@article{nakkiran2019deep,
title={Deep Double Descent: Where Bigger Models and More Data Hurt},
author={Nakkiran, Preetum and Kaplun, Gal and Bansal, Yamini and Yang, Tristan and Barak, Boaz and Sutskever, Ilya},
journal={arXiv: Learning},
year={2019}}
概
本文介绍了深度学习中的二次下降(double descent)现象, 利用实验剖析其可能性.
主要内容

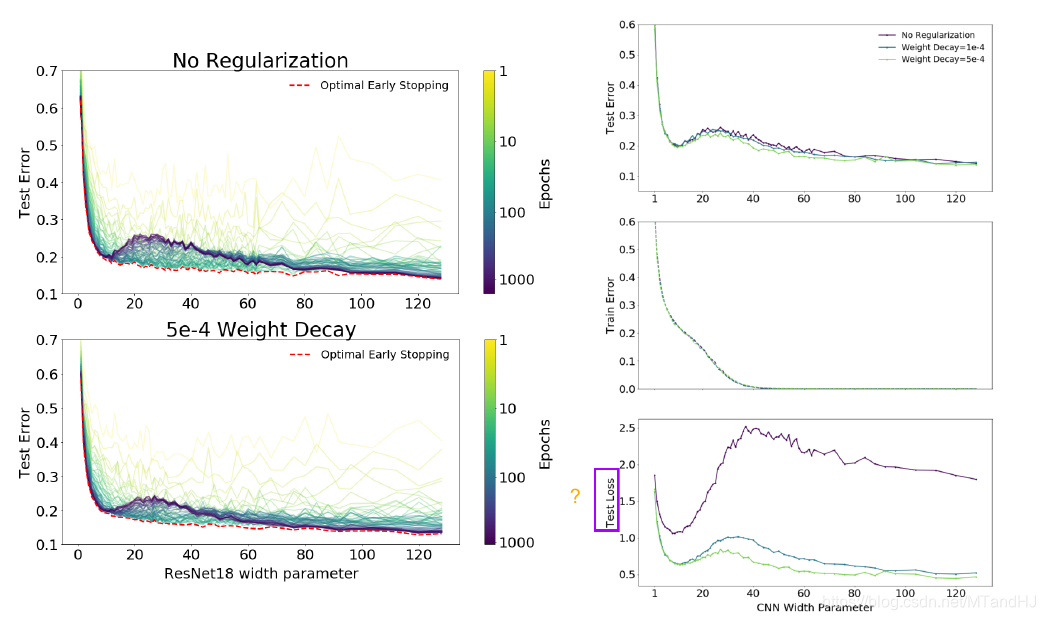
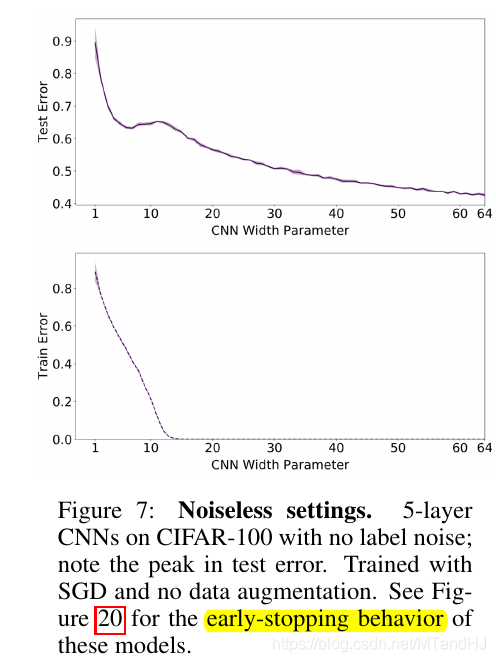
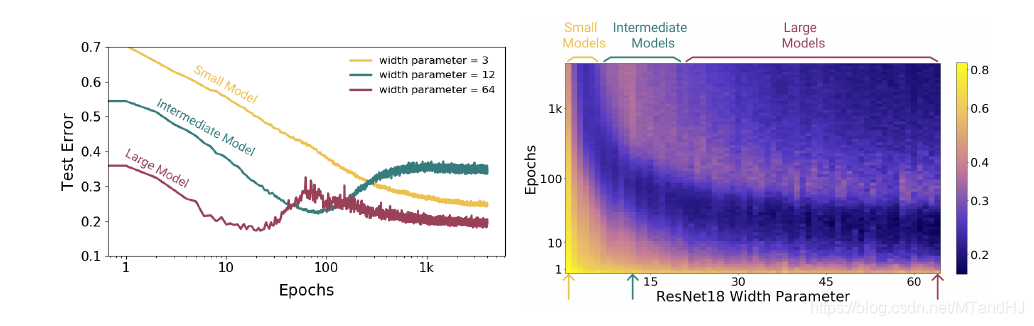
注意到, 在其他条件固定的情况下, 当网络的性能增加(这里指的是ResNet18的参数个数)时, 会出现一中损失率先下降在上升至一个peak再下降的过程.
而右图则向我们展示了, epochs并非越多越好, 如果我们能够即时停止训练, 很有可能就能避免二次下降的现象.
Effective Model Complexity(EMC)
在训练过程(mathcal{T}), 关于数据分布(mathcal{D})与参数(epsilon)下, Effective Model Complexity(EMC)定义为:
其中(mathrm{Error}_S(M))为模型(M)在训练样本(S)上的平均误差.
作者认为, 一个模型(M), 训练样本为(n), (mathrm{EMC}) 比(n)足够小, 或者足够大的时候, 提升(mathrm{EMC}) (即提升模型的性能) 是能够降低测试误差(test error)的, 但是, 在(n)的附近((n-delta_1,n+delta_2))时候, 模型的变化, 既有可能使得模型变好, 也有可能使得模型便坏.
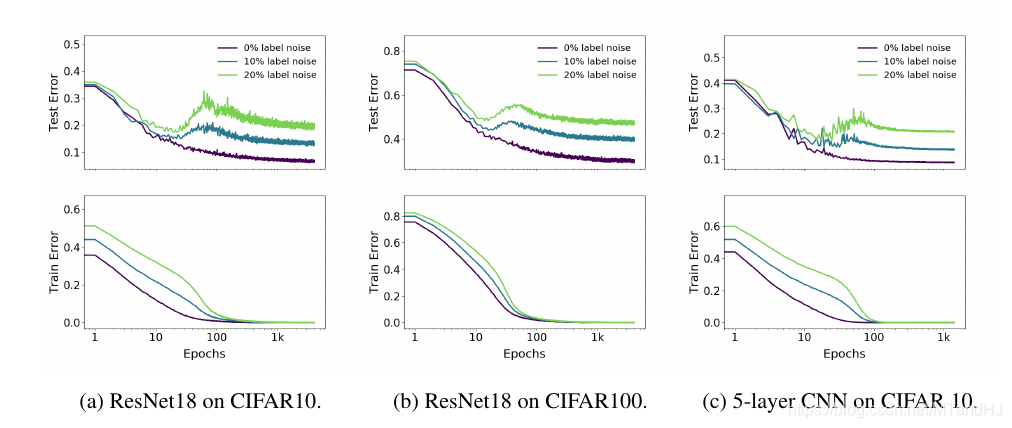
label noise
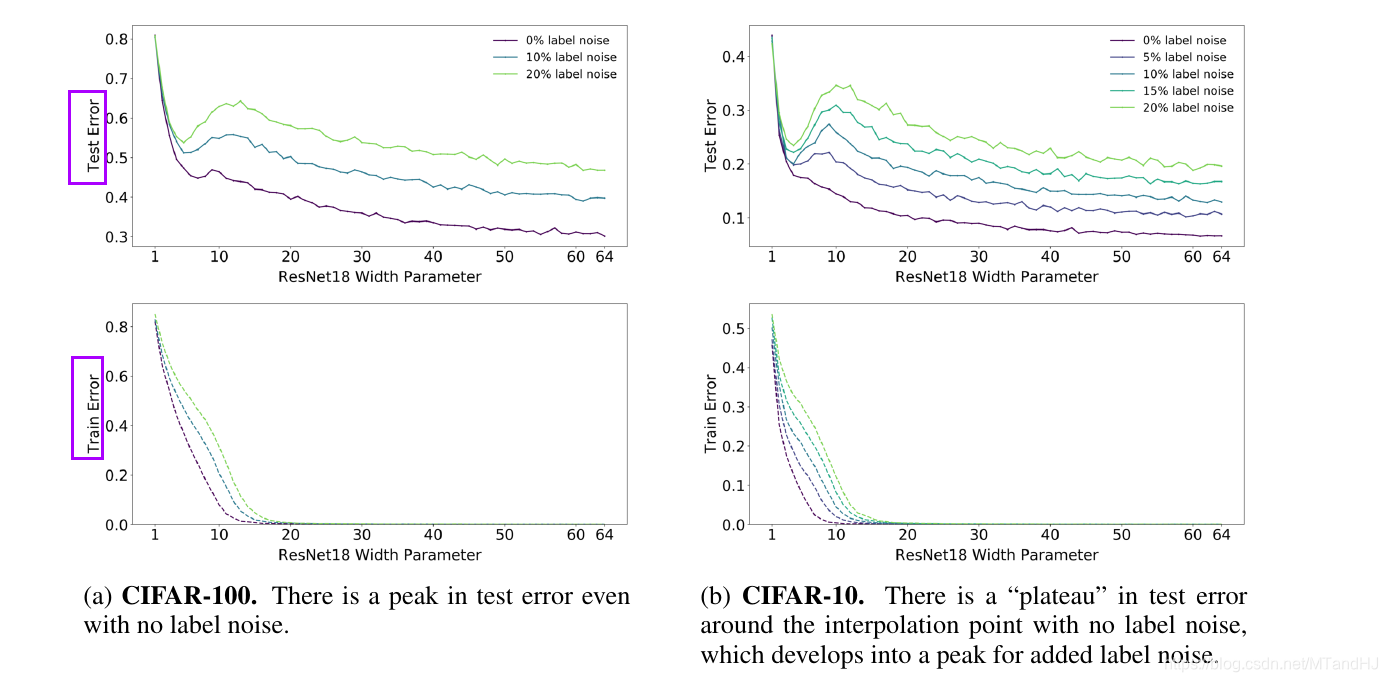
显然, label noise越小越好( 作者认为label noise 会导致模型不易训练), 而且网络的EMC越大(这里指的是网络的参数个数), 对其抗性越好.
data augmentation

显然 data augmentation 能够增加对label noise的抗性.
下降方式
只能说, 下降方式是有较大影响的.
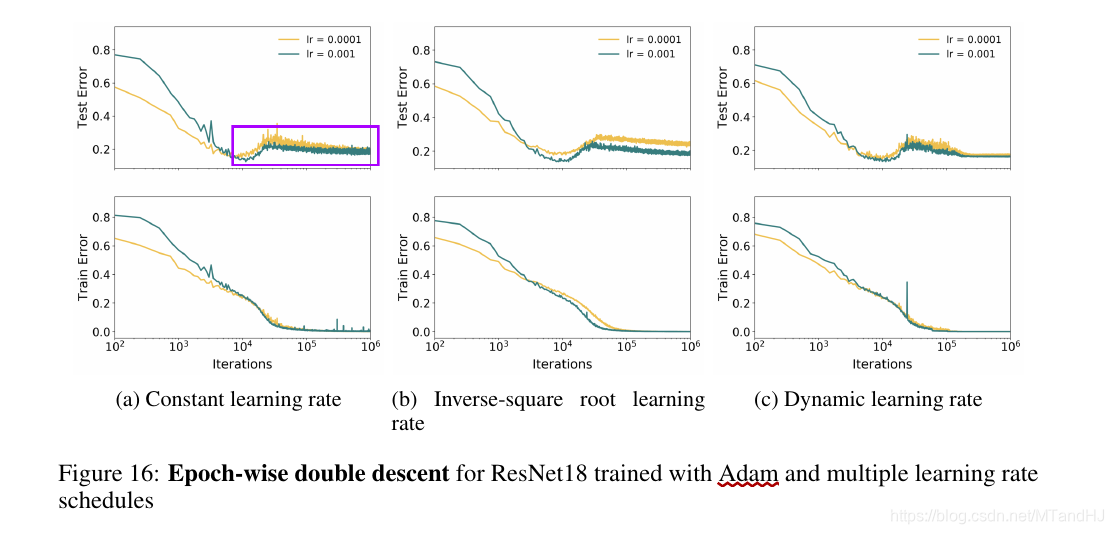
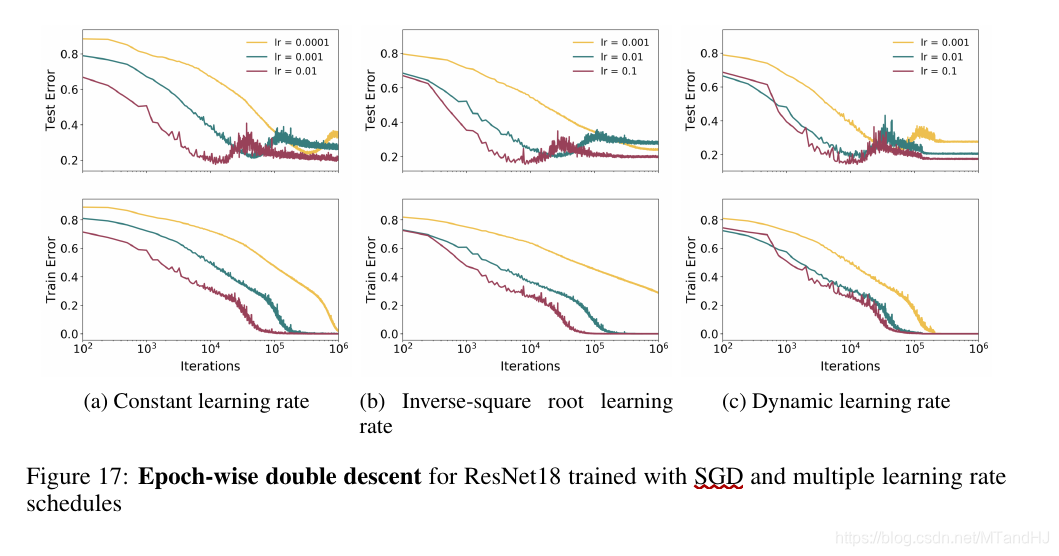
SGD vs Adam

Adam
SGD
SGD + Momentum
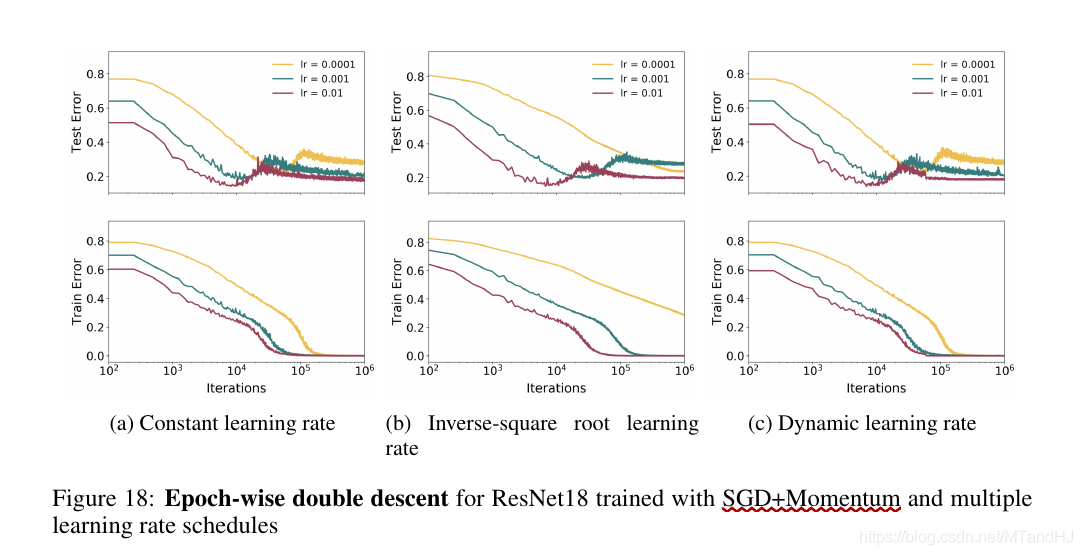
early-stopping
即如果我们能够及早停止训练(适中的epoches)能够避免二次下降的发生, 这一点在Fig 20中体现的淋漓尽致. 但是也并不绝对, 因为Fig 19提供了一个反例.
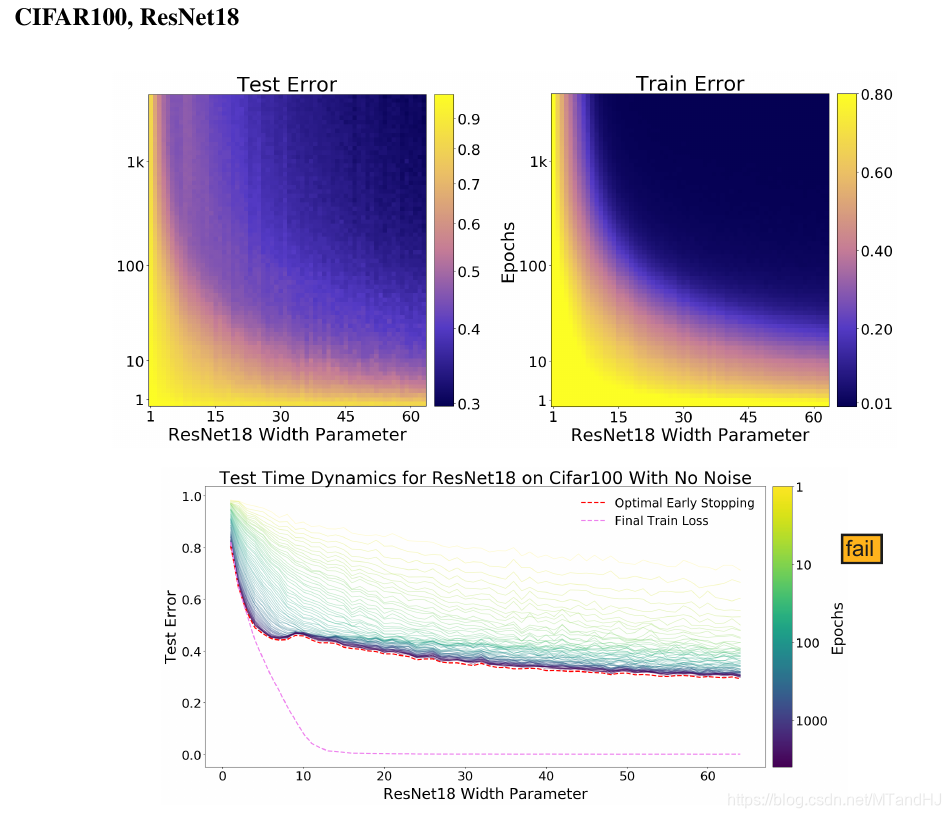
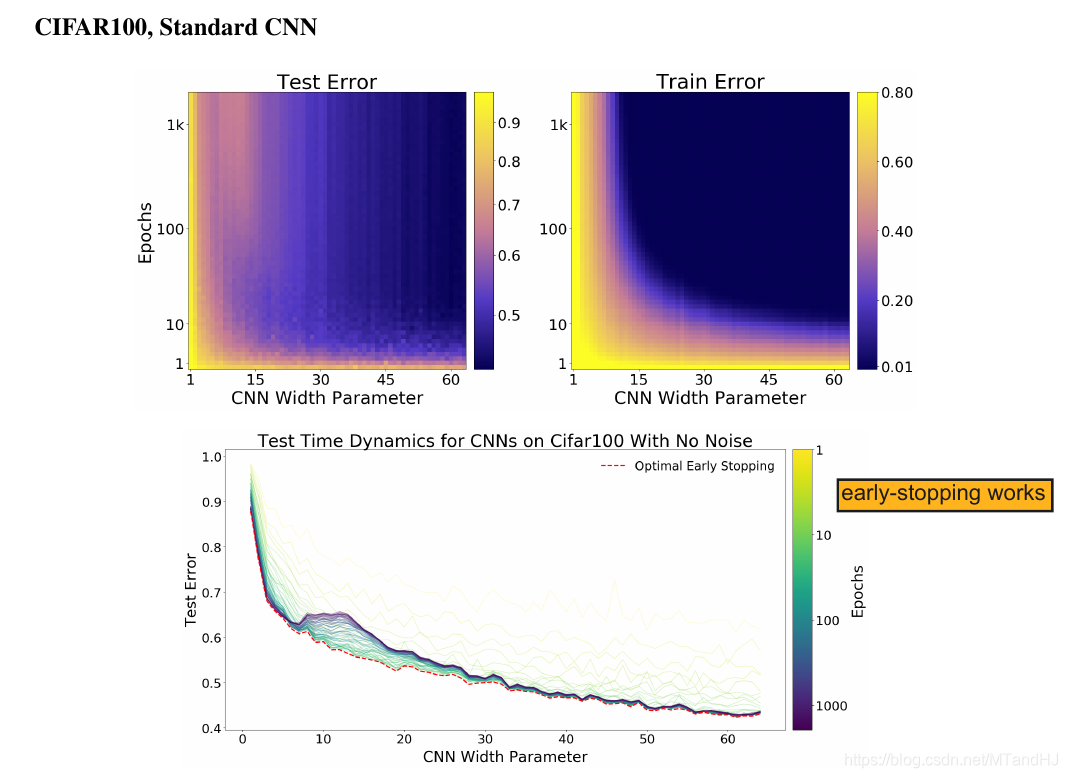
Epoches
显然, 适中的或者尽可能多的epoches是好的.
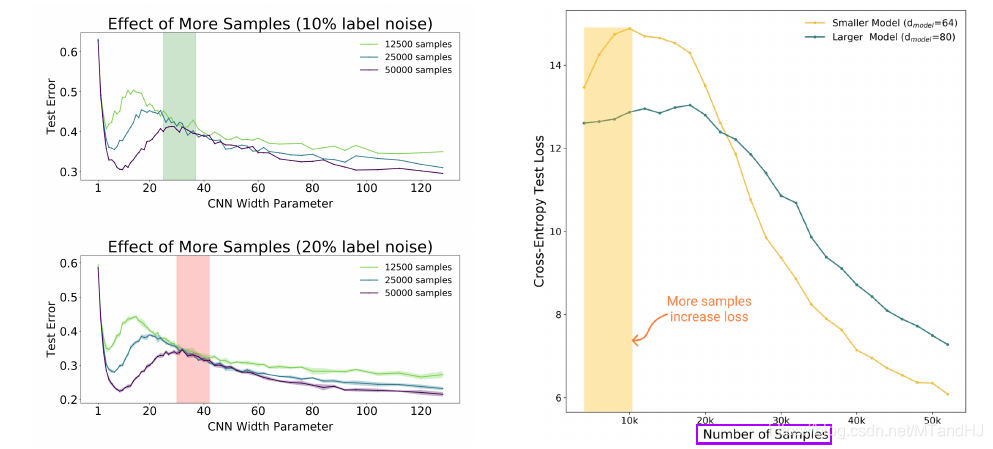
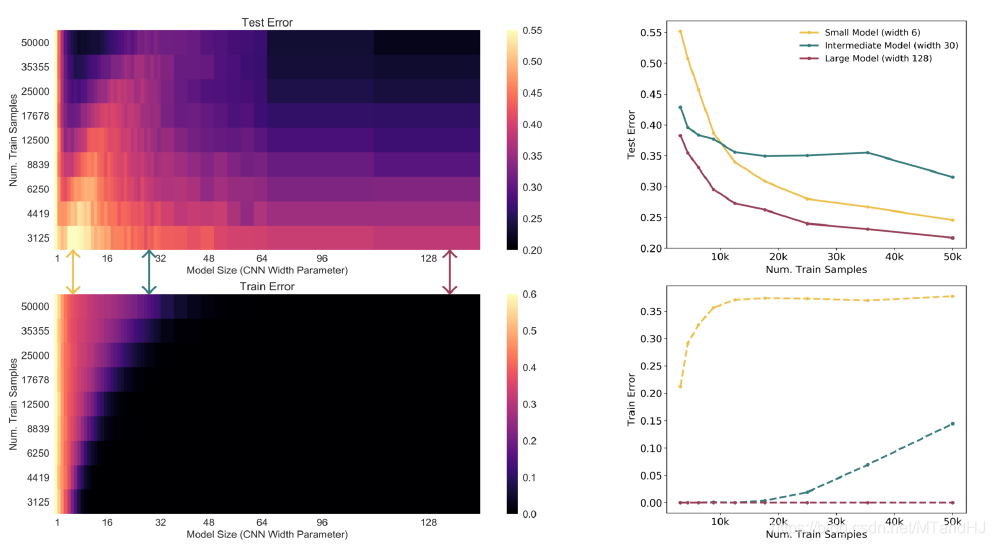
样本数量
对于小型的模型, 增加数据(超出其承受范围)反而会使得模型变差.
weight-decay
weight-decay 对提升EMC是起作用的.