import numpy as np from sklearn import datasets from sklearn.cross_validation import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.cross_validation import cross_val_score iris = datasets.load_iris() iris_X = iris.data iris_Y = iris.target knn = KNeighborsClassifier() scores = cross_val_score(knn,iris_X,iris_Y,cv=5,scoring="accuracy") print(scores.mean())
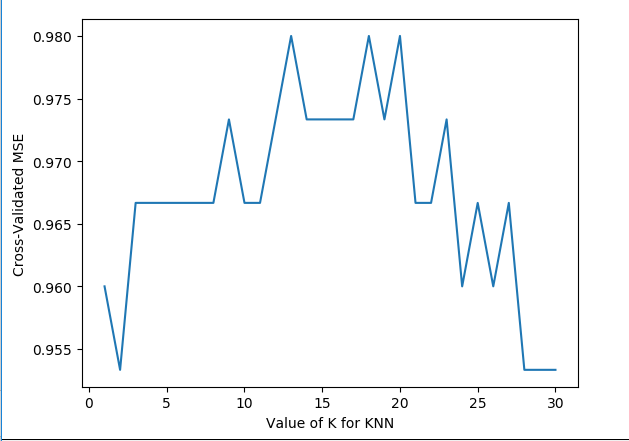
import numpy as np from sklearn import datasets from sklearn.cross_validation import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.cross_validation import cross_val_score import matplotlib.pyplot as plt iris = datasets.load_iris() iris_X = iris.data iris_Y = iris.target k_range = range(1,31) k_score = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) # cv:分成五组 scores = cross_val_score(knn, iris_X, iris_Y, cv=10, scoring="accuracy") k_score.append(scores.mean()) plt.plot(k_range, k_score) plt.xlabel('Value of K for KNN') plt.ylabel('Cross-Validated MSE') plt.show()
一般来说准确率(accuracy)会用于判断分类(Classification)模型的好坏。
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')一般来说平均方差(Mean squared error)会用于判断回归(Regression)模型的好坏。
loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error')