Python爬虫实战之二 - 基于Requests抓取拉勾网招聘信息
---------------readme---------------
简介:本人产品汪一枚,Python自学数月,对于小白,本文会是一篇比较容易上手的经验贴。当然毕竟是新手,欢迎大牛拍砖、狂喷~
致谢:
本着了解招聘行情,以备不时之需;之所以选择拉勾网下手,是因为对于互联网相关行业,拉勾属于相对专业的网站,至少个人观点是比某联招聘要好很多;同时也感谢拉勾网的权威招聘信息,也使我对Requests方法更为熟悉。
爬取拉勾官网(www.lagou.com)期间,若对拉勾造成或小或大的影响,本人深感歉意。本文只为获取招聘信息和交流学习,并无恶意,再次鸣谢。
---------------正文分隔符---------------
开发环境
- MacBook Air (13-inch, Early 2015)
- macOS High Sierra 10.13.6
- 1.6GHZ Inter Core i5
- Python:V 3.7.0
一、需求
因本人产品汪一枚,所以首要需求就是爬取拉勾网北京地区、产品经理职位的招聘信息。
二、拉勾网Html页面分析
1、拉钩网页面分析
首先,使用自己账号登陆拉勾网,这个在分析header中会带有cookies等信息,在spider模拟访问请求的url时,被反爬虫的概率更小些(ps:拉勾网总不至于不让用户查询招聘信息吧...)
当然,也可以不用账号的信息进行爬取,代码应该大体相同,不同的只会在header的参数略微有区别。
登陆完成后,在拉勾网的首页(https://www.lagou.com/)检索栏输入“产品经理”,点击搜索Butten,招聘信息列表页面如下图所示:
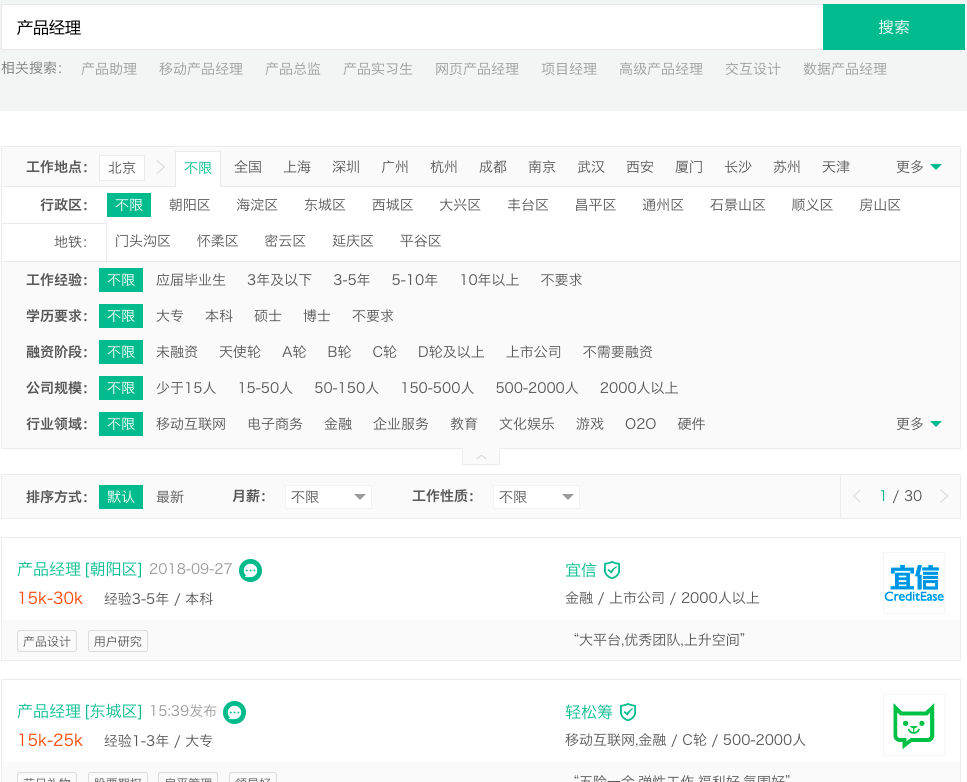
每1页展示15个招聘职位,总展示30页的招聘信息。
结论:所以单次职位的检索,仅可以spider的职位数量为450个招聘职位。
2、我们再看下Html
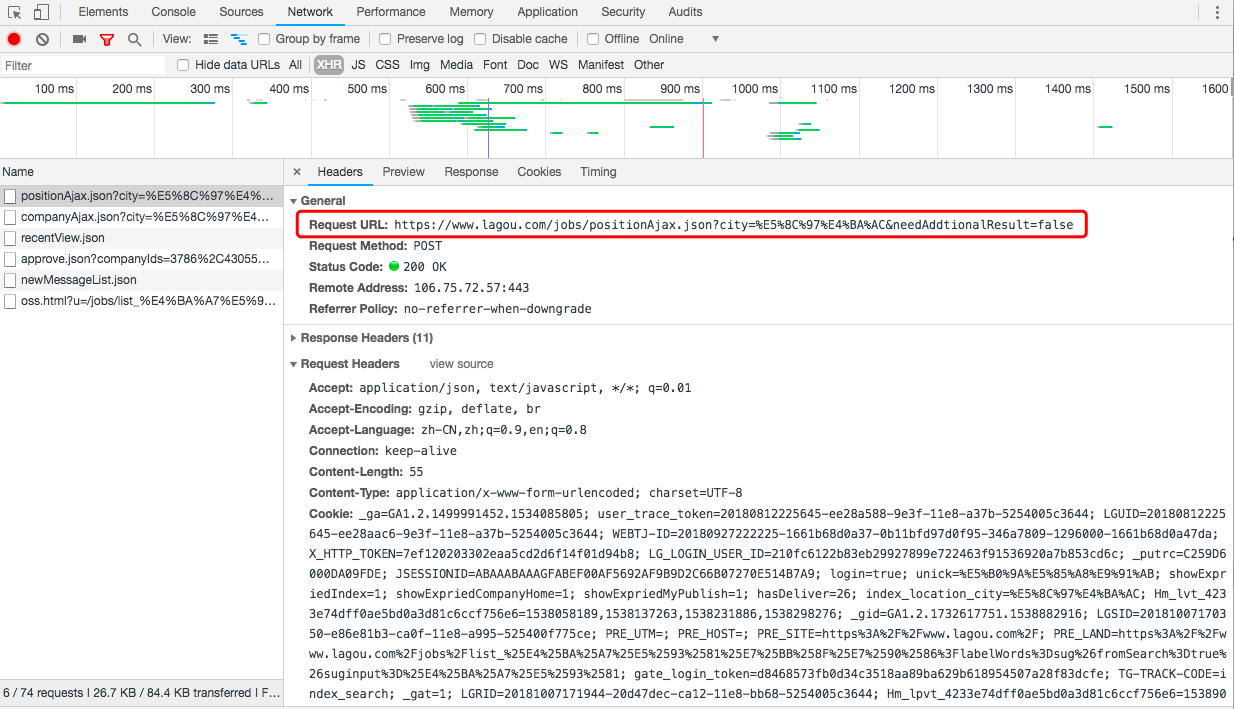
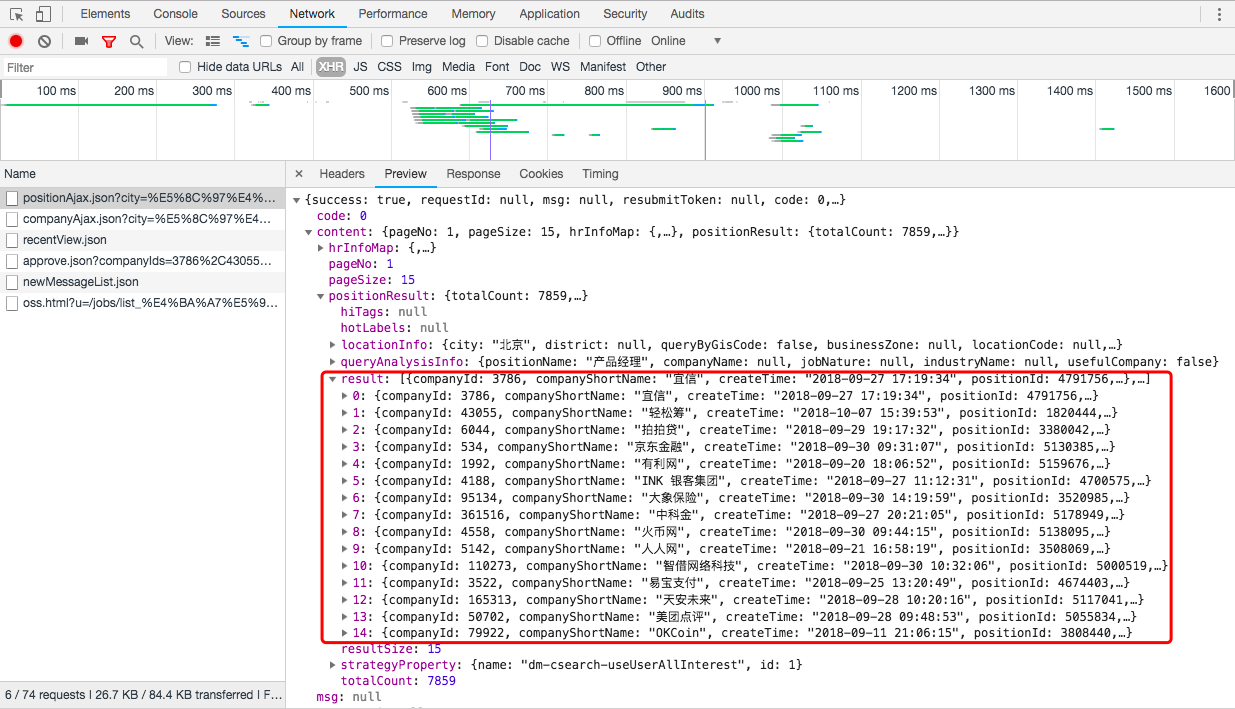
关于页面的Html分析如下:
(1)Request URL:https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false
这个url会是我们本次模拟的Request的url,其中"city=%E5%8C%97%E4%BA%AC"在Query String Parameters(请求参数)中有对应的参数,对应:北京
所以我们本次Request的url可以这样定义:

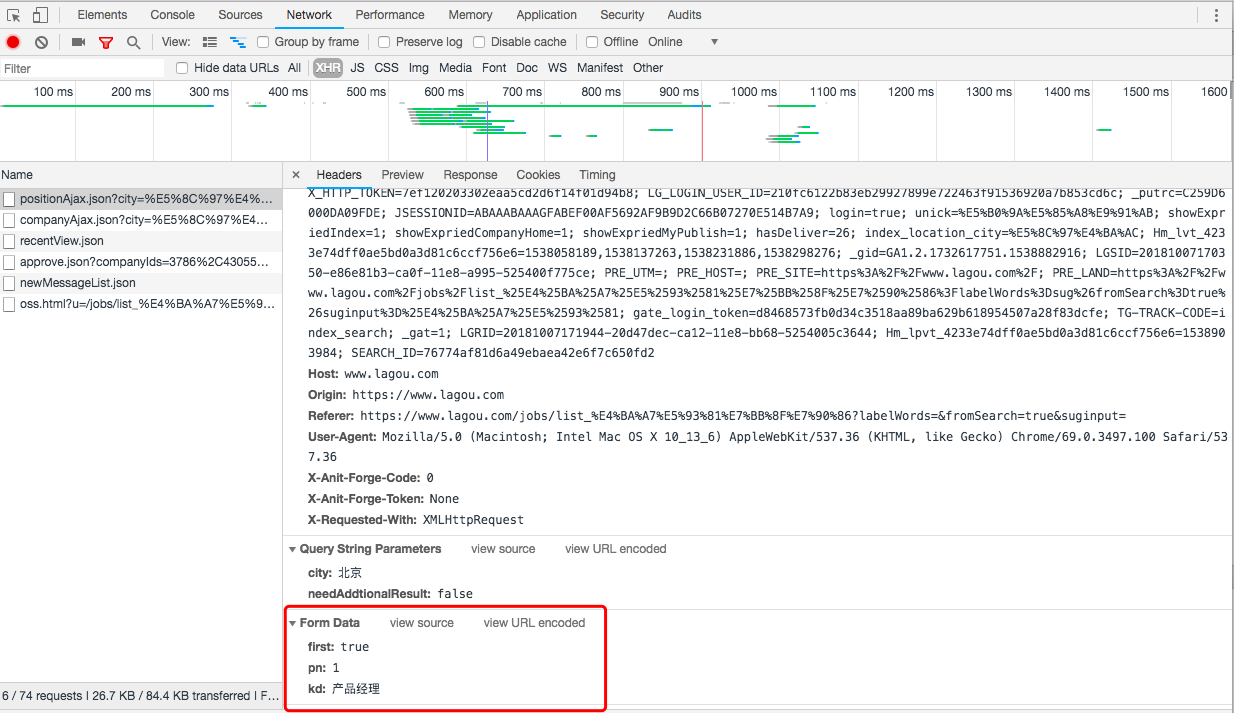
(2)、Form Data的参数
拉勾网将是否是第一次请求、当前的页码,以及输入的招聘职位信息全部包含在Form Data中
从截图看,当前页面是第一页,所以肯定是第一次请求。
我们在看下第二页的参数信息。

当我们点击第二页的时候,请求记录中会多出现一条请求记录,请求的url链接依然是我们上面分析的url,但是Form Data的参数调整为第二页对应的参数,见截图。
所以,在Request请求时,我们就可以按照这个规律拼装Form Data参数。
(3)、result中的惊喜
在url->Preview->content->positionResult->result中(见Html的第三张截图),竟然可以找到页面招聘列表页,我们需要的15个招聘职位信息...这也是拉勾网最让我吃惊的地方,这样让爬取招聘信息变得如此简单。
三、爬取拉钩网实战
先上全部代码,如下:


1 import requests
2 import pandas
3 import time
4 import random
5
6 #用于获取页面信息
7 def getWebResult(url,cookies,form,header):
8 html = requests.post(url=url,cookies=cookies,data=form, headers=header)
9 result = html.json()
10 #找到html中result包含的招聘职位信息
11 data = result['content']['positionResult']['result'] # 返回结果在preview中的具体返回值
12 return data
13
14 #将招聘信息按照对应的参数,组装成字典
15 def getGoalData(data):
16 for i in range(15):#每页默认15个职位
17 info={
18 'positionName': data[i]['positionName'], #职位简称
19 'companyShortName': data[i]['companyShortName'], #平台简称
20 'salary': data[i]['salary'], #职位薪水
21 'createTime': data[i]['createTime'], #发布时间
22 'companyId':data[i]['companyId'], #公司ID
23 'companyFullName':data[i]['companyFullName'], #公司全称
24 'companySize': data[i]['companySize'], #公司规模
25 'financeStage': data[i]['financeStage'], #融资情况
26 'industryField': data[i]['industryField'], #所在行业
27 'education': data[i]['education'], #教育背景
28 'district': data[i]['district'], #公司所在区域
29 'businessZones':data[i]['businessZones'] #区域详细地
30 }
31 data[i]=info
32 return data
33
34 #保存data至笨死csv文件
35 def saveData(data,stage):
36 table = pandas.DataFrame(data)
37 table.to_csv(r'/Users/shang/Desktop/myself/LaGou1.csv', header=stage, index=False, mode='a+')
38
39 def main():
40 # 拼装header信息
41 header = {
42 'Host': 'www.lagou.com',
43 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
44 'Accept': 'application/json, text/javascript, */*; q=0.01',
45 'Accept-Language': 'zh-CN,en-US;q=0.9,en;q=0.8',
46 'Accept-Encoding': 'gzip, deflate, br',
47 'Referer': 'https://www.lagou.com/jobs/list_%E4%BA%A7%E5%93%81%E7%BB%8F%E7%90%86?px=default&city=%E5%8C%97%E4%BA%AC',
48 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
49 'X-Requested-With': 'XMLHttpRequest',
50 'X-Anit-Forge-Token': 'None',
51 'X-Anit-Forge-Code': '0',
52 'Content-Length': '55',
53 'Connection': 'keep-alive',
54 'Pragma': 'no-cache',
55 'Cache-Control': 'no-cache, no-store, max-age=0'
56 }
57 cookies = {
58 'Cookie':' _ga=GA1.2.1499991452.1534085805; user_trace_token=20180812225645-ee28a588-9e3f-11e8-a37b-5254005c3644; LGUID=20180812225645-ee28aac6-9e3f-11e8-a37b-5254005c3644; WEBTJ-ID=20180927222225-1661b68d0a37-0b11bfd97d0f95-346a7809-1296000-1661b68d0a47da; _gid=GA1.2.150811619.1538058146; X_HTTP_TOKEN=7ef120203302eaa5cd2d6f14f01d94b8; LG_LOGIN_USER_ID=210fc6122b83eb29927899e722463f91536920a7b853cd6c; _putrc=C259D6000DA09FDE; JSESSIONID=ABAAABAAAGFABEF00AF5692AF9B9D2C66B07270E514B7A9; login=true; unick=%E5%B0%9A%E5%85%A8%E9%91%AB; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=26; index_location_city=%E5%8C%97%E4%BA%AC; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1538058189,1538137263,1538231886,1538298276; gate_login_token=e052ef59f765dd0dc8e68637d17b953008d587077d8a7f78; TG-TRACK-CODE=search_code; LGSID=20180930224915-006ea101-c4c0-11e8-bb68-5254005c3644; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%25E4%25BA%25A7%25E5%2593%2581%25E7%25BB%258F%25E7%2590%2586%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; SEARCH_ID=3dd73994b82a47be86797e1f001db6c6; _gat=1; LGRID=20180930231820-109f3a78-c4c4-11e8-bb68-5254005c3644; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1538320700'
59 }
60
61
62 # 职位关键字
63 job='产品经理'
64
65 # 职位所属地
66 city = '北京'
67 # 模拟请求的url
68 url = 'https://www.lagou.com/jobs/positionAjax.json?city=' + city + '&needAddtionalResult=false'
69
70 #用于定义开始爬取的起始页码
71 startPage=1
72
73 #拉勾网有个限制,单次只能连续爬取5页,所以使用一个以5页为轮循的小策略
74 while startPage<26:
75 for i in range(startPage, startPage+5):
76 #拼装Form Data信息
77 if i == 1:
78 flag = 'true' #当是首次请求时,使用flag=true标志
79 stage = True #stage是用来标示csv是否创建表头的参数,仅在第一次保存数据时创建
80 else:
81 flag = 'false'
82 stage = False
83 num = i
84 form = {'first': flag, # 标示是否是首次请求标示,第二页以后则为false
85 'kd': job,
86 'pn': str(num)}
87 print('------page %s-------' % i) #打印当面爬取的页码
88
89 #调用函数,获取相应的招聘信息
90 data = getWebResult(url,cookies,form, header)
91 #调用函数,拼装招聘信息
92 data_goal = getGoalData(data)
93 #调用函数,保存info数据
94 saveData(data_goal, stage)
95
96 #以5页为单次,依次轮循
97 startPage+=5
98
99 #休眠一定时间
100 time.sleep(20+random.randint(10,30))
101
102 if __name__ == '__main__':
103 main()
代码比较简单,其实主要分为一下几个步骤:
- 定义url、header、cookie、city、job等基础参数
- 定义Form Data中的参数
- request相应的url,获取相应的招聘职位data信息
- 将data拼装转化成json格式的字典
- 将data保存至本地的csv文件
代码比较简单,并且在代码中已经添加相应的标注说明,所以就不整体介绍了。
有几个踩过的坑在这简单说明下:
(1)、反爬虫
我们在爬取数据的时候,触碰了拉勾网制定的一个简单的反爬虫策略:一次只能连续获取5页的招聘信息。
刚开始爬取的时候,不管从第几页开始,都会在爬取了5页之后,报请求超时...
所以,在程序中设计了一个小小的策略,每次只连续爬取5页,然后暂停几十秒,然后在再从开始下一轮的5页的爬取,直到爬完30页的招聘信息。
(2)、pandas库
本次的数据保存使用的是pandas库,关于该库之强大,是我短时间内无法全部掌握的,所以参考网上经验,仅使用其Dataframe方法中的to_csv()。
另外,需安装pandas库,在终端输入命令:pip install pandas,一步到位
当然前提是需安装pip,Mac安装pip的教程,参见我的另一篇博客:Python自学,番外篇之三 Mac的pip3的安装
pandas参考链接:
1、http://wiki.jikexueyuan.com/project/start-learning-python/312.html
2、https://www.cnblogs.com/misswangxing/p/7903595.html
(3)、Mac对于csv的痛
高高兴兴的下载完招聘信息的csv文件,却发现打开是乱码,顿时慌的一匹...
莫慌,是mac的的默认字符格式不兼容csv,所以,参考下面中方法即可。
亲测好使:
教程链接:https://www.168seo.cn/mac-os/23944.html
打开后的csv文件内容截图如下: 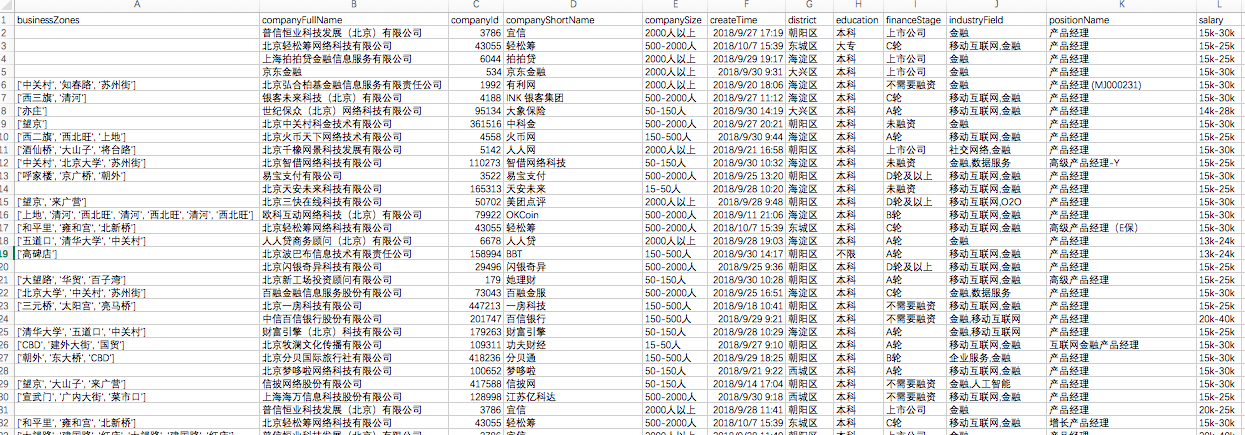
表头的顺序,并不是我设定的顺序,因为字典是无序的...所以,看着很不爽,只能认为的调整列了。
四、总结
9.28开始爬取拉勾网招聘信息,10.1完成450条信息的爬取,拉勾网算是自己实战爬取的比较正规的第一网站,相对来说比较简单。
另外,该方法中,还有很多不足之处,待后续慢慢提升。
最后,再次鸣谢拉勾网,感谢为我提供一个难度适中的实战练手的机会~