在学习李宏毅老师机器学习的相关视频时,课下做了一个有关神经网络的小Demo,但是运行效果总是不尽人意,上网查询资料,才发现是梯度爆炸和梯度消失惹的祸。今天就让我们一起来学习一下梯度消失与梯度爆炸的概念、产生原因以及该如何解决。
目录
1.梯度消失与梯度爆炸的概念
2.梯度消失与梯度爆炸的产生原因
3.梯度消失与梯度爆炸的解决方案
首先让我们先来了解一个概念:什么是梯度不稳定呢?
概念:在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。
产生梯度不稳定的根本原因:前面层上的梯度是来自后面层上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
划重点:梯度消失和梯度爆炸属于梯度不稳定的范畴
1.梯度消失与梯度爆炸的概念
梯度消失:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度消失。
梯度爆炸:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度爆炸。
其实梯度消失和梯度爆炸是一回事,只是表现的形式,以及产生的原因不一样。
2.梯度消失与梯度爆炸的产生原因
梯度消失:(1)隐藏层的层数过多;(2)采用了不合适的激活函数(更容易产生梯度消失,但是也有可能产生梯度爆炸)
梯度爆炸:(1)隐藏层的层数过多;(2)权重的初始化值过大
以下将从这3个角度解释产生这两种现象的根本原因
(1)隐藏层的层数过多
总结:从深层网络角度来讲,不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。具体见下图:

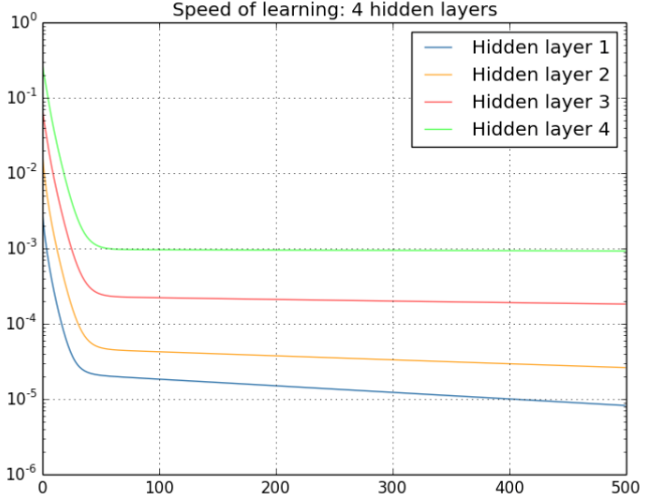
从上图可以非常容易的看出来:对于四个隐层的网络来说,第四隐藏层比第一隐藏层的更新速度慢了两个数量级!!!
(2)激活函数
我们以下图的反向传播为例,假设每一层只有一个神经元且对于每一层都可以用公式1表示,其中σ为sigmoid函数,C表示的是代价函数,前一层的输出和后一层的输入关系如公式1所示。我们可以推导出公式2。

σ为sigmoid函数,其导数的图像如下图所示:

可见,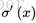
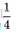
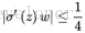
(3)初始化权重的值过大
当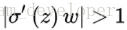
3.梯度消失与梯度爆炸的解决方案
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
(1)用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。(几种激活函数的比较见我的博客)
(2)用Batch Normalization。(对于Batch Normalization的理解可以见我的博客)
(3)LSTM的结构设计也可以改善RNN中的梯度消失问题。