1、布隆过滤器是什么?
又快又小的处理方法
布隆过滤器(Bloom Filter):是一种空间效率极高的概率型算法和数据结构,用于判断一个元素是否在集合中(类似Hashset)。
它的核心一个很长的二进制向量和一系列hash函数
数组长度以及hash函数的个数都是动态确定的。
Hash函数:SHA1,SHA256,MD5..
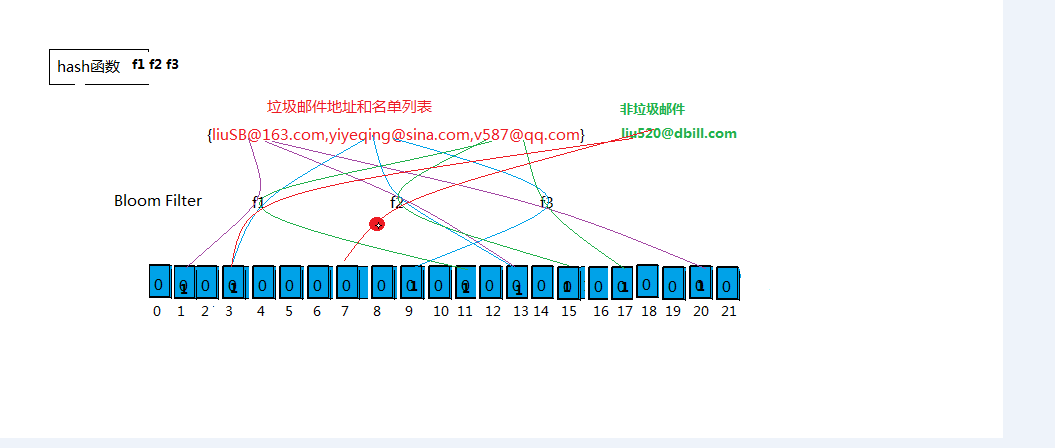
2、应用的经典场景
一个像Yahoo,HotMail和Gmail那样的公众电子邮件提供商,
总是需要过滤来自发送垃圾邮件的人的垃圾邮件,
一个办法就是记录下那些发送垃圾邮件的email地址,
由于那些发送者不停地再注册新的地址,全世界少说也有五十亿个发垃圾邮件的地址,
怎么样迅速的判断一个邮件地址是不是垃圾邮件地址?把它存起来然后确认?
一个邮箱平均18个字节,50亿个邮箱容量多大?
18byte x 50亿 = 90亿
3、优势和劣势
优势:
全量存储但是不存储元素本身,在某些对保密要求非常严格的场合有优势;
空间高效率
插入/查询时间都是常数O(k),远远超过一般的算法
劣势:
存在误算率(False Positive),随着存入的元素数量增加,误算率随之增加;
一般情况下不能从布隆过滤器中删除元素;
数组长度以及hash函数个数确定过程复杂;
4、应用场景
- Google著名的分布式数据库Bigtable以及Hbase使用了布隆过滤器来查找不存在的行或列,以及减少磁盘查找的IO次数
- 文档存储检查系统也采用布隆过滤器来检测先前存储的数据
- Goole Chrome浏览器使用了布隆过滤器加速安全浏览服务
- 垃圾邮件地址过滤
- 爬虫URL地址去重
- 解决缓存穿透问题
5、Bloom Filter实战
使用goole guava轻松实现bloom filter
源码分析 bitArray,numHashFunction,funnel,Strategy,put(),
Demo实例
场景描述:100w字符串放入布隆过滤器,另外随机生成1w字符串,判断他们在100w里面是否存在
目的,了解布隆过滤器的简单使用;
了解误判率对hash函数个数以及bit数组长度的影响
使用bloom filter解决缓存击穿的问题
public class BloomFilterTest { private static final int insertions = 1000000; //100w @Test public void bfTest(){ //初始化一个存储string数据的布隆过滤器,初始化大小100w,不能设置为0 BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions,0.001); //初始化一个存储string数据的set,初始化大小100w Set<String> sets = new HashSet<>(insertions); //初始化一个存储string数据的set,初始化大小100w List<String> lists = new ArrayList<String>(insertions); //向三个容器初始化100万个随机并且唯一的字符串---初始化操作 for (int i = 0; i < insertions; i++) { String uuid = UUID.randomUUID().toString(); bf.put(uuid); sets.add(uuid); lists.add(uuid); } int wrong = 0;//布隆过滤器错误判断的次数 int right = 0;//布隆过滤器正确判断的次数 for (int i = 0; i < 10000; i++) { String test = i%100==0?lists.get(i/100):UUID.randomUUID().toString();//按照一定比例选择bf中肯定存在的字符串 if(bf.mightContain(test)){ if(sets.contains(test)){ right ++; }else{ wrong ++; } } } System.out.println("=================right====================="+right);//100 System.out.println("=================wrong====================="+wrong); } }
6、解决缓存击穿
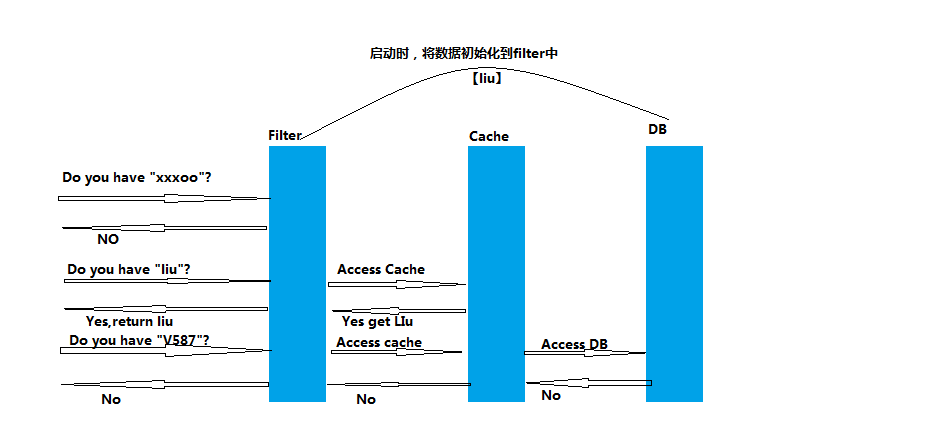
private BloomFilter<String> bf; @postConstruct ------------->初始化的方法 private void init(){ //将唯一编码加进来 //初始化布隆过滤器 bf = BloomFiler.create(Funnels.stringFunner(Charsets.UTF_8),编码.size()*1.2); for(String str:ucodes){ bf.put(str); } ========将布隆过滤器的数据放到单个服务,和业务代码分开 使用多线程放进去 if(bf.mightContain(usercode)){ return null; }
本次布隆过滤器落地场景是:优化关联查询
优化背景:查询订单需要关联预警订单数据,由于每查询一笔预警就要查询一次预警表,效率低,即是判断该订单是否预警
可以先将预警的订单放到布隆过滤器中存放一份,则查询订单的时候可以用于关联
应用该场景的原因:大部分订单还是正常的,所以没不要每次去关联
先去布隆过滤器查询该订单是否存在,不存在则直接返回正常,存在则去预警表查询,允许一定的误差率