进程而不是线程,可以避免使用锁的情况下,保证数据的安全性。
(2)AOF重写存在的问题及解决方案
存在的问题:因为子进程在在进行AOF重写期间,服务器进程还需要继续处理命令请求,而新的命令可能会对现有的数据库状态进行修改,从而使得服务器当前的数据库状态和重写后的AOF文件所保存的数据库状态不一致。
解决方法:redis服务器设置了一个AOF重写缓冲区,这个缓冲区在服务器创建子进程之后开始使用,当redis服务器执行完一个写命令之后,它会同时将这个写命令发送给AOF缓冲区和AOF重写缓冲区。
(3)子进程执行AOF重写期间,服务器进程需要做的事情:
- 执行客户端发来的命令。
- 将执行后的写命令追加到AOF缓冲区。
- 将执行后的写命令追加到AOF重写缓冲区。
总结:
❑RDB文件用于保存和还原Redis服务器所有数据库中的所有键值对数据。
❑SAVE命令由服务器进程直接执行保存操作,所以该命令会阻塞服务器。
❑BGSAVE令由子进程执行保存操作,所以该命令不会阻塞服务器。
❑服务器状态中会保存所有用save选项设置的保存条件,当任意一个保存条件被满足时,服务器会自动执行BGSAVE命令。
❑RDB文件是一个经过压缩的二进制文件,由多个部分组成。
❑对于不同类型的键值对,RDB文件会使用不同的方式来保存它们。
❑AOF文件通过保存所有修改数据库的写命令请求来记录服务器的数据库状态。
❑AOF文件中的所有命令都以Redis命令请求协议的格式保存。
❑命令请求会先保存到AOF缓冲区里面,之后再定期写入并同步到AOF文件。
appendfsync选项的不同值对AOF持久化功能的安全性以及Redis服务器的性能有很大的影响。
❑服务器只要载入并重新执行保存在AOF文件中的命令,就可以还原数据库本来的状态。
❑AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
❑AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对实现的,程序无须对现有的AOF文件进行任何读入、分析或者写入操作。
在执行BGREWRITEAOF命令时,Redis服务器会维护一个AOF重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件的重写操作。