分布式存储-Redis高可用架构剖析
前面说到哨兵集群最初状态都是没有leader的,他们是通过raft算法选出leader,但是没有深入聊raft,所以本章聊聊raft。接着聊聊Redis Cluster集群搭建,以及gossip协议。最终对redis这里做一个总结。因为我们一直在聊存储和分布式所以下篇想聊聊分布式和数据库方面的东西。
Redis中的Raft一致性算法
前面说了一下,Redis使用Raft算法去选举哨兵leader,那Raft到底是什么呢?其实他的核心就是【先到先得,少数服从多数】。
- 每个节点都听从leader的之后,当他们无法联系上leader的时候,就开始选举。
- 在选举leader的时候,每个节点都投票给自己,但是在开始投票的时候,他们都会随机休眠一段时间【150, 300ms】。
- 当休眠结束后,开始毛遂自荐(给自己投一票->把这一票发送给其他的节点),比如有三个节点,这个是有节点A休眠结束,他就给B和C发送自己想当Leader的请求
- 对于B和C来讲,谁的请求先过来就先接受谁的请求,换而言之,他们最早收到了A的请求(因为假设A最早休眠结束)。那他们就把自己的选票投给A,这就叫【先到先得】
- 当B和C都统一A当leader的时候,假设还有一个D,但是D节点不同意,那这样也不管用,因为集群中一半同意就可以选举出结果,这叫做【少数服从多数】。
- 其实他们还在发送config_epoch 和repl_offset(他们代表了节点的更新程度)如果A的这个两个数据低于B和C我们,那就不会选举A,这样就多了一层公平性。
Redis Cluster(分片)
前面我们聊到的是Maser-slave这样的模式,master负责写,而slave负责读,但是这种只能说在读多写少的场景下,我们可以对slave进行水平扩容,然而master还是有很多压力,比如说在 请求量过大,数量过多的情况下 所以我们聊聊Redis Cluster。
那Redis Cluster是什么?
- 他其实就是进行数据分片,所谓分片就是把一份大数据拆分成多份小数据。
- 而一个Redis Cluster由多个Redis节点构成,不同节点组服务的数据没有交集,也就是每个一节点组对应数据sharding的一个分片。
- 节点组内部分为主备两类节点,对应master和slave节点。两者数据准实时一致,
- 一个节点组有且只有一个master节点,同时可以有0到多个slave节点,在这个节点组中只有master节点对用户提供写服务,读服务可以由master或者slave提供。如下图中,包含三个master节点以及三个master对应的slave节点,一般一组集群至少要6个节点才能保证完整的高可用。其中三个master会分配不同的slot(表示数据分片区间),当master出现故障时,slave会自动选举成为master顶替主节点继续提供服务
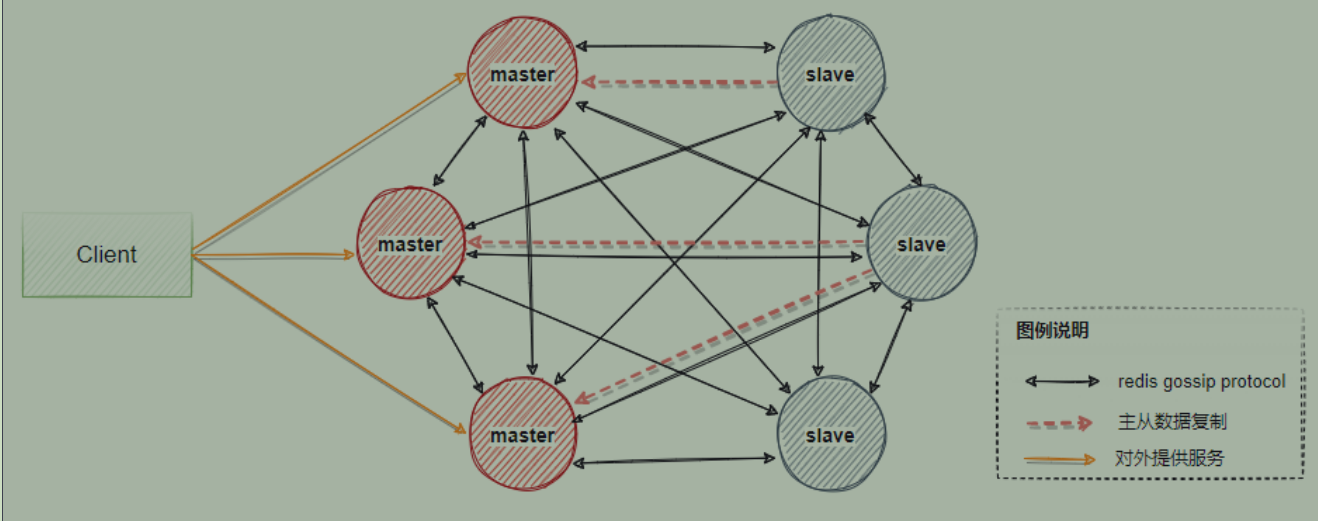
图例中看见gossip协议,那什么是gossip协议?
- 当集群中状态出现变化时候,我们希望让每个节点都知道这些信息【新加入节点、分片数据迁徙、节点宕机、slave选举成为master and so on】按照正常的逻辑是采用广播的方式想集群中的所有节点发送消息,优点是集群中的数据同步较快,但是每条消息都需要发送给所有节点,对CPU和带宽的消耗过大,所以这里采用了gossip协议.它的特点是,在节点数量有限的网络中,每个节点都会“随机”与部分节点通信,经过一番杂乱无章的通信后,每个节点的状态在一定时间内会达成一致。
Redis Cluster集群搭建 【上面聊到了最少需要6个节点,那现在搭建了三个虚拟机,所以我在每个机器上放了两个redis】
- 在redis安装目录下,分别创建以下目录,这些目录必须要提前创建好,redis启动时不会主动创建这些目录
- pidfile "/data/program/redis/run/redis_7000.pid" #pid存储目录
logfile "/data/program/redis/logs/redis_7000.log" #日志存储目录dir "/data/program/redis/data/7000" #数据存储目录,目录要提前创建好cluster-enabled yes #开启集群cluster-config-file nodes-7000.conf #集群节点配置文件,这个文件是不能手动编辑的。确保每一个集群节点的配置文件不同cluster-node-timeout 15000 #集群节点的超时时间,单位:ms,超时后集群会认为该节点失败
- 修改config文件,由于只有三台机器,所以每个机器上需要运行两个redis-server,因此需要修改redis.conf文件的名字来做区分,redis_7000.conf。并且修改该文件的一下内容
- 因为一个机器需要两个节点,所以把上面的配置文件再次拷贝一份,然后在把文件中的7000都变成7001
- 启动脚本【 cluster-start.sh 】
- 停止脚本【 cluster-shutdown.sh】
- 给脚本赋权
- 重复上述操作到其他两个机器,除了进程号不一样,然后启动集群。但是这个时候集群还没有进行配置!!
【7000 、 7001】 【7002 、 7003】 【7004 、 7005】Redis Cluster集群搭建Redis Cluster集群配置在redis6.0版本中,创建集群的方式为redis-cli方式直接创建,以下命令在任意一台服务器上执行即可 。--cluster-replicas 1 参数表示希望每个主服务器都有一个从服务器,这里则代表3主3从
- ./redis-cli --cluster create 192.168.221.128:7000 192.168.221.128:7001 192.168.221.129 7002 192.168.221.129 7003 192.168.221.130 7004 192.168.221.130 7005 --cluster-replicas 1
通过命令查询集群状态 【cluster info】我们发现他的集群状态是ok的

- 查看集群节点信息 【cluster nodes】,我们看到现在有三个master,并且每一个都分配有数据区间 【5461-10922,0-5460 ,10923-16383 】 【至此Redis Cluster 搭建完成】
那么既然数据是分片存储的,那么他如何知道客户端传入的key应该放在哪台机器上呢?
其实很简单,就是使用CRC16校验码算法算出一个数字后,和16384取模[crc16(key)%16384]这样就算出了到底客户端传递的key应该存储在哪个节点上。客户端重定向
假设传递的key应该存储在node3上,而此时用户在node1或者node2上调用 set k v 指令,这个时候redis cluster怎么处理呢?这个时候服务端就会返回MOVED,也就是根据key计算出来的slot不归当前节点管理,服务端返回MOVED告诉客户端去7293端口操作。 但是这样带来的问题是,可能客户端会连接两次,所以大部分的redis客户端都会在本地维护一份slot和node的对应关系,在执行指令之前先计算当前key应该存储的目标节点,然后再连接到目标节点进行数据操作。

Redission的Cluster配置
修改redisson.yml【nodeAddresses对应的节点都是master】
clusterServersConfig:nodeAddresses:- "redis://192.168.221.129:7003"- "redis://192.168.221.129:7002"- "redis://192.168.221.130:7004"codec: !<org.redisson.codec.JsonJacksonCodec> {}他其实就是和我们上面聊的一样,在启动的时候获取redis节点的可以存储的数据区间,然后在对某个key进行操作的时候,先得知它应该被放在哪个节点上。在启动的时候我们就能看到这点。当我们操作的时候,他会自己进行路由转发 codis:实际上在没有redis cluster的时候,有一种方案就是使用codis。这想当于一个客户端的代理操作,它会帮你进行路由,等类似cluster的操作。这里不在赘述
codis:实际上在没有redis cluster的时候,有一种方案就是使用codis。这想当于一个客户端的代理操作,它会帮你进行路由,等类似cluster的操作。这里不在赘述
redis小结
我们前面聊了 redis的数据类型、redis实战、手写redis的客户端、网络通信线程和redis、淘汰机制 lru 和 lfu、持久化这些东西。这是我能想到的redis的知识点。至此redis告一段落,下面我会去聊聊数据库层面的东西。