梯度下降(Gradient descent)
在有监督学习中,我们通常会构造一个损失函数来衡量实际输出和训练标签间的差异。通过不断更新参数,来使损失函数的值尽可能的小。梯度下降就是用来计算如何更新参数使得损失函数的值达到最小值(可能是局部最小或者全局最小)。
梯度下降计算流程
假设我们模型中的参数为 ,损失函数为
,损失函数为 ,则计算过程为
,则计算过程为

其中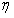 为学习率。通过不断求参数的偏导数来更新函数,直到(1)中的参数不在发生变化,就达到收敛状态。由于(1)的表达形式比较繁杂,因此可以简化如(3);其中(2)称作梯度
为学习率。通过不断求参数的偏导数来更新函数,直到(1)中的参数不在发生变化,就达到收敛状态。由于(1)的表达形式比较繁杂,因此可以简化如(3);其中(2)称作梯度

梯度下降数学解释
梯度下降的目的就是为了更新参数使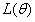 达到极小值。这个的过程如图1-1所示,①我们先随机初始化参数,就相当于在图1-1上任意取一点;②如果我们想要更新参数取到极小值的话,对于这一点可以寻找该点附近下降最快的方向,并沿着该方向移动一定距离;③移动距离后到达另外一个点,重复步骤②,直到该点没有可下降的方向,就取到极小值;
达到极小值。这个的过程如图1-1所示,①我们先随机初始化参数,就相当于在图1-1上任意取一点;②如果我们想要更新参数取到极小值的话,对于这一点可以寻找该点附近下降最快的方向,并沿着该方向移动一定距离;③移动距离后到达另外一个点,重复步骤②,直到该点没有可下降的方向,就取到极小值;

图1-1 梯度下降直观图
方向导数
上述的步骤②中,我们需要在某个点找到其附近下降最快的方向,这就需要先讨论方向导数;偏导数反应的是函数沿坐标轴变化率。但是,有时候我们考虑函数沿某个方向的变化率。便于讨论,以方向向量 代替方向。而向量的本质就是其在各个坐标轴(更严格点可以称作标准正交基)上的投影的值。因此,计算方向导数,可以转化为求解该方向向量在各个坐标轴上的投影的偏导数的总和。因此,对于函数f(x,y)在点p(x0,y0)可微分,那么函数在该点的任意方向的方向导数为
代替方向。而向量的本质就是其在各个坐标轴(更严格点可以称作标准正交基)上的投影的值。因此,计算方向导数,可以转化为求解该方向向量在各个坐标轴上的投影的偏导数的总和。因此,对于函数f(x,y)在点p(x0,y0)可微分,那么函数在该点的任意方向的方向导数为

其中为 方向跟x轴的余弦值,
方向跟x轴的余弦值, 为方向跟y轴的余弦值。
为方向跟y轴的余弦值。
梯度
方向导数是函数f(x,y)在点p(x0,y0)任意方向的变化率,而当在点的变化率取到最大值的方向就称为梯度,记作

其中i=(1,0),j=(0,1);f(x,y)在梯度方向上取得变化率最大值的证明如下:
对于(4)可以拆解成为两个向量的内积,设 ,
, ,则
,则

其中 都为定值;a就是梯度(5),b为方向的单位向量,即b跟方向相同;当a,b方向相同时,
都为定值;a就是梯度(5),b为方向的单位向量,即b跟方向相同;当a,b方向相同时, ,(6)取到最大值。因此,当方向向量与梯度相同时,f(x,y)在点p(x0,y0)的方向导数最大。
,(6)取到最大值。因此,当方向向量与梯度相同时,f(x,y)在点p(x0,y0)的方向导数最大。
学习率
学习率 控制着梯度下降收敛的速度,甚至影响到你的函数能否取到极小值。假设学习率跟损失函数值的关系如图1-2所示,当学习率设置的刚刚好(红色线段),那么刚好能够取到极小值,而且迭代次数也不多;当学习率设置太小的话(蓝色线段),也能够取到极小值,只是迭代的次数就增加;而但你的学习率设置过大的话(绿色线段),由于步长太大,无论如何都取不到极小值。
控制着梯度下降收敛的速度,甚至影响到你的函数能否取到极小值。假设学习率跟损失函数值的关系如图1-2所示,当学习率设置的刚刚好(红色线段),那么刚好能够取到极小值,而且迭代次数也不多;当学习率设置太小的话(蓝色线段),也能够取到极小值,只是迭代的次数就增加;而但你的学习率设置过大的话(绿色线段),由于步长太大,无论如何都取不到极小值。

图1-2 学习率跟损失函数值的关系
当损失函数的参数为一维或者二维才能够可视化出图1-2,如果有多维的参数的话,是无法可视化。因此,可以可视化迭代次数跟损失函数值之间的关系图,如图1-3所示。

图1-3 迭代次数跟损失函数值
自适应学习率
在迭代的过程中,学习率不应该是一成不变的。因为在刚开始迭代的时候,初始点跟最终的极小值之间是有较远的距离,因此此时可以学习率可以设置的大一些。但是当快接近极小值时,就应该减小学习率,以避免步长过大,错过极小值;
一种简单的学习率设置如(7),随着迭代次数增加, 的值就越来越小
的值就越来越小

虽然(7)可以使得学习率随着迭代次数增加而减少,但是更理想的情况应该是,对不同的参数,应该设置不同的学习率。
Adagrad
Adagrad是将学习率的取值跟之前所有偏微分值的均方值的根号有关系。以单个参数为例,具体的计算如下

其中, 为(7);
为(7); 表示对
表示对 的偏导数;
的偏导数; 表示将先前所有对参数的偏导数的平方进行累加,并求均值,最后再取根号;
表示将先前所有对参数的偏导数的平方进行累加,并求均值,最后再取根号;
随机梯度下降(Stochastic Gradient Descent)
在进行梯度下降时,我们构造的损失函数为(10),此时我们是将所有的样本都考虑进来,在进行参数更新。

而随机梯度下降则是每次随机选择一个样本x,就对参数进行更新。对应的损失函数为

采用随机梯度下降的话,参数的更新速度会更快一些。假设我们有20个样本,那么对于随机梯度下降则是选择一个样本就更新一次参数,选择完20个样本也就更新20次;对于梯度下降的话,构造(10)就是构造20个(11),并将20个(11)进行累加,再进行参数更新,选择20个样本只完成一次更新。
特征缩放(Feature Scaling)
不同的特征的取值范围往往是不同的,因此特征的取值变化对最终的输出结果也有不一样的效果。以(12)为例,若 ,显然y的取值受x2的影响更多;但如果实际中x1才是最重要的特征,就会导致最终的拟合效果不佳。
,显然y的取值受x2的影响更多;但如果实际中x1才是最重要的特征,就会导致最终的拟合效果不佳。

不同的特征变化范围也会影响梯度下降的收敛速度,如图1-4。由于不同特征的取值范围就导致不同的参数应该采用不同的参数,否则收敛就会有难度;而将特征进行相同特征处理后,这个损失函数等高线呈圆形,采用相同的参数也可以完成收敛。
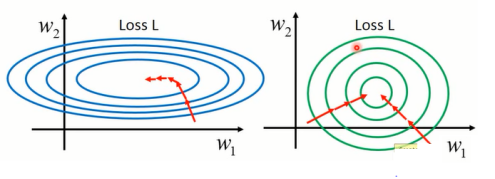
图1-4 特征缩放对收敛的影响
均值归一化
对于单个特征 来说,计算如下
来说,计算如下

其中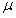 为的X均值,s为X的标准差(Standard Deviation)
为的X均值,s为X的标准差(Standard Deviation)