设计构造块
设计现实世界中的对象
在确定设计方案时,首选且最流行的一种做法便是“常规的”面向对象设计方法,此方法的要点是辨识现实世界中的对象(object,物体)以及人造的(synthetic)对象。
使用对象进行设计的步骤是:
- 辨识对象及其属性(方法(method)和数据(data))。
- 确定可以对各个对象进行的操作。
- 确定各个对象能对其他对象进行的操作。
- 确定对象的哪些部分对其他对象可见,哪些是公用(public),哪些是私用的(private)。
- 定义每个对象的公开接口。
这些步骤并无须以特定顺序来完成,它们也经常会被反复执行。迭代是非常重要的。下面来总结一下每一个步骤:
辨识对象及其属性:计算机程序通常都是基于现实世界的实体。例如,你可以基于现实世界中的雇员(Employee)、顾客(Client)、工作时间记录卡(Timecard)以及账单(Bill)等实体来开发一套按时间计费的系统。图1-5显示了这样一套收费系统的面向对象视图。
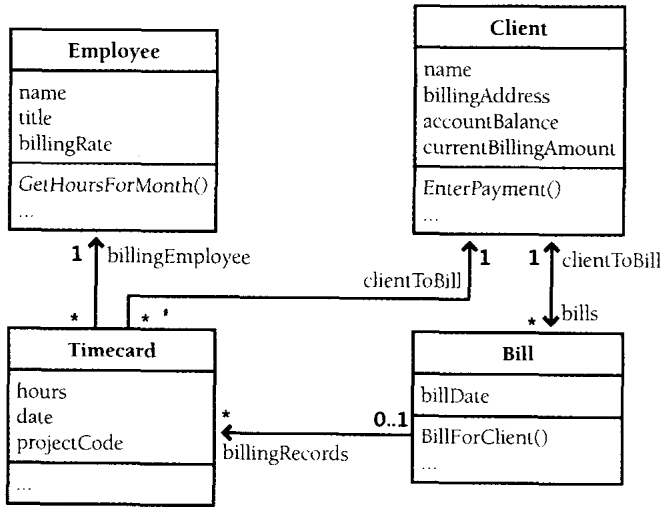
图1-5 收费系统由四种主要的对象构成,这些对象在本例中进行了一定的简化
辨识对象的属性并不必辨识对象本身更困难。每个对象都有一些与计算机程序相关的特征。例如,在这个收费系统里,每个雇员对象都具有名字(name)、职务(title)和费率(billingRate)等属性;而顾客对象则具有名字(name)、账单寄送地址(billingAddress)以及账户余额(accountBalance)等属性;账单对象具有收费金额、顾客名字、支付日期(billDate)。
图形用户界面系统中的对象可能包括窗体、对话框、按钮、字体以及画图工具等。相比于“把软件中的对象一一映射为现实世界中的对象”,深入挖掘问题领域可能会得出更好的设计方案,不过从现实世界中的对象入手的确是不错的起点。
定义可对对象执行的操作:在每个对象之上都可以执行多种操作。在图1-5所示的收费系统里,雇员对象可能需要修改职务或费率,顾客对象可能需要修改名字或者账单寄送地址,等等。
确定每个对象可以对其他对象进行的操作:这一步骤的目的显而易见。对象之间最常见的两种关系是包含和继承。哪些对象可以包含其他对象?哪些对象又可以从其他对象继承,图1-5中,一个Timecard对象可以包含一个Employee对象和一个Client对象,一个Bill对象可以包含一个或多个Timecard对象。另外,一份账单可以标示是否已经给某位顾客开过账单了,而顾客也可以签付一份账单。更复杂的系统中还会包含其他更多的交互关系。
确定对象的哪些部分对其他对象可见:一项关键的设计决策就是明确对象的哪些部分应该是公开的(public),哪些部分又不应该公开(private)。对数据和方法都要做这一决策。
定义每个对象的接口:在编程语言的层次上为每个对象定义具有正式语法的接口。对象对其他对象暴露的数据及方法都被称为该对象的“公开接口/public interface”,而对象通过继承关系向其派生对象暴露的部分则被称为“受保护的接口/protected interface”。要考虑这两种不同的接口。
经过上述这些步骤得到一个高层次的、面向对象的系统组织接口之后,你可以用这两种方法来迭代:在高层次的系统组织结构上进行迭代,以便更好地组织类的结构;或者在每一个已经定义好的类上进行迭代,把每个类的设计细化。
形成一致的抽象
抽象是一种能让你在关注某一概念的同时可以放心忽略其中一些细节的能力——在不同的层次处理不同的细节。任何时候当你在对一个聚合物品(aggregate)工作时,你就是在使用抽象了。当你把一个东西称为“房子”而不是由玻璃、木材和钉子构成的组合体时,你就是在用抽象了。当你把一组房屋称为“城镇”时,你就是在使用抽象了。
基类也是一种抽象,它使你能集中精力关注一组派生类所具有的共同特性,并在基类的层次上忽略各个具体派生类的细节。一个好的借口也是一种抽象,它能让你关注于接口本身而不是类的内部工作方式。一个设计良好的子程序借口也在较低的层次上提供了同样的好处,而设计良好的包和子系统的接口则在更高的层次上提供了同样的好处。
封装实现细节
封装填补了抽象留下的空白。抽象是说:“可以让你从高层的细节来看待一个对象。”而封装则说:“除此之外,你不能看到对象的任何其他细节层次。”
当继承能简化设计时就继承
在设计软件系统时,经常会发现一些大同小异的对象。比如说,老师和医生都拥有部分同样的数据,他们都有年龄、性别、家庭住址等,但又在小部分上面不太一样,比方老师有课程的数据,而医生有管理科室的数据。定义这种对象之间的相同点和不同点就叫“继承”。继承的好处在于它能够很好地辅佐抽象的概念。抽象是从不同的细节层次来看对象的,举个栗子,门从一个层次来看,它是用木头或者钢铁做的,从另一个层次来看,门又可以用来阻挡盗贼。
继承能简化编程的工作,因为你可以写一个基本的子程序处理只依赖于门的基本属性的事项,另外写一些特定的子程序来处理依赖特定种类的门的特定操作。有些操作,如Open()或Close(),对于任何种类的门都能用,无论它是防盗门、木门还是玻璃门。编程语言如果能支持像Open()或Close()这样在运行期才能确定所针对的对象的实际类型的操作,这种能力叫做“多态/polymorphism”。
隐藏秘密(信息隐藏)
信息隐藏是结构化程序设计与面向对象设计的基础之一。结构化设计里面的“黑盒子”概念就是来源于信息隐藏。在面向对象设计中,它又引出了封装和模块化的概念,并与抽象的概念紧密相关。
秘密和隐私权
当信息被隐藏后,每个类(或者包和子程序)都代表了某种对其他类保密的设计或构建决策。隐藏起来的秘密可能是某个易变的区域,或者某种文件格式,或某种数据类型的实现方式,或某个需要隔离的区域,在这个区域中发生的错误不会给程序其余部分带来太大的损失。在这里,类的职责就是把这部分信息隐藏起来,并保护自己的隐私权。对系统的非重大改动可能会影响到某个类中的几个子程序,但它们不应该波及到类接口的外面。
类的接口应该尽可能少地暴露其内部工作机制。类很像冰山:八分之七都是位于水下,而你只能看见水面上的八分之一。设计类的接口与设计其他环节一样,都是一个迭代的过程。如果你第一次没有得到合适的接口,那么久多尝试几次,知道设计稳定下来。如果设计仍不稳定,那你就需要换种方法再尝试。
信息隐藏的一个例子
假设你有一个程序,其中的每个对象都是通过一个名为id的成员变量来保存一种唯一的ID。一种设计方法是用一个整数来表示ID,同时用一个名为g_maxId的全局变量来保存目前已分配的ID的最大值。每当创建新的对象时,你只要在该对象的构造函数里简单地使用id = ++g_maxId这条语句,就可以获得唯一的ID值。这样做可以使得创建时执行的代码量最少,但这样的设计有没有问题?
如果你想把某些范围的ID留作他用怎么办?如果你想使用非连续的ID来提高安全性怎么办?如果你想重新使用已销毁对象的ID呢?另外,如果程序是多线程的话,这种方法不是线程安全的。
创建新ID的方法就是一种你应该隐藏起来的设计决策。如果你在程序中到处使用++g_maxId的话,你就暴露了创建新ID的方法,也就是通过简单递增g_maxId。相反,如果你在程序中都使用语句id = NewId(),那就把创建新ID的方法隐藏起来了。你可以在NewId()子程序中仍然只用一行代码,return (++g_maxId),或其他与之等价的方法。如果日后你想把某些范围的ID留作他用,或者重用旧ID时,只需要对NewId()子程序内部加以改动即可。
另一个需要隐藏的秘密就是ID的类型。假设原先你的ID类型是int,后面因其他原因,需要改成字符串类型,你可能需要改动很多int id = NewId()这样的语句,因此,你可以创建一个IdType类型来隐藏ID的类型,这个IdType里面包裹的id可能是整型或者字符串类型。
信息隐藏的障碍
信息过度分散
信息隐藏的常见障碍之一是信息在系统内过度分散。你可能把0这个数字直接写在程序里,这会导致对它的应用过度分散。最好是把0声明为一个常量,比如叫ZERO,然后在程序中引用ZERO这个常量。
信息过度分散的另一个例子是在系统内部到处都有与人机交互相关的内容。一旦交互方式改变——比如说从图形用户界面变为命令行界面——那么几乎所有代码都需要改动。最好把与人机交互逻辑集中到一个单独的类、包或者子系统中,这样,改动就不会给系统带来全局性的影响了。
再举个关于全局数据项的例子——比如说一个在程序全局范围内都可以访问的、含有1000个员工对象的员工数组。如果程序直接使用该全局数据,那么关于该数据项的实现细节——比如它是个数组,可以存放1000个元素这些信息,就会在程序中到处分散。而如果程序仅通过访问器子程序来使用该数据的话,只有访问器子程序才知道其实现细节。
循环依赖
一种更为隐晦的信息隐藏障碍则是循环依赖,比如说A类中的子程序调用了B类中的子程序,然后B类中的子程序又调用了A类中的子程序。要避免形成这种循环依赖,它会让系统难于测试,因为你无法单独测试A类,也无法单独测试B类,除非另一个类至少已经部分就绪。
把类内数据误认为全局数据
如果你是个谨慎的程序员,那么有效地隐藏信息的障碍之一就是把类内数据误认为是全局数据并避免使用它,因为你想避免全局数据可能带来的问题。全局变量会让你陷入很多编程陷阱,而类内数据可能带来的风险则要小得多。
全局数据通常会受困于两类问题:一种是子程序在全局数据之上执行操作,但却不知道还有其他的子程序民在用这些全局数据进行操作;另一种是子程序知道其他的子程序也在用全局数据进行操作,但却无法明确地知道都进行了哪些操作。而类内数据就不会遇到这两种问题,因为只有类内部的少数子程序才能直接访问这些数据。这些子程序不但知道有其他子程序在操作这些数据,而且也明确知道具体是哪些子程序在执行这些操作。
当然,上述观点的前提是:你的系统使用了设计良好的、体积小巧的类。如果你的程序被设计为使用了很多体积庞大、包含众多子程序的类的话,那么类数据和全局数据之间的区别就变得模糊起来,类内数据也将受困于全局数据所面临的问题了。
可以察觉的性能损耗
信息隐藏的最后一个障碍是试图在系统架构层和编码层均避免性能上的损耗。你不必在任何一层担心。因为在架构层按照信息隐藏的目标去设计系统并不会与按照性能目标去设计相冲突。如果你紧记信息隐藏和性能这两点,那么就可以达到这两个目标。
更常见的担心来自于编码层。你可能认为,由于有了额外层次的对象实例化和子程序调用等,间接访问对象会带来性能上的损耗。事实上,这种担心为时沿早,因为你能够衡量系统的性能,并且找出妨碍性能的瓶颈所在之前,在编码层能为性能目标所做的最好准备,便是做出高度模块化的设计来。等你日后找出了性能瓶颈,你就可以针对个别的类或子程序进行优化而不会影响系统的剩余部分了。
找出容易改变的区域
对优秀设计师一份研究表明,他们所共有的一项特质就是都有对变化的预期能力。好的程序设计所面临的最重要挑战之一就是适应变化。目标应该是把不稳定区域隔离出来,从而把变化所带来的影响限制在一个子程序、类或者包的内部。下面给出你应该采取的应对各种变动的措施:
- 找出看起来容易变化的项目:如果需求做得很好,那么其中就应该包含一份潜在变化的清单,以及其中每一项变化发生的可能性。在这种情况下,找出潜在的变化就非常容易了。
- 把容易变化的项目分离出来:把第一步中找出的容易变化的组件单独划分成类,或者和其他容易同时发生变化的组件划分到同一个类中。
- 把看起来容易变化的项目隔离出来:设法设计好类之间的接口,使其对潜在的变化不敏感。设计好类的接口,把变化限制在类的内部,且不会影响类的外部。任何使用了这个将会发生变化的类的其他类都不会察觉到变化的存在。类的接口应该肩负起保护类的隐私的职责。
下面是一些容易发生变化的区域:
- 业务规则:业务规则很容易成为软件频繁变化的根源。如:国会改变了税率结构、保险公司改变了它的税率表。如果你遵守信息隐藏规则,就不该把业务规则的逻辑遍布于整个程序,而是仅仅隐藏于系统的某个角落,直到需要对它进行改动。
- 对硬件的依赖性:与屏幕、打印机、键盘、鼠标、硬盘、声音设施以及通信设计等之间的接口都是赢家依赖的例子。请把对硬件的依赖隔离到它们自身的子系统或类中。这种隔离非常有利于把程序移植到新的环境下。
- 输入和输出:在做比纯硬件接口层稍高一些层面的设计时,输入输出也是一个容易变化的区域。如果你的程序创建了自己的数据文件,那么该文件格式就可能会随软件开发的不断深化而变化。用户层的输入和输出格式也会改变,输出页面上字段的位置、数量和排列顺序都可能会变。
- 非标准的语言特性:大多数编程语言的实现中都包含了一些便利的、非标准的扩展。这些扩展可能在不同的环境中不可用。比如:不同的硬件、不同的发行商。如果你使用了编程语言的非标准扩展,请把这样的扩展单独隐藏在某个类里,以便当你转移到新环境后可以自己写代码去取代它。
- 困难的设计区域和构建区域:把困难的设计区域和构建区隐藏起来也是很好的想法,因为这些代码可能因为设计得很差需要重构。请把它隔离起来,把其拙劣的设计和“构建”对系统其余部分的可能影响降至最低。
- 状态变量:状态变量用于表示程序的状态,与大多数其他的数据相比,这种东西更容易改变。举个栗子,你可能一开始用布尔变量来定义出错状态,然后又发现用具有ErrorType_None、ErrorType_Warning和ErrorType_Fatal等枚举类型来表示状态更好。你可以在使用状态变量时增加至少两层的灵活性和可读性:(1)不要使用布尔变量作为状态变量,请使用枚举类型。给状态变量新增一个状态很常见,给枚举类型增加一个新的状态只需重新编译一次,而无需对每一行检查该状态变量的代码都做一次全面修订。(2)使用访问器子程序取代对状态变量的直接检查。通过检查访问器子程序而不是检查状态变量,使程序能够测试更复杂的状态情况。例如,如果你想联合检查某一错误状态变量和当前功能状态变量,那么如果该条测试语句隐藏在一段子程序里,这就很容易做到;而如果把该测试语句硬编码到程序各处,则会困难重重。
- 数据量的限制:当你定义一个具有100个元素的数组时,你实质上是向外界透露一些它们并不需要知道的信息。保护好你的隐私!信息隐藏并不总是像创建新类一样复杂,有时候它就像使用常量MAX_EMPLOYEES来隐藏100一样简单
保持松散耦合
耦合度表示类与类之间或子程序与子程序之间关系的亲密度。耦合度设计的目标是创建出小的、直接的、清晰的类或子程序,使它们与其他类或子程序之间关系尽可能地灵活,这就被称作“松散耦合”。
模块之间的好的耦合关系会松散到恰好能使一个模块能够很容易地被其他模块使用。火车模型之间通过环钩彼此相连,把两辆车厢连起来非常容易,只用把它们之间钩起来就可以了。设想如果你必须把它们用螺丝拧在一起,或者要连很多的线缆,或者只能连接特定种类的车厢,那么连接工作将会非常复杂。火车车厢之间之所以能够相连,就是因为这种连接关系非常的简单。在软件中,也请确保模块之间的连接关系尽可能简单。
也尽量使你创建的模块不依赖或很少依赖其他模块。让模块之间的关系像商业合作者一样彼此分离,而不是像连体婴儿般紧密相连。像sin()这样的子程序是松散耦合的,因为它只需要知道传入的是一个代表角度的值。而像InitVars(var1, var2,……,varN)这样的子程序则耦合得过于紧密了,因为对于调用端必须传入的各个参数,调用它的模块实际上需要知道在InitVars()的内部会做什么。如果两个类都依赖于对方对同一个全局变量的使用情况,那么它们之间的耦合关系就更为紧密了。
耦合标准
接下来是一些在衡量模块之间耦合度时可采用的标准:
规模:这里的规模指的是模块之间的连接数。只有一个参数的子程序与调用它的子程序之间的耦合关系比有六个参数的子程序与它的调用方之间的耦合关系更松散
可见性:可见性指的是两个模块之间的连接的显著程度。
灵活性:指的是模块之间的连接是否容易改动。理想状态下,你会更喜欢计算机上热插拔的USB连接器,而不喜欢电烙铁焊接导线的连接方式。
假设你有一段子程序,通过输入雇员的雇佣日期和工作级别可以查询雇员每年可获得的假期,这段子程序被命名为vocationBenefit()。假设另一个模块里有一个employee对象,其中包含雇佣日期和工作级别,以及其他一些信息,该模块把employee对象传给vocationBenefit()。现在看来,这种耦合关系是松散的,两个模块之间的employee连接是可见的,而且这里只存在一个连接。现在假设另一个模块需要使用vocationBenefit(),但这一模块没有employee这个概念,但却包含vocationBenefit()必须的雇佣日期和工作级别,这样,vocationBenefit()一下子就变得不太友好了,它无法和新的模块工作。
要使第三方模块可以使用vocationBenefit(),它就必须了解employee,它可能临时去拼凑一个只包含雇佣日期和工作级别的employee对象,但这就需要了解vocationBenefit()的内部机制,到底使用了employee对象多少的信息,这样的解决方案显然非常牵强,也十分丑陋。第二种防范就是对vocationBenefit()做出修改,它只接受雇佣日期和工作级别这两个参数,而不用employee。但这种方案无论如何都比之前灵活多了。
简而言之,一个模块越容易被其他模块所调用,那么它们之间的耦合关系就会越松散。这种设计非常不错,因为它更灵活,并且更易于维护。
耦合种类
下面是你会遇到的常见的几种耦合:
- 简单数据参数耦合:当两个模块之间通过参数来传递数据,并且所有的数据都是简单数据类型的时候,这两个模块之间的耦合关系就是简单数据参数耦合的。这种耦合关系是正常的。
- 简单的对象耦合:如果一个模块实例化一个对象,那么它们之间的耦合关系就是简单对象耦合的。这种耦合关系也算尚可接受。
- 对象参数耦合:如果Object1要求Object2传递一个Object3,那么这两个模块就是对象参数耦合的。与Object1仅仅要求Object2传递给它简单数据类型相比,这种耦合关系要更紧密一些,因为它要求Object2要求了解Object3。
- 语义上的耦合:最难缠的耦合关系是这样发生的,一个模块不仅使用了另一个模块的语法元素,而且还使用了有关那个模块内部工作细节的语义知识。这里有些例子:
- Model1向Model2传递一个控制标志,用它告诉Model2该做什么。 这种做法要求Model1对Model2的内部工作细节有所了解,也就是说需要了解Model2对控制标志的使用。如果Model2把这个控制标志定义成一种特定的数据类型(枚举类型或对象),那么这种使用还说的过去。
- Model2在Model1修改了某个全局数据之后使用该全局数据。这种方式就要求Model2假设Model1对该数据所做出的修改符合Model2的需要,并且Model1已经在恰当的时间被调用过。
- Model1的接口要求它的Model1.Initialize()子程序必须在它的Model1.Routine()之前得到调用。Model2在知道Model1.Routine()无论如何都会调用Model1.Initialize(),所以它在实例化Model1之后只是调用了Model1.Routine(),而没有先去调用Model1.Initialize()。
- Model1把Object传给Model2。由于Model1知道Model2只用了Object的七个方法中的三个,因此它只部分地初始化Object中只包含那3个方法所需的数据。
- Model1把BaseObject传给Model2。由于Model2知道Model1实际上传给它的是DerivedObject,所以它把BaseObject转换成DerivedObject,并且调用了DerivedObject特有的方法。
语义上的耦合是非常危险的,因为更改被调用的模块中代码可能会破坏调用它的模块,破坏的方式是编译器完全无法检查的。松散耦合的关键之处在于,一个有效的模块提供出了一层附加的抽象,一旦你写好了它,你就可以想当然地去用它。这样就降低了整体系统的复杂度,使得你可以在同一时间只关注一件事。如果对一个模块的使用要求你同时关注好几件事,其内部工作的细节、对全局数据的修改、不确定的功能点,那么就失去了抽象的能力,模块所具有的管理复杂度的能力也就削弱或完全丧失了。
类和子程序是用于降低复杂度的首选和最重要的工具,如果它们没有帮助你简化工作,那么它们就失职了。