Hadoop 2.2中正式启用了hdfs nfs功能,使得hdfs的通用性迈进了一大步。在公司让小朋友搭建了一下,然后我自己进行了一点简单的试验,有一点收获,记录在此。
理论
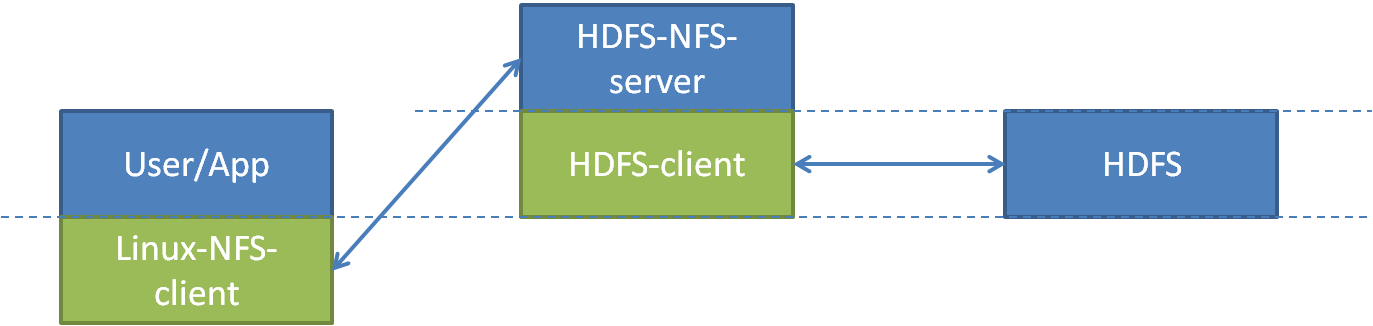
使用hdfs nfs功能的话,数据访问路径如上图:用户或程序通过Linux自带的nfs client访问hdfs nfs服务,然后再由nfs网关作为hdfs的客户端访问hdfs。
这张图中,中间的节点就是nfs代理服务器(hdfs nfs proxy)或nfs网关(hdfs nfs gateway)。蓝色代表该模块是一个进程或服务,绿色代表该模块是一个库。图中还画了两条虚线,下、上线分别表示操作系统级别和分布式操作系统(hadpp)级别的内核态与用户态分界。
部署
在nfs网关上部署hdfs nfs服务所需要的程序包,按hadoop 2.2的部署方式,应该存在这两个文件:
share/hadoop/common/hadoop-nfs-2.2.0.jar
share/hadoop/hdfs/hadoop-hdfs-nfs-2.2.0.jar
配置文件不需要改,使用默认即可;默认的几个配置分别是nfs的服务端口(标准的2049)、mount的监听端口(4242),还有一个dump目录(/tmp/.hdfs-nfs)与写逻辑有关,暂不明原理。
部署完成后,启用服务,需要依次启动portmap和nfs两个服务;
$ hadoop-daemon.sh start portmap $ hadoop-daemon.sh start nfs3
注意,portmap需要用root用户启动(因为portmap标准端口111,小于1024,是超级资源),而nfs服务应该用hdfs的超级用户启动。如果出现冲突,应该将操作系统本身的nfs服务停掉。
启动完成后,检查确认是否可用,其中nfs_server_ip是nfs网关的地址:
$ rpcinfo -p $nfs_server_ip program vers proto port 100005 1 tcp 4242 mountd 100000 2 udp 111 portmapper 100005 3 tcp 4242 mountd 100005 2 udp 4242 mountd 100003 3 tcp 2049 nfs 100000 2 tcp 111 portmapper 100005 3 udp 4242 mountd 100005 1 udp 4242 mountd 100005 2 tcp 4242 mountd
$ showmount -e $nfs_server_ip Export list for SY-0245: / *
挂载NFS服务
创建挂载的目录
$ mkdir /mnt/hdfs
安装mount.nfs
$ sudo apt-get install nfs-common
开始挂载
$ mount.nfs $nfs_server_ip:/ /mnt/hdfs
试用及分析
尝试访问/mnt/hdfs,试用了简单的ls、cp、rm等操作,也进行了md5sum,都可以正常使用,而且响应速度明显快于通过FsShell进行操作,这应该是得益于nfs的wcc缓存及hdfs nfs的实现中对连接的缓存;
但hdfs nfs是否是一个完全兼容标准文件系统接口的实现呢,为此我测试了一下最难处理的随机写和复写,代码如下,简单的说,就是做三次写,第一次写在文件头(字符1),第二次写在文件尾(字符2),第三次写在文件中间(字符3):


#include <stdio.h> #include <stdlib.h> #include <stdbool.h> void usage(char* argv[]) { fprintf(stdout, "%s <file_length> ", argv[0]); fprintf(stdout, "NOTE: "); fprintf(stdout, " file_length >= 3 "); } bool open_and_check(FILE** fpp, int op_seq) { (*fpp) = fopen("testfile", "r+"); if ((*fpp) == NULL) { fprintf(stderr, "%d.Can not open test file. ", op_seq); return false; } return true; } int main(int args, char* argv[]) { if (args != 2) { usage(argv); return -1; } int length = atoi(argv[1]); if (length < 3) { fprintf(stdout, "file_length must be at least 3 "); return -1; } fclose(fopen("testfile", "w+")); FILE* fp; int op_seq = 1; if (!open_and_check(&fp, op_seq)) return op_seq; putc('0'+op_seq, fp); // '1' fclose(fp); op_seq++; if (!open_and_check(&fp, op_seq)) return op_seq; fseek(fp, length, SEEK_SET); putc('0'+op_seq, fp); // '2' fclose(fp); op_seq++; if (!open_and_check(&fp, op_seq)) return op_seq; fseek(fp, length/2, SEEK_SET); putc('0'+op_seq, fp); // '3' fclose(fp); //op_seq++; return 0; }
注:参数n是第二次写之前做的偏移量,因而实际文件长度会是n+1
1. 首先用一个小文件做测试,如下:
root@xxx:/mnt/hdfs/tmp# ./a.out 3 root@xxx:/mnt/hdfs/tmp# ls -l testfile -rw-r--r-- 1 root root 4 Nov 27 18:04 testfile root@xxx:/mnt/hdfs/tmp# cat testfile 132
结果都符合预期;
2. 如果再重复执行一次呢?
root@xxx:/mnt/hdfs/tmp# ./a.out 3 Segmentation fault (core dumped)
从hdfs nfs网关的日志中可以找到出错的原因:
2013-11-27 18:11:53,695 ERROR org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3: Setting file size is not supported when setattr, fileId: 20779
不支持重置文件大小,也就是不支持truncate,至少还“正确地”返回了失败;
3. 改变文件大小测试一下
root@SY-0266:/mnt/hdfs/tmp# ./a.out 4096 && ls -lh --full-time testfile && sleep 5 && ls -lh --full-time testfile -rw-r--r-- 1 root root 2.1K 2013-11-27 22:22:40.572000000 +0800 testfile -rw-r--r-- 1 root root 1 2013-11-27 22:22:40.572000000 +0800 testfile root@SY-0266:/mnt/hdfs/tmp# rm testfile root@SY-0266:/mnt/hdfs/tmp# ./a.out 4095 && ls -lh --full-time testfile && sleep 5 && ls -lh --full-time testfile -rw-r--r-- 1 root root 4.0K 2013-11-27 22:25:17.606000000 +0800 testfile -rw-r--r-- 1 root root 4.0K 2013-11-27 22:25:17.606000000 +0800 testfile
可以发现从4K开始,向上的文件已经无法正常完成这个测试了,文件会隐性的丢失数据。这应该与hdfs nfs对随机写和复写的实现有关,我没有具体研究代码。
从这个简单测试可以得出结论,hdfs nfs可以进行简单的文件读写、使用常用的shell命令操作,但决不可以直接当本地文件系统、通过程序进行访问。