一、sklearn.metrics.accuracy_score
这个包可以帮助我们统计两个列表中相同位置元素相同的个数,比如我们预测出来的label和真实的label有多大差距,预测的准确率是多少,可以用它
import numpy as np from sklearn.metrics import accuracy_score y_pred = [0, 2, 1, 3] y_true = [0, 1, 2, 3] accuracy_score(y_true, y_pred) #0.5 accuracy_score(y_true, y_pred, normalize=False) #2
二、sklearn.metrics.classification_report
sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息
参数可查看官方文档
from sklearn.metrics import classification_report y_true = [0, 1, 2, 2, 2] y_pred = [0, 0, 2, 2, 1] target_names = ['class 0', 'class 1', 'class 2'] print(classification_report(y_true, y_pred, target_names=target_names))
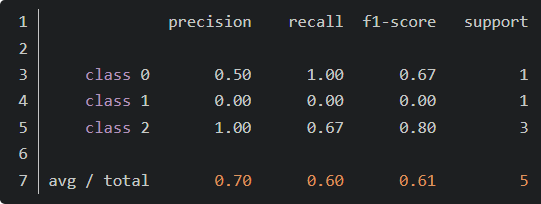
三、sklearn.model_selection.GridSearchCV
用于模型最佳参数的获取,其中的estimator参数:
estimator:所使用的分类器,如estimator=RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,max_features='sqrt',random_state=10)
并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法