一.遇到什么瓶颈?
在遇到瓶颈之前,我们做了很多工作,主要包括:
(1)简单的数据采集,包括完全加载时间,DomReady 时间,需要注意的是这些都是结果指标;
(2)依照“业界最佳实践”快糙猛的做了很多事情:比如异步化,静态化,LazyLoading,BigRender,这些实践效果都还不错;
(3)因为只有结果指标数据,这个阶段我们绝大部分决策都是基于别人的经验,甚至拍脑袋,而不是基于应用的实际性能细节数据;
快糙猛的方式注定不是可持续的,很快,我们遇到了瓶颈,具体是什么瓶颈呢?
(1)首先,如果把业界最佳实践当成燃料,而性能优化当成驾车远行的话,我们的燃料很快就烧完了,因为大家总结出来的通用的优化手段总是有限的,而我们的目标还没有达到;
(2)其次,因为我们只采集了结果指标,只知道整体表现如何,面对异常波动我们显得特别无力,因为显示世界影响性能的因素太多了,对于到底发生什么事情了,我们无从得知;
(3)再次,由于对性能缺少内窥,我们无法找到更多的优化点,实际上,我们需要一个类似于显微镜的东西,来看看应用内部还有哪些可优化的地方;
二.如何突破瓶颈?
面对这些瓶颈,需要想办法去突破它。先仔细考虑这样一个问题:
到底在优化什么东西?是文档的生成速度?页面资源的加载速度?页面的渲染速度?或者说更高大上的用户体验?这些问题想清楚了,才能分析的更彻底。
其实,大多数的性能优化工作都开始于瀑布流图的分析,比如下面我们就来看看一般项目详情页的瀑布流图:
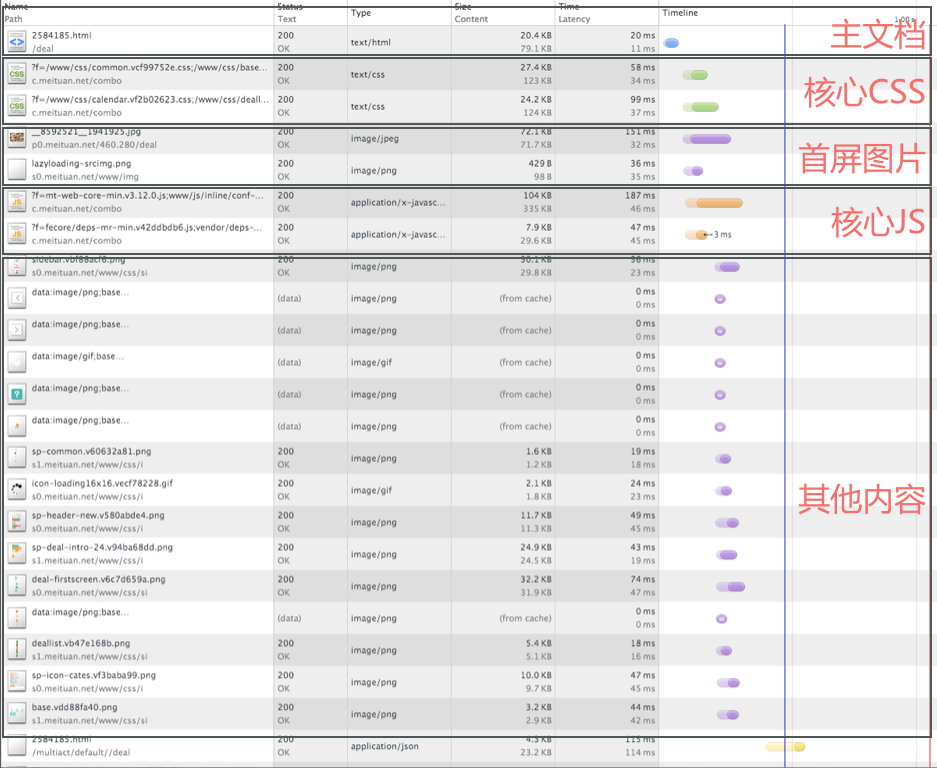
把项目详情页的资源分为以下几部分:
(1)主文档,即页面的内容,在拿到主文档之前,浏览器啥都干不了;
(2)核心 CSS,和首屏图片,在拿到这些之后,浏览器可以开始渲染了;
(3)核心 JS,拿到这些内容之后,页面的交互被丰富,但是也会阻塞;
(4)其他内容,比如雪碧图,统计脚本等;
从技术上来讲,优化的就是这个瀑布流图的每个环节,那么瀑布流图的背后是什么?
其实就是页面加载过程中各个资源的加载时间分解:从上到下的箭头表示时间轴,从浏览器跳转,缓存检查,再到 DNS、TCP 建连,
然后发起主文档请求,再到接收完最后一个字节,再到浏览器开始CSS、JS、图片的下载,最后是页面渲染和交互响应。
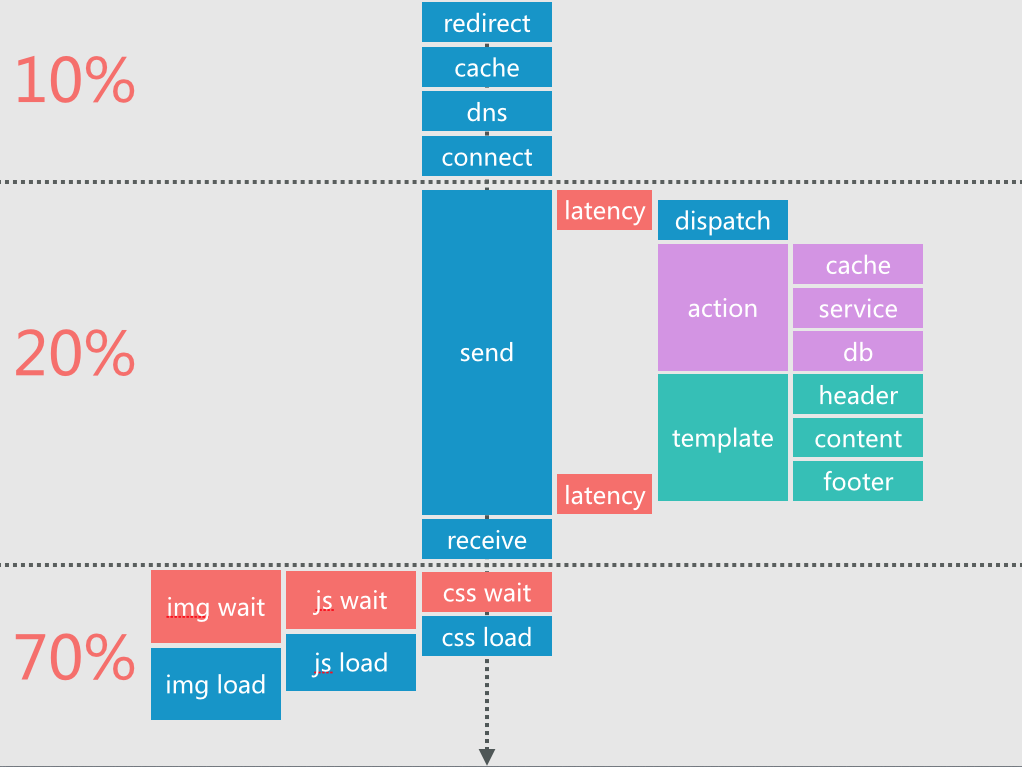
根据《高性能网站建设指南》上的数据以及我们的观察,整个页面的加载可以划分为 3 大块:网络时间、后端时间、前端时间,
发生在网络和后端的时间占到整体加载时间的 10% 和 20%,而前端资源加载时间占到整体加载时间的 70% ~ 80%。
前端资源加载是否快速对性能影响是最大的,这里面资源的加载顺序,并发数量,都有很多的工作可做:
比如:
如果你发现 CSS 加载之前的阻塞时间很长,那很可能是资源加载顺序不合理,这必然会导致浏览器渲染延后。
页面的加载时间还能分解的更细么?到目前为止,我们都是站在浏览器的视角,划清了各个环节。
浏览器拿到文档之前,是不会做任何事情的,后端响应速度的变动多数时候能引发性能上的蝴蝶效应,
我们的突破口就在后端处理时间上:服务器收到请求之后,会经历请求分发、业务逻辑处理、文档生成这三个阶段,
在业务逻辑处理阶段,会涉及到和数据库、缓存以及内部服务的通信,拿到所有的数据之后,渲染模板,最后发送给浏览器。
对页面加载过程中涉及到的所有环节进行分解和细化,就形成了我们的分析框架。
三.如何把控性能?
有了分析框架,那么如何全面的把控网站的性能呢?
基于这个框架,通过统计脚本加上必要的数据统计(这里的统计都是过程指标,只反映页面加载过程中某个环节的健康状况),就能获得对整个网站的很多内窥。
具体来说,我们对数据的要求是这样的:整个流程各环节的,多维度(比如分页面、分地理区域、分浏览器)的,实时的(方便我们快速实验)。
所有的数据都必须是能够反映整体的统计量。
而对于统计脚本,需要满足两个条件:
(1)避免对业务代码的入侵;
(2)不影响被测量的页面的性能;
针对第 1 个要求,需要开发独立的统计脚本,避免其与现有的框架耦合,方便移植到其他项目;
而针对第 2 个要求,需要在主文档加载完毕之后,再注入统计脚本收集数据,并且尽可能的合并数据请求,减少带宽消耗。
确定了数据统计脚本的约束条件之后,我们从哪里得到这些数据呢?目前使用的主要途径有:
(1)主文档加载速度,利用 Navigation Timing API 取得;
(2)静态资源加载速度,利用 Resource Timing API 取得;
(3)首次渲染速度,IE 下用 msFirstPaint 取得,Chrome 下利用 loadTimes 取得,我们的 Chrome 浏览器用户占比超过 70%;
(4)文档生成速度,则是在后端应用内打点来获得;
对于主文档加载速度,我们从宏观到微观的做了这样的分解,从上到下的时间流,右边的时刻标记了每个指标从哪里开始计算到哪里截止,
比如,跳转时间 redirect 由 redirectEnd - redirectStart 计算得到,其他的类推:
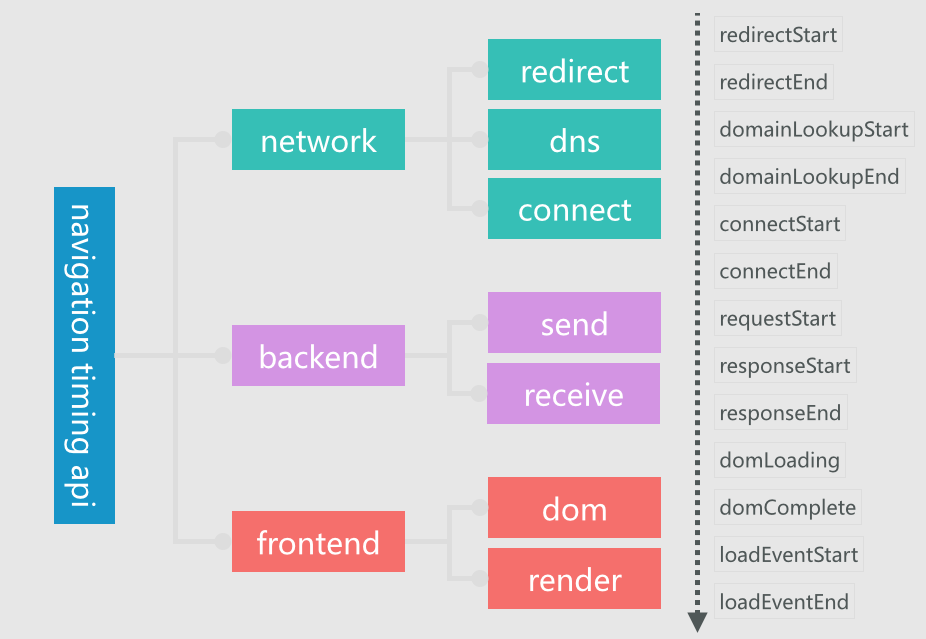
采集主文档加载速度的具体做法是:
(1)在主文档 load 之前提供可缓存数据的接口,方便在统计脚本载入前就可以准备数据;
(2)在主文档 load 之后注入数据收集脚本,该脚本加载完成之后会处理所有的数据;
(3)利用 Navigation Timing API 收集计算得到上图中的指标;
(4)给所有数据打上页面、地理位置、浏览器等标签,方便更细维度的分析;
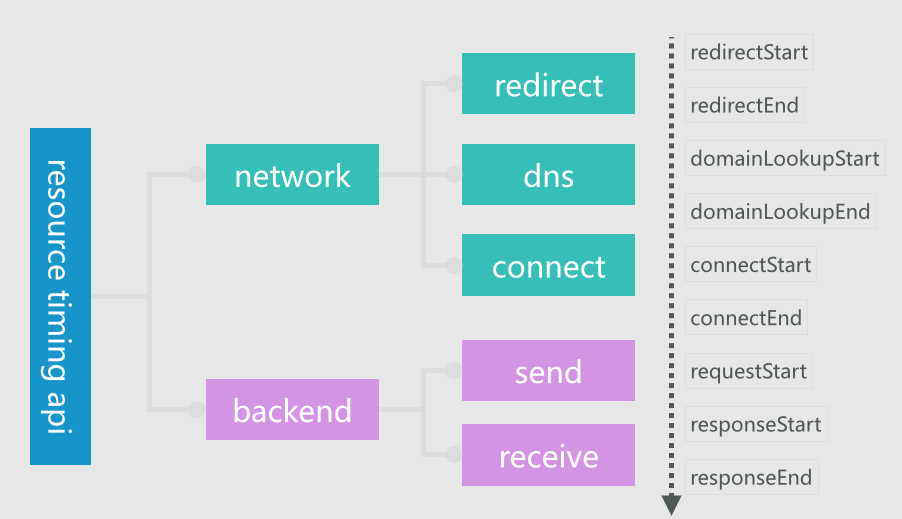
对于静态资源的加载速度,我们也做了类似的分解和采集:
四.总结
以上,就是做性能优化时遇到的问题,以及解决的办法,总结:
(1)首先,需要深入的剖析问题,性能分析问题的框架,让很多死角暴露无疑;
(2)其次,在性能优化这件事情上,只关注结果指标是不会给你多大帮助的,如果想真的优化,你需要测量过程指标,从过程指标发现更多;
(3)再次,解决一个问题比如解决一类问题,解决问题的思路和工具可以沉淀下来,服务更多的团队和同事。