1. pass break continue
# ### pass break continue # (1) pass 过 """如果代码块当中,什么也不写,用pass来进行站位""" def func(): pass if 5 == 5: pass # while 5>3: # pass # (2) break 终止当前循环 (只能在循环当中使用) # 打印1~10 如果遇到5就终止循环 i = 1 while i<=10: print(i) if i == 5: break i+=1 # error """ if 5==5: break """ i = 1 while i<=3: j = 1 while j<=3: if j == 2: print(i,j) break j+=1 # (3) continue 跳过当前循环,从下一次循环开始 (只能在循环当中使用) # 打印1~10,不包含5 """ 当i等于5的时候,continue跳过当前循环,后面的代码通通不执行 直接回到循环判断中,因为i没有自增,所以条件5<=10永远为真 发生死循环,为了避免这个情况,所以我们手动加1,在执行continue; """ i = 1 while i<=10: if i == 5: # 手动自增,预防死循环; i+=1 continue print(i) i+=1 # 打印1~100 所有不包含4的数字. # 方法一 i = 1 while i<=100: # 先判断 if i % 10 == 4 or i // 10 == 4: i+=1 continue # 后打印 print(i) i+=1 # 方法二 in print("<======>") i = 1 while i<=100: num = str(i) if "4" in num: i+=1 continue print(i) i+=1 for i in range(1,101): num = str(i) if "4" in num: continue print(i)
2.format字符串格式化传参
"""{} 是format语法中的占位符""" # (1)顺序传参 strvar = "{}向{}开了一枪,饮弹而亡" strvar = strvar.format("银燕","王铁男") print(strvar) # (2)索引传参 strvar = "{1}给{0}一个大大的拥抱" res = strvar.format("毕阳生","刘得元") print(res) # (3)关键字传参 strvar = "{shuaile}给{wubo}一个飞吻" res = strvar.format(wubo="吴波",shuaile="帅乐") print(res) # (4)容器类型数据(列表或元组)传参 # (1) strvar = "{0[1]}向{1[2]}抛了一个媚眼,神魂颠倒,鼻血直冒三万多尺" res = strvar.format(["舒则会","郭一萌","刘璐"],("李祥海","孙兆强","无要诀")) print(res) # (2) format 当中如果是获取字典对应的值,不要加上引号 strvar = "{group2[qgqc]}向{group1[2]}抛了一个媚眼,神魂颠倒,鼻血直冒三万多尺" res = strvar.format(group1=["邓良辉","刘志华","王文贤"],group2={"fhcm":"舒则会","byxh":"郭一萌","qgqc":"罗淞峰"}) print(res)
3. format字符串填充
# ### format 字符串填充 # (5)format的填充符号的使用( ^ > < ) """ ^ 原字符串居中 > 原字符串居右 < 原字符串居左 语法: {who:*>10} * 要填充的字符 > 原字符串居右 10 原字符个数+要填充的个数 = 长度10 """ strvar = "{who:*^10}在长春长生公司{something:!<10},感觉{feel:>>8}" res = strvar.format(who="李祖庆",something="扎疫苗",feel="爽歪歪") print(res) # (6)进制转换等特殊符号的使用( :d :f :s :, ) """ :d 整型占位符 :f 浮点型占位符 :s 字符串占位符 :, 金钱占位符 """ #:d strvar = "王照买了{:d}个棒棒糖" res = strvar.format(3) print(res) # :2d 占用2位,默认原字符居右 strvar = "王照买了{:<2d}个棒棒糖" res = strvar.format(3) print(res) # :^3d 占用3位,原字符居中 strvar = "王照买了{:^3d}个棒棒糖" res = strvar.format(3) print(res) # :f 浮点型占位符 strvar = "买一斤西红柿的价格是{:f}" res = strvar.format(3.6) print(res) # :.2f strvar = "买一斤西红柿的价格是{:.2f}" res = strvar.format(3.6) print(res) # :s 字符串占位符 format 不能默认强转,只能是填充什么样的格式,就写什么样的数据 strvar = "{:s}" # res = strvar.format("你好,大妹子") ok # res = strvar.format(3.567) no print(res) # 如果是%号用法,默认会进行强制类型转换,强转,但是format格式化时不会执行; strvar = "%s" % (3.14334) print(strvar) # :, 金钱占位符 strvar= "{:,}" res = strvar.format(123456789) print(res) # 综合案例 strvar = "黄花买了{:d}个布加迪威龙,价格{:.1f},心情{:s}" res = strvar.format(3,9.9,"好极了") print(res)
4.字符串操作
# ### 字符串的函数 """ 字符串.函数() """ # *capitalize 字符串首字母大写 strvar = "i love you baby" res = strvar.capitalize() print(res) # *title 每个单词的首字母大写 (非字母隔开的单词) strvar = "i hate you bigbrother" # strvar = "i hate you87342426734bigbrother" res = strvar.title() print(res) # *upper 将所有字母变成大写 strvar = "you love me" res = strvar.upper() print(res) # *lower 将所有字母变成小写 strvar = "I MISS YOU" res = strvar.lower() print(res) # *swapcase 大小写互换 strvar = "to be OR not to be" res = strvar.swapcase() print(res) # *count 统计字符串中某个元素的数量 res = "是生是死,的确是一个问题".count("是") print(res) # *find 查找某个字符串第一次出现的索引位置 """find("字符串",[开始索引,结束索引]),结束索引的最大值取不到""" strvar = "Oh father this is my favorite girls" res = strvar.find("father") print(res) res = strvar.find("s",3) print(res) # 13 # 14~17的这个索引区间找s这个字符的索引号,最大值是取不到的; res = strvar.find("s",14,18) print(res) # 如果找不到该字符,直接返回-1,表达没有 res = strvar.find("你") print(res) # *index 与 find 功能相同 find找不到返回-1,index找不到数据直接报错 """推荐使用find ,因为index会报错,终止程序;""" # res = strvar.index("你") # *startswith 判断是否以某个字符或字符串为开头 """endswith,startswith(字符串,[开始索引,结束索引]) 结束索引最大值取不到""" strvar = "Oh father this is my favorite girls" res = strvar.startswith("Oh") print(res) res = strvar.startswith("father",3) res = strvar.startswith("father",4) print(res) # *endswith 判断是否以某个字符或字符串结尾 res = strvar.endswith("girls") print(res) res = strvar.endswith("my",18,20) res = strvar.endswith("y",18,20) print(res) # *split 按某字符将字符串分割成列表(默认字符是空格) strvar = "you can you up no can no bb" res = strvar.split() print(res) strvar = "you,can,you,up,no,can,no,bb" res = strvar.split(",") print(res) # 可以选择分隔的次数 res = strvar.split(",",4) print(res) # rsplit 从右向左分隔 res = strvar.rsplit(",") print(res) # 一样可以选择分隔的次数 res = strvar.rsplit(",",4) print(res) # *join 按某字符将列表拼接成字符串(容器类型都可) lst = ['you', 'can', 'you', 'up', 'no', 'can', 'no', 'bb'] res = "-".join(lst) print(res) # *replace 替换字符串(可选择替换的次数) 默认替换所有 strvar = "可爱的小狼狗喜欢吃肉,有没有,有没有,还有没有" # replace(替换谁,替换成什么,[替换几次]) res = strvar.replace("有没有","真没有") print(res) res = strvar.replace("有没有","真没有",2) print(res) # *isalnum 判断字符串是否是由数字、字母、汉字组成 strvar= "2342sdfsd你好&*&*" strvar= "2342" res = strvar.isalnum() print(res) # *isdigit 检测字符串数是数字组成 接受二进制字节流 """ # 二进制字节流 : 传输数据,存储数据 字符串 => 一个一个字符组成 字节流 => 一个一个字节组成 1byte = 8bit 1B = 8b 语法格式:b"字符串" # 注意点: b开头的二进制字节流,里面的字符编码只能是ascii编码; encode decode 用来转换中文变成二进制的字节流;中文前面加b是错误的; strvar = b"1234454" # 二进制字节流 # strvar = b"你好上" error """ strvar = "123456" res = strvar.isdigit() print(res) strvar = b"89898" res = strvar.isdigit() print(res) # *isdecimal 检测字符串是否以数字组成 必须是纯数字 strvar = "123456" # strvar = b"89898" error 不能识别二进制的字节流 res = strvar.isdecimal() print(res) # *len 计算容器类型长度 strvar = "阳光洒在手指间" res = len(strvar) print(res) # *center 填充字符串,原字符居中 (默认填充空格) strvar = "李祖清" # 10 是一共的长度 原字符串长度+ 填充字符 = 10 # center(长度,[要填充的字符,默认不写填充空格]) res = strvar.center(10) res = strvar.center(10,"%") print(res) # *strip 默认去掉首尾两边的空白符 """网站注册的时,在存在数据库之前,先处理两边的空白符""" strvar = " 刘德华 " res = strvar.strip() print(res) strvar = "@王战" res = strvar.strip("@") print(res)
5. 列表操作
# ### 列表相关操作 # (1)列表的拼接 (同元组) + lst1 = [1,2,3] lst2 = [4,5,6,1] lst = lst1 + lst2 print(lst) # (2)列表的重复 (同元组) * lst = [2,3] res = lst * 3 print(res) # (3)列表的切片 (同元组) # 语法 => 列表[::] 完整格式:[开始索引:结束索引:间隔值] # (1)[开始索引:] 从开始索引截取到列表的最后 # (2)[:结束索引] 从开头截取到结束索引之前(结束索引-1) # (3)[开始索引:结束索引] 从开始索引截取到结束索引之前(结束索引-1) # (4)[开始索引:结束索引:间隔值] 从开始索引截取到结束索引之前按照指定的间隔截取列表元素值 # (5)[:]或[::] 截取所有列表 lst = ["王振华","李祖清","文昭才","陈凤杰","温红杰","刘璐","等两会","刘志华"] # (1)[开始索引:] 从开始索引截取到列表的最后 res = lst[3:] print(res) # (2)[:结束索引] 从开头截取到结束索引之前(结束索引-1) res = lst[:4] print(res) # (3)[开始索引:结束索引] 从开始索引截取到结束索引之前(结束索引-1) res = lst[5:7] print(res) # (4)[开始索引:结束索引:间隔值] 从开始索引截取到结束索引之前按照指定的间隔截取列表元素值 res = lst[::3] # 正向截取 #0 3 6 print(res) res = lst[7:0:-2] # 逆向截取 #7 5 3 1 print(res) # (5)[:]或[::] 截取所有列表 res = lst[:] res = lst[::] print(res) # (4)列表的获取 (同元组) # 0 1 2 3 4 正向索引 lst = ["宋江","吴用","卢俊义","林冲","杜十娘"] # -5 -4 -3 -2 -1 逆向索引 res = lst[4] res = lst[-1] print(res) # (5)列表的修改 ( 可切片 ) lst[0] = "李祖清" print(lst) # 1.利用切片进行数据的修改 """ 可迭代数据:容器类型数据,range对象,迭代器 """ # 先把1:4所对应的截取数据去除,然后在把可迭代数据中的元素,依次的拿出来进行对应位置赋值 """无要求:截取的数据个数和实际放入的数据个数没有要求""" lst[1:4] = ["石阡","鲁智深","武松","武大郎"] print(lst) # 2.利用切片+步长的方式进行数据的修改 """有要求:切几个数据,就放上几个数据,元素个数要匹配""" print(lst[::2]) # 0 2 4 lst[::2] = (1,2,3) print(lst) # (6)列表的删除 ( 可切片 ) del关键字删除 lst = ["宋江","吴用","卢俊义","林冲","杜十娘"] del lst[1] print(lst) # 可以利用切片来删除 lst = ["宋江","吴用","卢俊义","林冲","杜十娘"] del lst[1:3] print(lst) # 注意点 lst = ["宋江","吴用","卢俊义","林冲","杜十娘"] # 把要删除的数据直接写在del 关键字的后面,如果删除res的话,是删除res这个变量,跟列表没有关系. res = lst[1:3] del res print(lst) # 元组相关操作 """ 元组针对于第一级所有的元素是修改不了的 但是如果含有二级容器,并且该容器可以修改,那么元组里面的二级或者多级可以修改 """ tuplevar = (1,4,4,5,6,[434,645,43,(234,)]) res = tuplevar[-1] print(res) res[-2] = 88 print(tuplevar) #(1, 4, 4, 5, 6, [434, 645, 88, (234,)]) # 集合的值或者字典的键必须是可哈希数据=>不可变得数据类型(int bool float complex str tuple) # setvar = {(1,2,3,4,5,6,[7,8,9])} # error unhashable type: 'list'
6.列表的相关函数元组
# ### 列表的相关函数 listvar = [23,45,67] # 增 # 1.append 向列表的末尾添加新的元素 res = listvar.append(16) print(res) # 它的返回值没有任何意义 print(listvar) # 2.insert 在指定索引之前插入元素 listvar = ["邓良辉","李祖清"] listvar.insert(1,"刘志华") print(listvar) # 3.extend 迭代追加所有元素 listvar = ["邓良辉","李祖清"] # 把元组当中的元素一个一个的插入到列表当中 listvar.extend( (1,2,3,4) ) print(listvar) # 删 listvar = ["邓良辉","李祖清","舒则会","郭一萌","黄花"] # 1. pop 通过指定索引删除元素,若没有索引移除最后那个 (推荐使用) listvar.pop() print(listvar) listvar.pop(0) print(listvar) # 2.remove 通过给予的值来删除,如果多个相同元素,默认删除第一个 listvar = ["邓良辉","李祖清","舒则会","郭一萌","舒则会","黄花"] listvar.remove("舒则会") print(listvar) # 3.clear 请空列表 listvar.clear() print(listvar) # 改 查 # 详见5.py # 其他相关函数 listvar = ["邓良辉","李祖清","舒则会","郭一萌","舒则会","黄花","郭一萌","郭一萌"] # 1.index 获取某个值在列表中的索引 """index(要搜索的值,[开始索引,结束索引])""" res = listvar.index("郭一萌") print(res) res = listvar.index("郭一萌",4) print(res) res = listvar.index("郭一萌",6,7) print(res) # count() 计算某个元素出现的次数 res = listvar.count("郭一萌") print(res) # sort() 列表排序(默认小到大排序) """如果是字母,按照ascii编码进行排序""" listvar = ["james","jand","qz","davis","smallkl"] listvar.sort() print(listvar) # sort(reverse=True) (从大到小排序) listvar = [-90,67,11,1000] listvar.sort() listvar.sort(reverse=True) print(listvar) # reverse 列表反转操作 相当于水平翻转 listvar = [1,88,-90,"a"] listvar.reverse() print(listvar) """ tuple 里面只有index和count两个函数可以用.剩下的基本操作和列表一样 """
7.深浅拷贝
# ### 深拷贝 与 浅拷贝 """ a = 7 b = a a = 9 print(b) # 列表赋值出现的问题:两个不同的变量指向同一个列表 lst1 = [1,2,3] lst2 = lst1 lst1.append(4) print(lst2) """ # 浅拷贝 copy [两个列表之间彼此独立,拷贝一个新的副本] # 方法1 lst1 = [1,2,3] lst2 = lst1.copy() lst1.append(4) print(lst1) print(lst2) # 方法2 '''import 引入 copy模块下的 copy方法 ''' import copy lst1 = [1,2,3] lst2 = copy.copy(lst1) lst1.append(4) print(lst1,lst2) # 深拷贝 """ 浅拷贝只是单独复制一级列表里面所有元素 深拷贝可以复制所有级别的列表元素,都单独拷贝一份, 都形成独立的副本,彼此不受干扰 """ # 出现的问题: lst1 = [1,2,3,[4,5,6]] lst2 = lst1.copy() lst1[-1].append(7) lst1.insert(2,666) print(lst1) print(lst2) lst1 = [1,2,3,[4,5,6]] lst2 = copy.deepcopy(lst1) lst1[-1].append(999) print(lst1) print(lst2) """ 看需求而定 浅拷贝的执行时间,要比深拷贝执行时间要快 而深拷贝是所有级别的列表都单独拷贝出来,形成独立副本 而浅拷贝仅仅只是拷贝一级的所有元素,二级的不考虑. """ container = [1,2,3,{"a":[4,5,6]}] container2 = copy.deepcopy(container) container[-1]["a"].append(888) print(container) print(container2)
8.字典相关操作
# ### 字典相关函数 # 1.增 dictvar = {} dictvar["fhzm"] = "舒则会" dictvar["byxh"] = "郭一萌" dictvar["qgqc"] = "罗淞峰" dictvar["cyly"] = "银燕" dictvar["ttyl"] = "刘路" print(dictvar) # fromkeys() 使用一组键和默认值创建字典 (返回新字典) listvar = ["a","b","c"] dictvar = {}.fromkeys(listvar,None) print(dictvar) # fromkeys 不推荐使用,三个键所指向的是同一个列表; dictvar = {}.fromkeys(listvar,[1,2,3]) print(dictvar) dictvar["a"].append(4) print(dictvar) # 2.删 dictvar = {'fhzm': '舒则会', 'byxh': '郭一萌', 'qgqc': '罗淞峰', 'cyly': '银燕', 'ttyl': '刘路'} # 2.1 pop() 通过键去删除键值对 (若没有该键可设置默认值,预防报错) res = dictvar.pop("cyly") print(res) print(dictvar) # 当删除一个不存在的键时,直接报错, # res = dictvar.pop("xboyww") error # 为了预防报错,可以设置默认值 res = dictvar.pop("xboyww","设置默认值,该神秘男子不存在") print(res) # 2.2 popitem() 删除最后一个键值对 dictvar = {'fhzm': '舒则会', 'byxh': '郭一萌', 'qgqc': '罗淞峰', 'cyly': '银燕', 'ttyl': '刘路'} res = dictvar.popitem() print(res) print(dictvar) # 2.3 clear() 清空字典 dictvar.clear() print(dictvar) # 3.改 #update() 批量更新(有该键就更新,没该键就添加) dictvar = {"鼓上骚":"石阡","母夜叉":"杜十娘","浪里白条":"张顺","花和尚":"录制山","入云龙":"公孙上","黑旋风":"李奎"} # 更新方式1 (推荐) dictvar.update( {"神秘男孩":"王文","闭月羞花":"郭一萌","倾国倾城":"罗送风","入云龙":"公孙胜"} ) print(dictvar) # 更新方式1 dictvar.update( zhiduoxing="吴用",jishiyu = "宋江" ) print(dictvar) # 4.查 #get() 通过键获取值(若没有该键可设置默认值,预防报错) 最大的好处在没有该键的时候不报错 dictvar = {"鼓上骚":"石阡","母夜叉":"杜十娘","浪里白条":"张顺","花和尚":"录制山","入云龙":"公孙上","黑旋风":"李奎"} res = dictvar.get("母夜叉123") print(res) # None # 设置默认值 res = dictvar.get("母夜叉123","该母老虎没有") print(res) # 其他 #keys() 将字典的键组成新的可迭代对象 dictvar = {"鼓上骚":"石阡","母夜叉":"杜十娘","浪里白条":"张顺","花和尚":"录制山","入云龙":"公孙上","黑旋风":"李奎"} res1 = dictvar.keys() print(res1) #values() 将字典中的值组成新的可迭代对象 res2 = dictvar.values() print(res2) #items() 将字典的键值对凑成一个个元组,组成新的可迭代对象 res3 = dictvar.items() print(res3) for i in res3: print(i)
9.集合相关操作
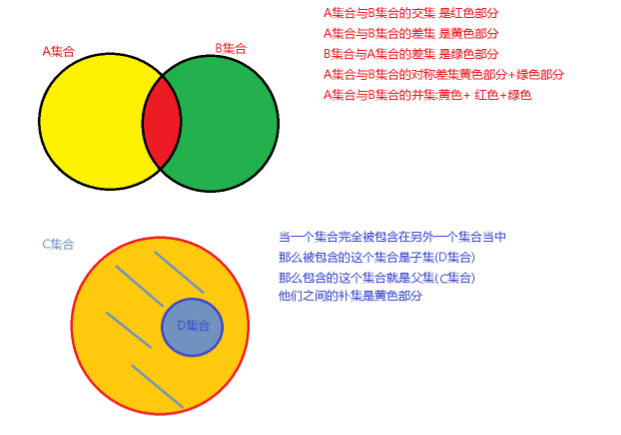
# ### 集合相关操作 set1 = {"王文","刘德华","张学友","郭富城"} set2 = {"王文","王宝强","李宇春","蔡徐坤"} #intersection() 交集 res = set1.intersection(set2) print(res) # 简便写法 & res = set1 & set2 print(res) #difference() 差集 res = set1.difference(set2) print(res) # 简便写法 - res = set1 - set2 print(res) #union() 并集 res = set1.union(set2) print(res) # 简便写法 | res = set1 | set2 print(res) #symmetric_difference() 对称差集 (补集情况涵盖在其中) res = set1.symmetric_difference(set2) print(res) # 简便写法 ^ res = set1 ^ set2 print(res) #issubset() 判断是否是子集 set1 = {"舒则会","郭一萌","黄瓜","孙兆强"} set2 = {"舒则会","郭一萌"} set3 = {"舒则会","郭一萌","黄瓜","孙兆强"} res = set2.issubset(set1) print(res) # 简便写法 < res= set2 < set1 # 真集合 print(res) res = set1 <= set3 print(res) #True #issuperset() 判断是否是父集 set1 = {"舒则会","郭一萌","黄瓜","孙兆强"} set2 = {"舒则会","郭一萌"} res = set1.issuperset(set2) print(res) # True # 简便写法 > res = set1 > set2 print(res) # True #isdisjoint() 检测两集合是否不相交 不相交 True 相交False set1 = {"舒则会","郭一萌","黄瓜","孙兆强"} set2 = {"舒则会","郭一萌"} res = set1.isdisjoint(set2) print(res) #False 代表相交 # ### 集合相关的函数 # 1.增 #add() 向集合中添加数据 setvar = {"赖廷","银燕","毕养生"} setvar.add("易烊千玺") print(setvar) #update() 迭代着增加 """把可迭代性容器里面的数据一个一个的拿出来放到setvar当中""" setvar.update([1,2,3,4,"a","b","c"]) print(setvar) # 2.删 setvar = {"a","c","ddd"} #pop() 随机删除集合中的一个数据 res = setvar.pop() print(res) print(setvar) #remove() 删除集合中指定的值(不存在则报错) # setvar.remove("aaaaa") # print(setvar) #discard() 删除集合中指定的值(不存在的不删除 推荐使用) (推荐) setvar.discard("aaaaa") print(setvar) #clear() 清空集合 setvar.clear() print(setvar) # ### 冰冻集合 #frozenset 可强转容器类型数据变为冰冻集合 # 冰冻集合一旦创建,不能在进行任何修改,只能做交叉并补操作 # 定义一个空的冰冻集合 fz = frozenset() print(fz) # 强制转换为一个冰冻集合 listvar = [1,23,3,43,43] fz = frozenset(listvar) print(fz) for i in fz: print(i) # 只能做交叉并补 fz1 = frozenset(["李宇春","王宝强"]) fz2 = frozenset({"李宇春","王文","周杰伦"}) res = fz1 & fz2 print(res) # 不能做增删操作 错误的 # fz1.add("郭富城") error
10.文件操作
# ### 文件操作 """ 对象.属性 对象.方法() 来调用其中的内容; fp = open(文件名,采用的模式,字符编码) open返回的是一个文件io对象,别名(文件句柄) i=>input 输入 o=>output 输出 """ # (1)文件写入操作 # 1.打开文件 fp = open("ceshi0707.txt",mode="w",encoding="utf-8") # 1.把冰箱门打开 # 2.写入内容 fp.write("把大象扔进去") # 2.把大象放进去 # 3.关闭文件 fp.close() # 3.把冰箱门关上 # (2)文件读取操作 # 1.把冰箱门打开 fp = open("ceshi0707.txt",mode="r",encoding="utf-8") # 2.把大象拿出来 res = fp.read() # 3.把冰箱门关上 fp.close() print(res) # (3) encode 和 decode # 将字符串和字节流(Bytes流)类型进行转换 (参数写成转化的字符编码格式) #encode() 编码 将字符串转化为字节流(Bytes流) #decode() 解码 将Bytes流转化为字符串 # xe9xbbx84xe8x8axb1xe7x9cx9fxe5xb8x85 # encode 将字符串转化为字节流 strvar = "黄花真帅" res = strvar.encode("utf-8") print(res) # decode 将Bytes流转化为字符串 strvar2 = b'xe9xbbx84' res2 = strvar2.decode("utf-8") print(res2) res3 = res.decode("utf-8") print(res3) # 程序员的表白方式 # b'xe6x88x91xe7x88xb1xe4xbdxa0' strvar = "我爱你王文" print(strvar.encode("utf-8")) # wb rb的模式写法 """ 如果模式当中含有b,不要指定encoding编码集.否则报错 """ # 4.把内容变成二进制字节流存储在文件中 # (1) 打开文件 fp = open("0707_1.txt",mode="wb") strvar = "王铁男真硬" res = strvar.encode("utf-8") # (2) 写入内容 fp.write(res) # (3) 关闭文件 fp.close() # 5.把二进制字节流从文件中读出来转成原来的格式decode # (1) 打开文件 fp = open("0707_1.txt",mode="rb") # (2) 读取内容 res = fp.read() # (3) 关闭文件 fp.close() print(res) res = res.decode("utf-8") print(res) # 6.复制图片 """ 但凡是图片或者是音频或者是视频,本质上都是二进制字节流的文件 如果想要复制,先把内容通过二进制字节流模式读取出来, 然后在写入到另外一个文件当中. """ # 把文件内容读出来 fp = open("集合.png",mode="rb") res = fp.read() fp.close() # 把文件内容写到另外一个文件中 fp = open("集合2.jpg",mode="wb") fp.write(res) fp.close()
11. 文件扩展模式
# ### 文件的扩展模式 """在w r a 三个模式的后面套上一个+加号,使该模式又可读,又可写""" # (utf-8编码格式下 默认一个中文三个字节 一个英文或符号 占用一个字节) #read() 功能: 读取字符的个数(里面的参数代表字符个数) #seek() 功能: 调整指针的位置(里面的参数代表字节个数) # seek(0) 移动到文件的开头 # seek(0,2) 移动到文件的结尾 #tell() 功能: 当前光标左侧所有的字节数(返回字节数) # r+ 先读后写 # fp = open("0707_2.txt",mode="r+",encoding="utf-8") # res = fp.read() # print(res) # fp.write("789") # fp.close() # r+ 先写后读 fp = open("0707_2.txt",mode="r+",encoding="utf-8") # 把光标移动到最后,防止对原字符进行替换 fp.seek(0,2) fp.write("abc") # seek(0) 是把当前光标移动到开头,read默认以当前光标位置向右读取内容; fp.seek(0) res = fp.read() print(res) fp.close() # w+ 可读可写 fp = open("0707_3.txt",mode="w+",encoding="utf-8") fp.write("我可真迷人呀") fp.seek(0) res = fp.read() fp.close() print(res) # a+ 可读可写 (当写入内容时,强制吧光标移动到最后.) # (1)默认a模式可写 fp = open("0707_4.txt",mode="a",encoding="utf-8") fp.write("123456") # fp.read() error fp.close() # (2)a+模式可读可写 fp = open("0707_4.txt",mode="a+",encoding="utf-8") fp.write("123456") fp.seek(0) res = fp.read() fp.close() print(res) # (3) 追加内容时,光标是强制在最后的,如果是读取可以随意调整光标位置 fp = open("0707_4.txt",mode="a+",encoding="utf-8") fp.seek(0) fp.write("789") fp.close() # read seek tell 综合使用 # read后面加的参数值单位是字符个数,如果不写值,代表读取所有 # 例子1 fp = open("0707_5.txt",mode="r+",encoding="utf-8") fp.seek(3) res = fp.read(2) print(res) # 获取当前光标左侧所有的字节数的 res = fp.tell() print(res) fp.close() # 例子2 含有中文的时候要小心,一个中文代表的是3个字节.在移动seek的时候,容易出现乱码 """读中文字符如果不完整发生报错""" """ fp = open("0707_6.txt",mode="r+",encoding="utf-8") fp.seek(5) res = fp.read() print(res) """ # print("我".encode()) #xe6x88x91 # ### with 语法 可以自动实现关闭操作close() # 把文件内容读出来 # fp = open("集合.png",mode="rb") # res = fp.read() # fp.close() # 用with改写 as 就是起别名的意思 叫fp with open("集合.png",mode="rb") as fp: res = fp.read() # 把文件内容写到另外一个文件中 # fp = open("集合2.jpg",mode="wb") # fp.write(res) # fp.close() # 用with改写 as 就是起别名的意思 叫fp with open("集合2.jpg",mode="wb") as fp: fp.write(res) # 简化操作 with open("集合.png",mode="rb") as fp1 , open("集合3.jpg",mode="wb") as fp2: res = fp1.read() fp2.write(res)
12.文件相关函数
# ### 文件相关函数 # 1.文件对象可以遍历 文件对象也是一个可迭代性数据 """ fp = open("0707_7.txt",mode="r+",encoding="utf-8") #readable() 功能: 判断文件对象是否可读 res = fp.readable() print(res) #writable() 功能: 判断文件对象是否可写 res = fp.writable() print(res) # 文件对象可以遍历 ,默认遍历一次,读取一行 for i in fp: print(i) """ # 2.readline # (1)readline() 功能: 读取一行文件内容 """ readline(字符个数) 如果参数字符个数大于当前行所有的字符个数,那么读取当前行 如果参数字符个数小于当前行所有的字符个数,那么读取实际字符数 """ # 读出文件所有内容 with open("0707_7.txt",mode="r",encoding="utf-8") as fp: res = fp.readline(20) print(res) # res = fp.readline() # res = fp.readline() # print(res) # while res: # print(res) # res = fp.readline() # (2)readlines() 功能:将文件中的内容按照换行读取到列表当中 lst_new = [] with open("0707_7.txt",mode="r",encoding="utf-8") as fp: lst = fp.readlines() print(lst) for i in lst: res = i.strip() lst_new.append(res) print(lst_new) #writelines() 功能:将内容是字符串的可迭代性数据写入文件中 参数:内容为字符串类型的可迭代数据 """ 1.括号里的参数是可迭代性数据 2.内容的类型是字符串 """ with open("0707_8.txt",mode="w",encoding="utf-8") as fp: lst = ['我爱你 ', '美丽的哈姆雷特 ', '我喜欢你潇洒的面庞 ', '修长的手指头 ', '和 文雅的气质 ', '那忧郁的眼神 ', '让我神魂颠倒不能自拔 '] # lst = [1,2,3] error fp.writelines(lst) #truncate() 功能: 把要截取的字符串提取出来,然后清空内容将提取的字符串重新写入文件中 (字节) """ 总结: read(字符) seek(字节) readline(字符) truncate(字节) """