一、模块,包介绍
1、什么是模块(module)
一个py文件就是一个模块
2、为什么要使用模块
一个文件里,函数太多 不好管理,把函数分组,放到模块里,这样便于管理。
3、使用模块的好处:
可维护性高
可重用
避免函数名和变量名重复
4、模块的分类
模块可以分为三类
·内置模块(标准库)
·第三方开源模块
·自定义模块
5、模块的调用方法
import module :直接导入整个模块
from module import xx 模块在某个文件夹里
frome module.xx.xx import xx as rename # 文件下面还有文件夹,点后面跟着子文件。as 后面可以去一个名字,以后调用这个歌模块就直接调用这个名字就可以了。
6、自定义模块
创建一个py文件就可以称为一个模块,在另外一个程序里就可以调用这个模块。
7、模块的查找路径
在上面的情况里,我们发现要导入自定义模块,那这个程序就必须和自定义模块在同一个路径下,换了一个和自定义模块不同路径的程序去调用模块就会报错,这是为什么呢?
8、开源模块的安装、使用、删除
https://pypi.python.org/pypi 是python的开源模块库,注册账户后可以在这里面下载开源模块
下载下来后有两种安装方法
方法一:1、在终端里找到下载后的路径,然后 输入命令:python3 setup.py build (每个开源模块里都会有setup文件)
2、在输入安装口令 python3 setup.pu install
方法二:直接在线安装 终端里输入:
删除开源模块
pip3 install module #先找到有没有这个模块
pip3 uninstall module #删除这个模块
使用国内的镜像源:
方法: 和上面的在线安装类似,只不过语法上要加上你的镜像原
语法:pip3 install -i http://pypi.douban.com/simple/ module --trusted-host pypi.douban.com #使用国内的豆瓣源下载第三方模块,--trusted-host pypi.douban.com表示信任这个网站
9、包(package)
包的作用:当你的模块越来越多的时候,就不好管理。我们就需要文件夹来管理模块,一个文件夹管理多个模块文件,那这个文件夹就叫作包
每个包里必须有__init__ , __init__里面可以没有内容
10、跨模块导入
1 .
2 ├── __init__.py
3 ├── crm
4 │ ├── __init__.py
5 │ ├── admin.py
6 │ ├── apps.py
7 │ ├── models.py
8 │ ├── tests.py
9 │ ├── views.py
10 ├── manage.py
11 └── proj
12 ├── __init__.py
13 ├── settings.py
14 ├── urls.py
15 └── wsgi.py
比如你现在的程序入口是crm下面的views,而这个时候你想调取proj下面的settings模块,那相当于你在sys.path里的路径是在crm/views里,你在你的程序入口如果是from proj import settings是会报错的,因为proj是和crm同一个级别的,系统只会在你crm/views同级别的兄弟里去找,或者兄弟的儿子级别去找,他不能找父亲同级别的
所以该怎么解决呢?
那就是把1、把当前程序的绝对路径找到,2、根据当前程序找到他的爷爷路径 3、把爷爷的路径添加到环境变量里(系统会在添加的路径下面去找包,所以必须添加的是爷爷的路径)
11、绝对导入&相对导入
.
├── __init__.py
├── crm
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── views.py #from ..proj import settings
├── manage.py
└── proj
├── __init__.py
├── settings.py #from .import urls
├── urls.py
└── wsgi.py
当在manage里导入里crm下面的views模块,在views模块里,又需要导入crm下面的models的时候,如果你认为models和views在同一个包里面可以直接导入的话就错了,因为你的主程序是manage,那你直接导入models的话相当于在manage这个目录下去找models。 那是一定会报错的
那该怎么办呢
你可以直接在views里 from . import models 这个.就是绝地导入,因为views和models是同在包下面所以可以决对导入
相对导入:不能作为顶层模块来执行该文件夹中的py文件(即不能作为主函数的入口)。
二、time&datetime模块
1、time模块的方法:
time.localtime()
1 >>> time.localtime()
2 time.struct_time(tm_year=2018, tm_mon=5, tm_mday=10, tm_hour=13, tm_min=9, tm_sec=4, tm_wday=3, tm_yday=130, tm_isdst=0)
将时间戳转换为当前时区的struct_time () struct_time是值时间对象里面是加上时间戳,没填的话就默认是当前时间戳
还可以赋值后单独操作
1 >>> a = time.localtime()
2 >>> a.
3 a.count( a.n_unnamed_fields a.tm_mday a.tm_wday
4 a.index( a.tm_gmtoff a.tm_min a.tm_yday
5 a.n_fields a.tm_hour a.tm_mon a.tm_year
6 a.n_sequence_fields a.tm_isdst a.tm_sec a.tm_zone
7 >>> '%s-%s-%s'%(a.tm_year,a.tm_mon,a.tm_mday)
8 '2018-5-10'
赋值后可以单独操作
time.gmtime()
1 >>> time.gmtime()
2 time.struct_time(tm_year=2018, tm_mon=5, tm_mday=10, tm_hour=5, tm_min=17, tm_sec=44, tm_wday=3, tm_yday=130, tm_isdst=0)
3 >>>
#和time.localtime()方法一样,只不过是将时间转换成UTC时区
time.time()
>>> time.time()
1525929648.49248
>>> time.time()
1525929649.4004831
返回了一个时间戳
time.mktime(t) #将时间对象转换成时间戳 (和time.localtime([secs])是相对的)
time.ctime(3) #让程序停在这里3秒
time.strftime(format[, t]) # 将时间对象转成字符串,括号里的format是你需要转成的时间格式。后面可以加上你需要的时间对象, 注意是对象,如果不加,默认是加上现在的时间对象
1 >>> time.strftime('%Y-%m-%d')
2 '2018-05-10'
3 >>>
没有指定时间对象,那就是默认现在的时间对象。
time.strptime(string[, format]) # 将字符串反转成时间对象,括号里加的是字符串,format是你得告诉他你的字符串是按什么格式的,他才能根据你的格式转换
1 >>> a = time.strftime('%Y-%m-%d')
2 >>> a
3 '2018-05-10'
4 >>> time.strptime(a,'%Y-%m-%d')
5 time.struct_time(tm_year=2018, tm_mon=5, tm_mday=10, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=130, tm_isdst=-1)
将a(时间字符串)传入,并告诉程序是按什么格式的,就会放回a的时间对象,也就是将时间字符串转换成了时间对象
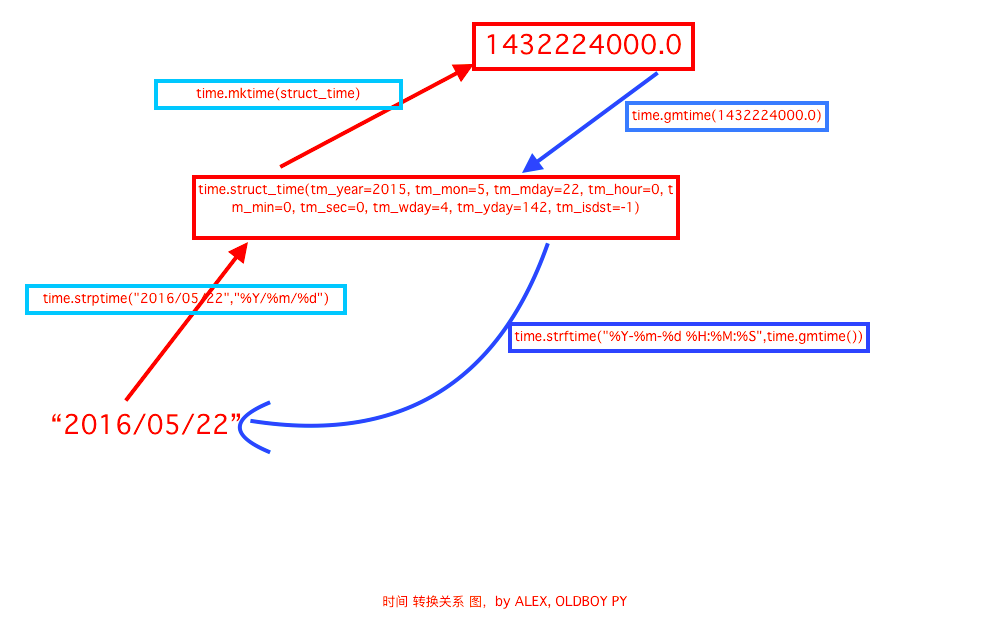
注:‘2016/05/22’是一个时间字符串,红色是将时间字符串转换成>>>时间对象>>>转换成时间戳
1432224000.0是时间戳,蓝色是从时间戳>>>转换成时间对象>>>转换成时间字符串
上图中将时间戳转换成时间对象那里应该是用time.localtime()比较合适 他说当地时区,而time.gmtime()则是用UTC时间。
2、datetime模块
d=datetime.datetime.now() 返回当前的datetime日期类型
1 >>> datetime.datetime.now()
2 datetime.datetime(2018, 5, 10, 15, 39, 36, 21065)
3 >>>
datetime.date.fromtimestamp(322222) 把一个时间戳转为datetime日期类型
1 >>> datetime.date.fromtimestamp(time.time())
2 datetime.date(2018, 5, 10)
3 >>>
这样可以快速的将时间戳转换。
时间运算
datetime.datetime.now()-datetime.timedelta(4) #当前时间减去4天
1 >>> datetime.datetime.now() - datetime.timedelta(4)
2 datetime.datetime(2018, 5, 6, 15, 49, 4, 891202)
3 >>>
还可以加上时间,时间规格可以选择小时
1 >>> datetime.datetime.now() + datetime.timedelta(hours =3)
2 datetime.datetime(2018, 5, 10, 18, 50, 4, 983868)
3 当前时间➕上了3个小时
也可以加上分钟
1 >>> datetime.datetime.now() + datetime.timedelta(minutes =10)
2 datetime.datetime(2018, 5, 10, 16, 1, 11, 387867)
3 >>>
4 ➕了10分钟
但是不能加月
时间替换
可以把现在的时间替换成指定时间
1 > d = datetime.datetime.now()
2 >>> d.replace(year = 2015)
3 datetime.datetime(2015, 5, 10, 15, 54, 37, 196993)
4 >>> d.replace(year = 2015,month =10)
5 datetime.datetime(2015, 10, 10, 15, 54, 37, 196993)
6
7 可以加很多参数
总结:time模块主要用于时间戳和时间字符串和时间对象之间的转换。
datetime模块主要用于运算。
三、random模块
random.randrange(1,10)
random.randint(1,10)
两个都是在1到10中间随机取一个数,不同在于randrange不包含10 ,二randint包含10
random.random() #返回一个随机浮点数
random.choice('数据集合') # 在这个数据集合里随机返回
1 >>> random.choice('akdjf开裆裤34223')
2 'k'
3 >>> random.choice('akdjf开裆裤34223')
4 'd'
5 >>> random.choice('akdjf开裆裤34223')
6 '3'
7 >>> random.choice('akdjf开裆裤34223')
8 '2'
9 >>> random.choice('akdjf开裆裤34223')
10 '裆'
11 >>> random.choice('akdjf开裆裤34223')
12 '开'
13 >>>
random.sample('数据集合',3) 在这个数据集合里返回3个随机字符
生成随机字符串
1 #生成随机字符串
2 >>> import string
3 >>> ''.join(random.sample(string.ascii_lowercase + string.digits, 6))
4 '4fvda1'
洗牌
1 #洗牌
2 >>> a
3 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
4 >>> random.shuffle(a)
5 >>> a
6 [3, 0, 7, 2, 1, 6, 5, 8, 9, 4]
四、os模块
得到当前工作目录,即当前Python解释器工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
将文件名与路径分开
1 分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
2
3 把后缀名和文件分开了
1 获取路径名:os.path.dirname()
1 获得绝对路径: os.path.abspath()
1 >>> os.system('df -h')
2 Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
3 /dev/disk1s1 113Gi 41Gi 68Gi 38% 765554 9223372036854010253 0% /
4 devfs 186Ki 186Ki 0Bi 100% 643 0 100% /dev
5 /dev/disk1s4 113Gi 3.0Gi 68Gi 5% 3 9223372036854775804 0% /private/var/vm
6 map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
7 map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
8 0
9 >>>
10
11
12 执行系统命令
1 读取操作系统环境变量HOME的值:os.getenv("HOME")
2
3 os.getenv() 可以拿到操作系统里的环境变量
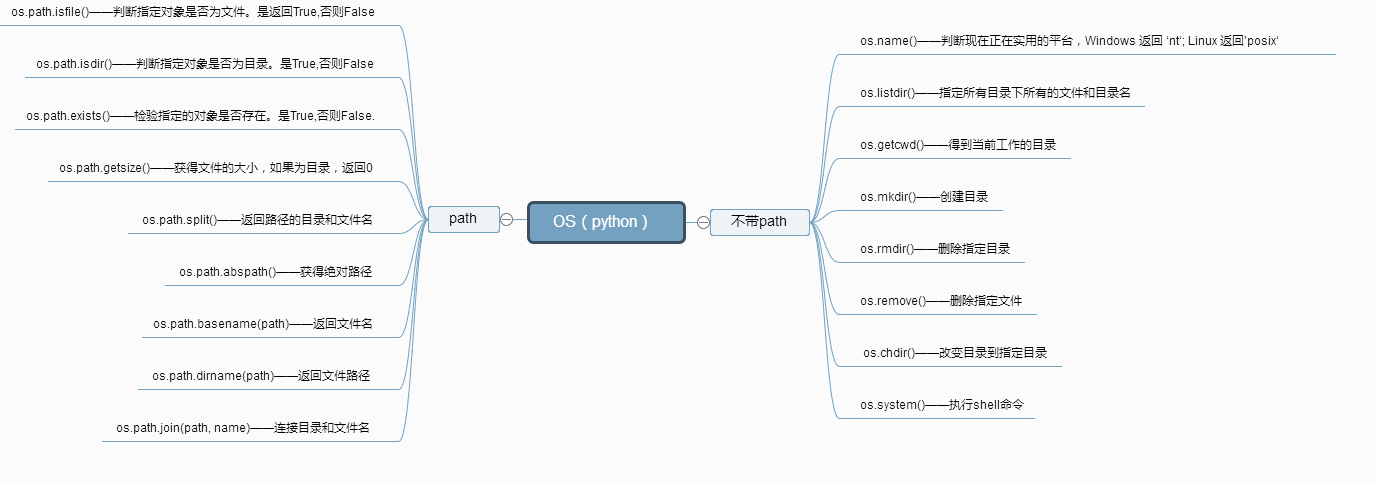
os.path.isfile() #在括号里加上路径+文件 判断是否为文件,不加路径就是当前路径下的文件
os.path.isdir() #在括号里加上一个路径,判断是否为路径。
os.path.getsize() # 括号里加上文件,返回该文件的大小
将文件的路径和文件名返回
1 import os 2 # print(__file__) 3 print(os.path.split('/Users/crazy_heng/PycharmProjects/untitled/exercise/ 4 5 输出 6 ('/Users/crazy_heng/PycharmProjects/untitled/exercise/crm', 'new_module.py')
输入路径+文件名时 只返回文件名
1 import os 2 print(os.path.basename('/Users/crazy_heng/PycharmProjects/untitled/exercise/crm/new_module.py')) 3 4 输出 5 new_module.py
输入路径+文件名时 只返回路径
1 import os 2 print(os.path.dirname('/Users/crazy_heng/PycharmProjects/untitled/exercise/crm/new_module.py')) 3 4 输出 5 /Users/crazy_heng/PycharmProjects/untitled/exercise/cr
五、sys模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径
2 sys.exit(n) 退出程序,正常退出时exit(0)
3 sys.version 获取Python解释程序的版本信息
4 sys.maxint 最大的Int值 py3改成sys.maxsize
5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
6 sys.platform 返回操作系统平台名称
7 sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
8 val = sys.stdin.readline()[:-1] #标准输入
9 sys.getrecursionlimit() #获取最大递归层数
10 sys.setrecursionlimit(1200) #设置最大递归层数
11 sys.getdefaultencoding() #获取解释器默认编码
12 sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
六、shutil模块
shutil.copyfileobj(fsrc, fdst[, length]) #将文件内容拷贝到另外一个文件中
1 import shutil
2
3 f = open('exercise.py','r')
4 f1 = open('exercise_new','w')
5
6 shutil.copyfileobj(f,f1)
7
8
9 这样f里的文件就会拷贝到f1中
shutil.copyfile(src, dst) #拷贝文件
1 import shutil
2
3 shutil.copyfile('account.txt','account2.txt')
4
5
6 和上个方法比,他只要输入文件名就可以把内容拷贝了
shutil.copy # 拷贝文件和权限
1 shutil.copy(src, dst) 2 拷贝文件和权限 3 4 import shutil 5 shutil.copy('f1.log', 'f2.log')
shutil.copytree() #拷贝整个文件夹
1 import shutil
2
3 shutil.copytree('exercise','exercise2',ignore=shutil.ignore_patterns('__init__','view.py'))
4
5 这里需要注意一下你的程序路径,你不输入路径能否可以找到你指定的文件
压缩文件
1 import shutil
2
3 shutil.make_archive('crm5','zip','crm4')
七、序列化模块
为什么要序列化:
因为硬盘上只能存储字符串和bytes类型的数据)那想把内存上的数据存到硬盘上就得序列化,从硬盘上读取数据到内存上就得反序列化
把内存数据转成字符串就是序列化
把字符串转成内存数据就是反序列化
json模块
dumps(obj)
用法: 将内容数据类型转成字符串 json.dumps
1 import json
2 data = {1:2,3:4,5:6}
3
4 d = json.dumps(data)
5 print(type(d))
我们看到经过dumps 后data的类型已经变成字符串了
dump(obj,fp)
dump和dumps的不同之处在于dumps只是把内存数据转换成字符串,而dump可以直接写到文件里,obj 是内存数据转成字符串后的文件内容,fp就是这个文件。
1 import json
2 data = {1:2,3:4,5:6}
3
4
5 f = open('account_new.json','w',encoding='utf-8')
6 d = json.dump(data,f)
这样我们就可以直接把data里的内容写到account_new这个文件里了
这里还需要注意一点,存放json数据的文件约定俗成的规定以json结尾,只要看到是json结尾的文件就知道这是json数据
json.loads()
将字符串转换成他原本的内存数据格式
1 import json
2 data = {1:2,3:4,5:6}
3 # f = open('account_new.json','w',encoding='utf-8')
4 d = json.dumps(data)
5
6 d2 = json.loads(d)
7 print(d2['3'])
我们看,loads以后就可以根据字典的key取到valus了
json.load(fp)
直接将文件里的数据格式化读出来
1 import json
2 data = {1:2,3:4,5:6}
3 f = open('account_new.json','r',encoding='utf-8')
4 f1 = json.load(f)
5 print(f1['3'])
json.dumps的意义,因为dumps只是把内存里的数据转换成字符串存在了内存里,这有什么意义呢?
它的意义在于1、网络传输的时候只能传字符串,所以可以用来传输数据。
2、跨平台操作,定义了不同语言之间的交互规律
要注意的是在json里 一个数据只能dump 和load一次,不能多次使用。
pickle模块
pickle的用法和json是一样的 4种用法:dump dumps load loads
要注意的是 pickle.dumps的时候转换出来的不是字符串而是bytes类型,同样dump写入文件的时候文件必须是wb格式,
pickle.loads同样也只能将bytes类型转换成内存原有类型,而使用pickle.load读文件的时候也必须是rb模式
同样只能load或者dump一次
pickle与json的不同之处在于:
json只支持str dict list int tuple 可以跨平台
pickele支持python的所有数据格式 但是不能跨平台只能在python里使用
shelve模块
shelve和上面两个的区别在于它可以多次持久化
序列化:
1 import shelve
2
3 f = shelve.open('shelve_test') # 打开一个文件
4
5
6
7 names = ["alex", "rain", "test"]
8 info = {'name':'alex','age':22}
9
10
11 f["names"] = names # 持久化列表
12 f['info_dic'] = info
13
14 f.close()
反序列化:
1 import shelve
2
3 d = shelve.open('shelve_test') # 打开一个文件
4
5 print(d['names'])
6 print(d['info_dic'])
7
8
9 #del d['test'] #还可以删除
八、xml模块
xml和json差不多,只是以前没有json的时候都用xml来实现跨平台
1 import xml.etree.ElementTree as ET
2
3 tree = ET.parse("xmltest.xml")
4 root = tree.getroot()
5 print(root.tag)
6
7 #遍历xml文档
8 for child in root:
9 print(child.tag, child.attrib)
10 for i in child:
11 print(i.tag,i.text)
12
13 #只遍历year 节点
14 for node in root.iter('year'):
15 print(node.tag,node.text)
修改和删除xml文档内容
1 import xml.etree.ElementTree as ET
2
3 tree = ET.parse("xmltest.xml")
4 root = tree.getroot()
5
6 #修改
7 for node in root.iter('year'):
8 new_year = int(node.text) + 1
9 node.text = str(new_year)
10 node.set("updated","yes")
11
12 tree.write("xmltest.xml")
13
14
15 #删除node
16 for country in root.findall('country'):
17 rank = int(country.find('rank').text)
18 if rank > 50:
19 root.remove(country)
20
21 tree.write('output.xml')
自己创建xml文档
1 import xml.etree.ElementTree as ET
2
3
4 new_xml = ET.Element("namelist")
5 name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
6 age = ET.SubElement(name,"age",attrib={"checked":"no"})
7 sex = ET.SubElement(name,"sex")
8 sex.text = '33'
9 name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
10 age = ET.SubElement(name2,"age")
11 age.text = '19'
12
13 et = ET.ElementTree(new_xml) #生成文档对象
14 et.write("test.xml", encoding="utf-8",xml_declaration=True)
15
16 ET.dump(new_xml) #打印生成的格式
九、configparser模块
解析配置文件
1 ```py
2 >>> import configparser # 导入模块
3 >>> config = configparser.ConfigParser() #实例化(生成对象)
4 >>> config.sections() #调用sections方法
5 []
6 >>> config.read('example.ini') # 读配置文件(注意文件路径)
7 ['example.ini']
8 >>> config.sections() #调用sections方法(默认不会读取default)
9 ['bitbucket.org', 'topsecret.server.com']
10 >>> 'bitbucket.org' in config #判断元素是否在sections列表内
11 True
12 >>> 'bytebong.com' in config
13 False
14 >>> config['bitbucket.org']['User'] # 通过字典的形式取值
15 'hg'
16 >>> config['DEFAULT']['Compression']
17 'yes'
18 >>> topsecret = config['topsecret.server.com']
19 >>> topsecret['ForwardX11']
20 'no'
21 >>> topsecret['Port']
22 '50022'
23 >>> for key in config['bitbucket.org']: print(key) # for循环 bitbucket.org 字典的key
24 ...
25 user
26 compressionlevel
27 serveraliveinterval
28 compression
29 forwardx11
30 >>> config['bitbucket.org']['ForwardX11']
31 'yes'
32 ```
其它增删改查语法
1 ```python
2 [group1] # 支持的两种分隔符“=”, “:”
3 k1 = v1
4 k2:v2
5
6 [group2]
7 k1 = v1
8
9 import ConfigParser
10
11 config = ConfigParser.ConfigParser()
12 config.read('i.cfg')
13
14 # ########## 读 ##########
15 #secs = config.sections()
16 #print(secs)
17 #options = config.options('group2') # 获取指定section的keys
18 #print(options)
19
20 #item_list = config.items('group2') # 获取指定 section 的 keys & values ,key value 以元组的形式
21 #print(item_list)
22
23 #val = config.get('group1','key') # 获取指定的key 的value
24 #val = config.getint('group1','key')
25
26 # ########## 改写 ##########
27 #sec = config.remove_section('group1') # 删除section 并返回状态(true, false)
28 #config.write(open('i.cfg', "w")) # 对应的删除操作要写入文件才会生效
29
30 #sec = config.has_section('wupeiqi')
31 #sec = config.add_section('wupeiqi')
32 #config.write(open('i.cfg', "w")) #
33
34
35 #config.set('group2','k1',11111)
36 #config.write(open('i.cfg', "w"))
37
38 #config.remove_option('group2','age')
39 #config.write(open('i.cfg', "w"))
40 ```
十、hashlib模块
hashlib模块
md5算法:输入任意长度后经过处理返回一个128位的信息即(数字指纹)
python3中hashlib常用方法:
import hashlib
m = hashlib.md5() #调用md5
m.update(b'alex') #传值 传的值必须是byte,所以前面加个b或者也可以alex.encode()
m.hexdigest() #生成16进制的格式
m.digest() #生成2进制的格式
十一、subprocess模块
十二、logging模块
1、向屏幕输出日志
1 import logging
2
3 logging.warning("user [alex] attempted wrong password more than 3 times")
4 logging.critical("server is down")
Level When it’s used
DEBUG Detailed information, typically of interest only when diagnosing problems.
INFO Confirmation that things are working as expected.
WARNING An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected.
ERROR Due to a more serious problem, the software has not been able to perform some function.
CRITICAL A serious error, indicating that the program itself may be unable to continue running.
2、把日志写到文件里
把日志写入文件的语法:
logging.basicConfig(filename = '文件名',level = logging.INFO)
logging.warning('日志内容')
logging.debug('日志内容')
也可以自定义格式:
自定义格式
logging.basicConfig(filename = '文件名子',level = logging.INFO,
format = %(asctime)s %(message)s
datefmt =datefmt='%Y-%m-%d ')
logging.warning('日志内容')
logging.debug('日志内容')
其中,format:记录日志的格式,日志最终用什么格式根据它来,相当于一个占位符,里面除了加%(asctime)s, 还可以加上一大堆自定义格式,datefmt是对时间格式自定义
3、同时向屏幕和文件输出日志
同时向文件和屏幕发日志
1、生成logger对象
logger = logging.getLogger('web')
2、生成handler对象
ch = logging.StreamHandler() #向屏幕输出
fh = logging.FileHandler('输出的文件名.log') #向文件输出
2.1、把handler对象绑定到logger
logger.addHandler(ch)
logger.addHandler(fh)
3、生成formatter对象
formatter = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s' )
3.1、把formatter对象绑定到handler对象
ch.setFormatter(formatter)
fh.setFormatter(formatter)
#执行 输出 logger.debug('输出内容')
十三、re模块
re模块 match 和search re.match 从头(第一个)开始匹配 re.search 从全局开始匹配 如果想拿到匹配结果,首先德判断是否匹配上了 match_res = re.search('d',s) 因为匹配到了会返回结果,而没有匹配上会返回None 所以: if match_res: #这样就表示匹配上了 pint(match_res.grou()) # 在后面加上grou就是返回匹配的结果。 '.'匹配除了 以外的任意结果 # 匹配字符数字什么的都会匹配上 '^' 从头开始匹配 类似于match # re.search('^ab','abb') 匹配上了 ab 也等同于 re.match('ab','abb') '$' 匹配结尾 # re.search('b$',abb) 匹配上了结尾的b re.match('b$',b) #表示以b开头b结尾 '*' #匹配*前一个字符 0次或多次,如果没有他也算匹配上, 只是grou会得到一个空字符串 '+' #匹配+前一个字符1次或多次 有多少个就匹配多少个,没有匹配上就不会返回值 '?' #匹配前一个字符0次或1次,不管匹配到多少个只匹配一次,没有的话也会返回一个空字符串 '{m}' #匹配前一个字符m次,也就是可以匹配前一个字符随便多少次 '{n,m}' #匹配前一个字符n-m次 从左到右匹配,能匹配最高多少次就匹配最高次 '|' # 匹配|左或|右的字符 例子:re.search('alex|Alex',alex) 返回alex re.search('[a|A]lex',Alex) 返沪Alex 分组匹配: re.search('(D+)(d+)', 'alex123').groups() >>>('alex', '123') # 在条件外面加上括号并后面加上.groups() 这种加括号必须和groups()配合使用 re.split()按照设置的条件去拆分 >>> re.split('d+', 'jacke11alex23rain33',maxsplit=2) ['jacke', 'alex', 'rain', ''] maxsplit = 2 #表示只替换2次,后面的不替换 按特殊字符来拆分的话需要转译 >>> re.split('|', 'alex|jack') ['alex', 'jack'] 其中很特殊: >>> re.split('\\', 'alexjack') ['alex', 'jack'] # 需要加3个 re.sub(‘替换的条件d’, ‘替换成’, 替换的整个字符串, count= 3) # 按照设置的去替换 >>> s 'alex22jack23jingxing50|lkje' >>> re.sub('d','=',s) 'alex==jack==jingxing==|lkje count = 3 #是表示只替换3个后面的不替换 re.fullmatch(pattern, string) 整个字符串匹配成功就返回re object, 否则返回None re.fullmatch('w+@w+.(com|cn|edu)',"alex@oldboyedu.cn") >>>True re.compile方法: prog = re.compile(pattern) # 先把条件设置一个变量 result = prog.match(string) # 再拿这个变量去目标字符串里匹配 等同于: result = re.match(pattern, string) compile的优势在于匹配大数据的时候,速度会快 Flags标志符 re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) 例子:>>> re.search('a','Alex',re.I).group() 'A' M(MULTILINE): 多行模式,改变'^'和'$'的行为 S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline. >>> re.search('.',' ',re.S).group() ' ' re.M可以让'.'匹配 换行 这样'.'就是真正意义可以匹配全部 X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样 >>> re.search('d+ # 这是注释','322',re.X).group() '322' 加上了re.X 他会把条件里面#后面忽略掉 也就是让#后面变成注释
序列化模块
序列化模块 序列化:把内存里的数据类型转换成字符串(硬盘只接受字符串和bytes),以使其能储存到硬盘或通过网络传输。 json pickle shelve json和pickle用法完全一样 json用法: json.dumps(data) 将data的数据类型自动变成字符串,应便可以存入文件 json.dump(data,f) #f= opne('文件名.json','w') 这里需要注意的是序列化文件约定俗成的规定以json结尾,让人知道这里面的数据是通过json序列化得来的。 dump的用法是将data序列化成字符串,按f的文件自动写入文件 json.loads(文件里的数据) 将文件里的数据按本身自己的格式转换回来 data = json.load(f) # f= opne('文件名.json','r') 直接将文件里的数据按原本格式读出来 json.dumps 只是把数据类型转成字符串存到内存里的意义? 意义一:把内存数据可以通过网络共享给远程其他人(网络传输只能传字符串) 意义二:定义了不同语言之间的交互规则 json简单可读性高。 iu json 支持的数据类型 str,int,tuple,list,dict 可以跨平台 pickle 支持python里所有的数据类型,但是只能在python里使用,无法跨平台 shelve模块 对pickle进行的封装,只能在python里使用 可以多次dump和load
configparser模块
configparser模块 对configparse(配置文件)的增删改查和字典差不多 他有几个大块 这个块叫做section 第一步:需要生成对象 conf = configparser.ConfigParser() 第二步:读取配置文件 conf.read('配置文件名字.iti') 第二步:读取对象 conf["section"] conf.sections() 调用sections方法,默认是不读default的 判断有没有某个模块 if "xxx" in conf["xxx"] 增加: conf.add_section("增加的section") conf["增加的section"]["k2"] = "v2" # 在新增加的section里增加一个k2, 它的值是v2 configparser里的值必须是字符串 增加完以后再写回文件: conf.write(open("文件名.iti,‘w")) 删除: 删除有两种 一种是指定删除,一种是吧整个section都删掉 conf.remove_option("xxsection","k2") 删完后要写回文件 conf.write(open("文件名.iti", "r")) 另外一种删除: conf.remove_section("xxsection") # 这整个section下面的值都被删掉了 写回文件: conf.write(open("文件名.iti", "r")) # 可以写新文件,写原文件名就覆盖掉了
hashlib模块
hashlib模块 md5算法:输入任意长度后经过处理返回一个128位的信息即(数字指纹) python3中hashlib常用方法: import hashlib m = hashlib.md5() #调用md5 m.update(b'alex') #传值 传的值必须是byte,所以前面加个b或者也可以alex.encode() m.hexdigest() #生成16进制的格式 m.digest() #生成2进制的格式
logging模块
logging 模块 logging日志可以分为5个级别 1、debug() 2、info() 3、warning() 4、error() 5、critical() 简单用法,直接在屏幕上输出 logging.warning('日志内容') logging.debug('日志内容') ..... 把日志写入文件的语法: logging.basicConfig(filename = '文件名子',level = logging.INFO) logging.warning('日志内容') logging.debug('日志内容') 其中 filename是给日志文件取名,一般以.log结尾, level代表等级,只写入INFO和比INFO级别高的内容。 自定义格式 logging.basicConfig(filename = '文件名子',level = logging.INFO, format = %(asctime)s %(message)s datefmt =datefmt='%Y-%m-%d ') logging.warning('日志内容') logging.debug('日志内容') 其中,format:记录日志的格式,日志最终用什么格式根据它来,相当于一个占位符,里面除了加%(asctime)s, 还可以加上一大堆自定义格式,datefmt是对时间格式自定义 同时向文件和屏幕发日志 1、生成logger对象 logger = logging.getLogger('web') 2、生成handler对象 ch = logging.StreamHandler() fh = logging.FileHandler('输出的文件名.log') 2.1、把handler对象绑定到logger logger.addHandler(ch) logger.addHandler(fh) 3、生成formatter对象 formatter = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s' ) 3.1、把formatter对象绑定到handler对象 ch.setFormatter(formatter) fh.setFormatter(formatter) #执行 输出 logger.debug('输出内容') 将日志截断: 生成handler对象这里还可以选择过滤条件,限制日志大小或者限制日志时间 写法和上面一样,要先导入一个模块 from logging import handlers 生成handler对象: 按大小截断 fh = handlers.RotatingFileHandler(filename="日志文件名.log",maxBytes=10,backupCount=3) 其他和普通方法一样,这里maxBytes代表每个日志不能超过10个字节,backupCount代表不能超过3份 按时间截断: fh = handlers.TimeRotatingFileHandler(filename="日志文件名.log",when ="s",interval = 5,backupCount= 3) when = 代表时间单位 可以是秒S也可以是小时H interval 代表了时间是多少
random模块
random模块 1、random.randrange(1,10) 在1-10中返回一个随机数 不包含10 2、random.randint(1,10) 在1-10中返回一个随机数 包含10 3、random.random() 返回一个随机浮点数 4、random.choice("dslkjf23r9d") 在指定的数据里返回一个字符 5、random.sample('asdf324', 5) 在指定的字符中选取特定数量的字符 6、import string ''.join(random(string.ascii_letters+string.digits, 6)) string.ascii_letters包括里所有的大写小写字母、string.digits是所有的数字 这就可以拼成一个包含大写小写字母和数字的6位随机码
re模块
re模块 match 和search re.match 从头(第一个)开始匹配 re.search 从全局开始匹配 如果想拿到匹配结果,首先德判断是否匹配上了 match_res = re.search('d',s) 因为匹配到了会返回结果,而没有匹配上会返回None 所以: if match_res: #这样就表示匹配上了 pint(match_res.grou()) # 在后面加上grou就是返回匹配的结果。 '.'匹配除了 以外的任意结果 # 匹配字符数字什么的都会匹配上 '^' 从头开始匹配 类似于match # re.search('^ab','abb') 匹配上了 ab 也等同于 re.match('ab','abb') '$' 匹配结尾 # re.search('b$',abb) 匹配上了结尾的b re.match('b$',b) #表示以b开头b结尾 '*' #匹配*前一个字符 0次或多次,如果没有他也算匹配上, 只是grou会得到一个空字符串 '+' #匹配+前一个字符1次或多次 有多少个就匹配多少个,没有匹配上就不会返回值 '?' #匹配前一个字符0次或1次,不管匹配到多少个只匹配一次,没有的话也会返回一个空字符串 '{m}' #匹配前一个字符m次,也就是可以匹配前一个字符随便多少次 '{n,m}' #匹配前一个字符n-m次 从左到右匹配,能匹配最高多少次就匹配最高次 '|' # 匹配|左或|右的字符 例子:re.search('alex|Alex',alex) 返回alex re.search('[a|A]lex',Alex) 返沪Alex 分组匹配: re.search('(D+)(d+)', 'alex123').groups() >>>('alex', '123') # 在条件外面加上括号并后面加上.groups() 这种加括号必须和groups()配合使用 re.split()按照设置的条件去拆分 >>> re.split('d+', 'jacke11alex23rain33',maxsplit=2) ['jacke', 'alex', 'rain', ''] maxsplit = 2 #表示只替换2次,后面的不替换 按特殊字符来拆分的话需要转译 >>> re.split('|', 'alex|jack') ['alex', 'jack'] 其中很特殊: >>> re.split('\\', 'alexjack') ['alex', 'jack'] # 需要加3个 re.sub(‘替换的条件d’, ‘替换成’, 替换的整个字符串, count= 3) # 按照设置的去替换 >>> s 'alex22jack23jingxing50|lkje' >>> re.sub('d','=',s) 'alex==jack==jingxing==|lkje count = 3 #是表示只替换3个后面的不替换 re.fullmatch(pattern, string) 整个字符串匹配成功就返回re object, 否则返回None re.fullmatch('w+@w+.(com|cn|edu)',"alex@oldboyedu.cn") >>>True re.compile方法: prog = re.compile(pattern) # 先把条件设置一个变量 result = prog.match(string) # 再拿这个变量去目标字符串里匹配 等同于: result = re.match(pattern, string) compile的优势在于匹配大数据的时候,速度会快 Flags标志符 re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) 例子:>>> re.search('a','Alex',re.I).group() 'A' M(MULTILINE): 多行模式,改变'^'和'$'的行为 S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline. >>> re.search('.',' ',re.S).group() ' ' re.M可以让'.'匹配 换行 这样'.'就是真正意义可以匹配全部 X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样 >>> re.search('d+ # 这是注释','322',re.X).group() '322' 加上了re.X 他会把条件里面#后面忽略掉 也就是让#后面变成注释
shutil模块
shutil模块 主要是对文件的拷贝和压缩 拷贝: shutil.copyfileobj('打开要拷贝的文件', '拷贝后的文件') shutil.copyfile("文件名", "新文件名") # 和上面的用法区别在于不用专门打开文件,直接输入文件名即可 shutil.tree('文件夹名','新文件夹名',lgnore = None) # 拷贝目录 把整个文件夹拷贝下来 lgnore= shutil.ignore_patterns('文件名') 可以选择忽略不考虑目录下指定的文件 shutil.move("文件名", '新文件名') 类似于给文件重命名 压缩: shutil.make_archive("atm", 'zip', 'ATM') atm是被压缩文件名, zip是压缩格式 ATM是压缩包的名称
subprocess模块
subprocess模块 已经有了os.system() 可以和系统交互了,为什么还要一个subprocess模块做什么用? 因为py3中把其他可以调用系统的全部放到subprocess中,替换了以前的os.system os.spawn 三种主要方法: subprocess.run() # 官方推荐 subprocess.call() subprocess.Popen() subprocess.run()标准写法: a = subprocess.run(['df', '-h'],stdout=subprocess.PIPE,stderr=subprocess.PIPE,check=True) 其中,df-h是系统操作命令, stdout是标志输出,stderr是错误输出 subprocess是利用了系统的内存作为管道去访问其他内容 PIPE就是管道 check=True 的时候,如果有错误,会直接报出来,如果没有写check的时候,如果有错误a.stdout是不输出东西,a.stderr就会输出错误,但是当check=True的时候会直接报错 相对于就是结果必须正确 run()中设计到管道符的写法 subprocess.run('df -h|grep disk1',shell=True) #shell=True的意思是这条命令直接交给系统去执行,不需要python负责解析, |是shell里面管道符的标志,在标准写法里命令加了中括号是为了告诉python这是命令拿去解析,当命令里出现管道符的时候python是解析不出来的,那就可以直接交给系统shell命令 call()方法 call方法用的不多,知道即可 #执行命令,返回命令执行状态 , 0 or 非0 >>> retcode = subprocess.call(["ls", "-l"]) #执行命令,如果命令结果为0,就正常返回,否则抛异常 >>> subprocess.check_call(["ls", "-l"]) 0 #接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果 >>> subprocess.getstatusoutput('ls /bin/ls') (0, '/bin/ls') #接收字符串格式命令,并返回结果 >>> subprocess.getoutput('ls /bin/ls') '/bin/ls' #执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res >>> res=subprocess.check_output(['ls','-l']) >>> res b'total 0 drwxr-xr-x 12 alex staff 408 Nov 2 11:05 OldBoyCRM ' Popen() 上面两种方法都是Popen方法封装的 a=subprocess.run('sleep 10',shell=True,stdout=subprocess.PIPE) a=subprocess.Popen('sleep 10',shell=True,stdout=subprocess.PIPE) 先说说这两个方法的区别: 两个程序都是让系统等待10秒,但是区别在于run方法是等待10秒后才能继续,Popen方法是相当于创建了两个程序,一个在等待10秒,另外的可以正常使用,用poll()方法,即返回上一个命令的执行状态 0表示执行成功,非0表示没有执行 用poll()方法就可以判断Popne执行了没有
xml模块
xml模块 <?xml version="1.0"?> # 申明为1.0版本 xml是通过<>来取吧数据结构 <data> <country name="Liechtenstein"> # country相当于字典的key "Liechtenstein"相当于valus <rank updated="yes">2</rank> #嵌套在country下面 rank、year是key <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data> 读取xml import xml.etree.ElementTree as ET #调用这个模块来操作xml tree = ET.parse("xmltest.xml") # 相当于打开xml文件 root = tree.getroot() # 拿到xml的root(root就代表里的数据) print(root.tag) # tag代表了标签名 就是上面的<counrty> #遍历xml文档 for child in root: 循环root 就是循环xml数据 child.tag 是data下的根 <country> # child.attrib是data下的字典{key:valus} print(child.tag, child.attrib)d for i in child: print(i.tag,i.text) # 循环每一个country i.tag是child.attrib的key #i.text是child.attrib的key #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text) xml 的增删改查 import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") # tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml') 3398208285 553368648