一、Python的简介
1.什么是python?
Python(发音:[ 'paiθ(ə)n; (US) 'paiθɔn ]),是一种面向对象的解释性的计算机程序设计语言,也是一种功能强大而完善的通用型语言,已经具有十多年的发展历史,成熟且稳定。这种语言具有非常简捷而清晰的语法特点,适合完成各种高层任务,几乎可以在所有的操作系统中运行。
- 特点:
①可扩充性。新的内置模块(module)可以用C 或 C++写成,而我们也可为现成的模块加上Python的接口;
②清晰的语言。因为它的作者在设计它的时候,总的指导思想是,对于一个特定的问题,只要有一种最好的方法来解决就好了。
③Python的缩进规则。它的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。这样有意的强制程序员养成良好的编程习惯。一个模块的界限,完全是由每行的首字符在这一行的位置来决定的(而C语言是用一对花括号{}来明确的定出模块的边界的,与字符的位置毫无关系)。
- 局限性:
①运行效率低下;
②多线程支持欠佳 ;
③独特的语法。这也许不应该被称为局限,但是它用缩进来区分语句关系的方式还是给很多初学者带来了困惑。 即便是很有经验的Python程序员,也可能陷入陷阱当中。最常见的情况是tab和空格的混用会导致错误,而这是用肉眼无法分别的。
④无类型。作为一种动态语言,随时随地创建和使用变量是Python给我们带来的巨大的便利。但是它也会使得程序不严谨,某些错误只有在运行中才可能出现。所以,使用Python编程的时候,要对类型做到心里有数。
2.python的过去
Python的创始人为Guido van Rossum。1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,做为 ABC 语言的一种继承。之所以选Python(大蟒蛇的意思)作为程序的名字,是因为他是一个Monty Python的飞行马戏团的爱好者。就这样,Python在Guido手中诞生了。实际上,第一个实现是在Mac机上。可以说,Python是从ABC发展起来,主要受到了Modula-3(另一种相当优美且强大的语言,为小型团体所设计的)的影响。并且结合了Unix shell和C的习惯。
3.python的现在
如图所示,截止17年4月,最新的TIOBE排行榜,python位列第五。
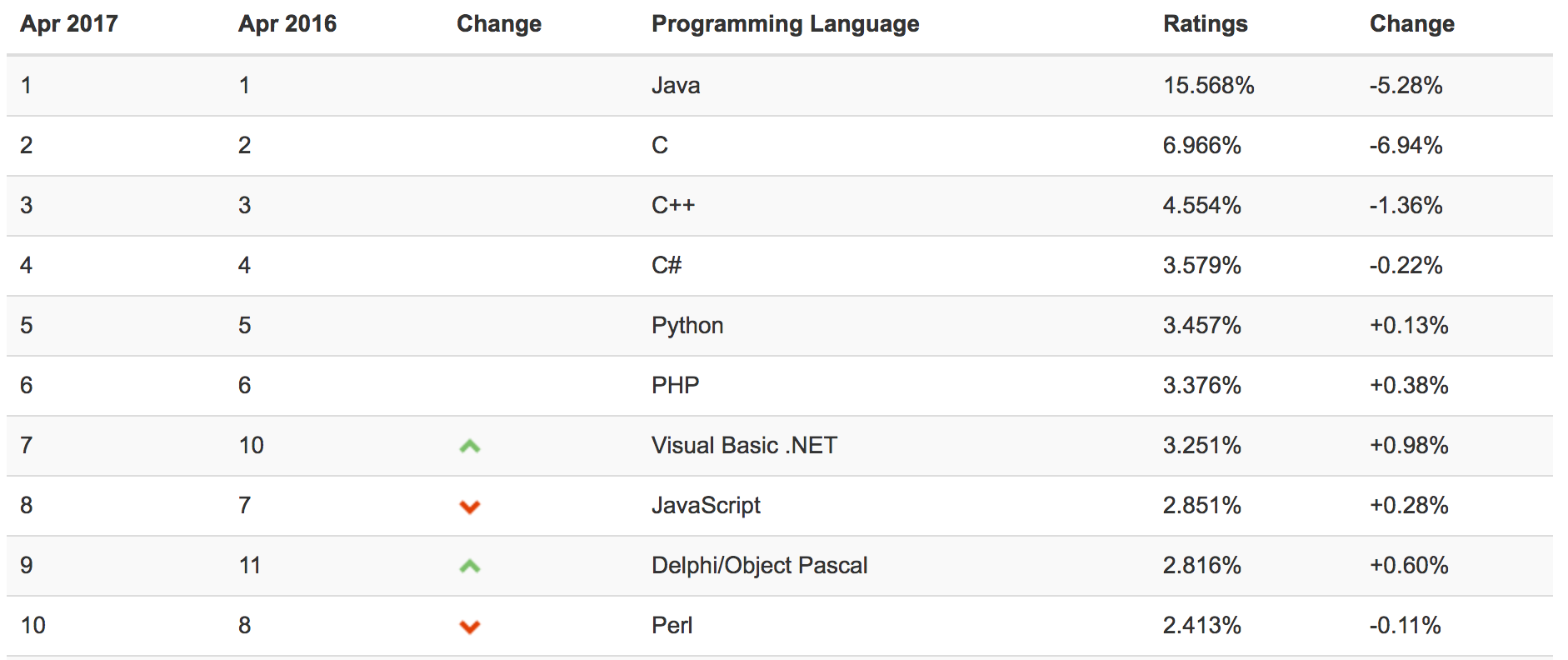
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
4.python与其他语言的关系
- 对比:
Pythond VS C#
① Python跨平台,可以运行在Linux、weindows等平台
② Pythond开源,C#则相反
③Python是解释型语言,C#需要编译,所以Python运行要慢点
Pythond VS Java
Python更简洁,Java过于庞大复杂,语法很多
Python VS C C++
Python更容易学习,语法简单易懂,但他们通常扮演不同的角色,Python是一种脚本语言,C和C++通常要和底层硬件打交道
Python VS Ruby Perl
与ruby不同,OOP对于Python是可选的,所以Python不会强制用户选择OOP开发
- 联系:
C语言: 代码编译得到机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作(C语言--》机器码--》计算机)
Python在执行时,首先会将.py文件中的源代码编译成Python编程语言的byte code(字节码),然后再由Python Virtual Machine来执行这些编译好的byte code。
其他语言: 代码编译得到字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行。(其他高级语言--》字节码--》机器码--》计算机)
5.python的种类
- Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 - Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。 - IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似) - PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。 - RubyPython、Brython ...
以上除PyPy之外,其他的Python的对应关系和执行流程如下:


PyPy,在Python的基础上对Python的字节码进一步处理,从而提升执行速度!
二、Python的基础
1.python的安装(MAC)
可参考网站
https://github.com/pyenv/pyenv https://github.com/pyenv/pyenv-virtualenv https://www.cnhzz.com/pyenv_virtualenv_virtaulenvwrapper/
pyenv virtualenv 3.5.3 py3 #创建一个 Python 版本为 3.5.3 的环境, 环境叫做 py3 pyenv activate py3 #激活 py3 这个环境, 此时 Python 版本自动变为 3.5.3, 且是独立环境 pyenv deactivate #离开已经激活的环境
2.第一句Python代码
在 /home/dev/ 目录下创建 hello.py 文件,内容如下:
1 print "hello,world"
执行 hello.py 文件,即: python /home/dev/hello.py
python内部执行过程如下:
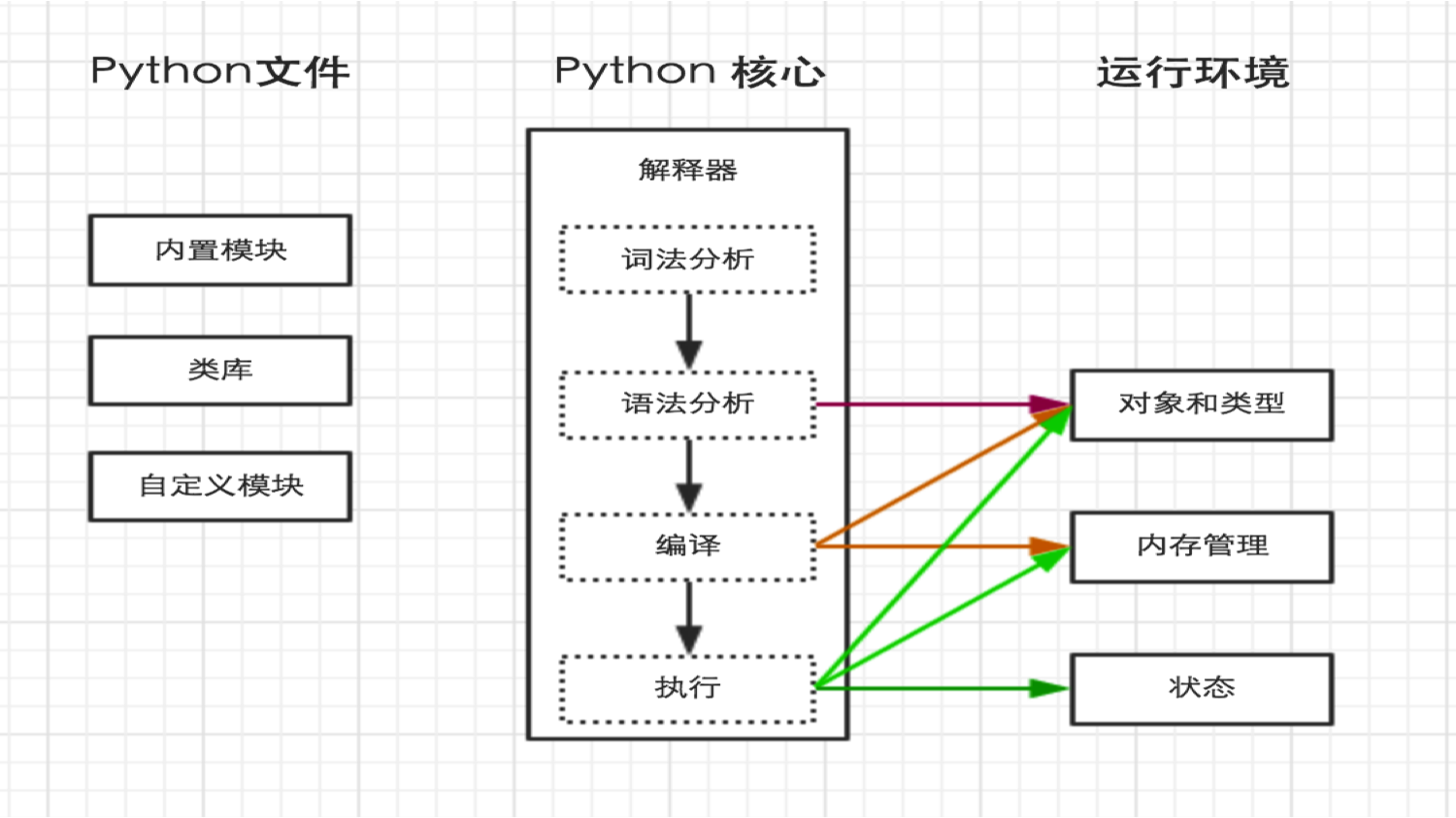
3.解释器
上一步中执行 python /home/dev/hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
1 #!/usr/bin/env python
2 print "hello,world"
如此一来,执行: ./hello.py 即可。
补充:
①执行前需给予 hello.py 执行权限,chmod 755 hello.py
②脚本语言的第一行,目的就是指出,你想要你的这个文件中的代码用什么可执行程序去运行它,就这么简单
#!/usr/bin/Python是告诉操作系统执行这个脚本的时候,调用/usr/bin下的python解释器;
#!/usr/bin/env python这种用法是为了防止操作系统用户没有将python装在默认的/usr/bin路径里。当系统看到这一行的时候,首先会到env设置里查找python的安装路径,再调用对应路径下的解释器程序完成操作。
#!/usr/bin/python相当于写死了python路径;
#!/usr/bin/env python会去环境设置寻找python目录,推荐这种写法。
4.编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码。
注:python3默认utf-8,python2默认是ASCII
ASCII(American Standard Code for Information Interchange),是一种单字节的编码。主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
显然ASCII码无法将世界上的各种文字和符号全部表示,比如中文,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是至少2个字节(16位),可能更多
gbk,gb2312 ,只适用于中国,支持繁体,中文需要2个字节表示
UTF-8,是对Unicode编码的压缩和优化,遵循能用最少的表示就用最少的表示,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,在写代码时,为了不出现乱码,推荐使用UTF-8,会加入 # -*- coding: utf-8 -*-
即
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
5. IDE
pycharm
- 使用
1. new project
2. new 创建文件夹
3. new 创建py文件
4. 在py文件中右键, run xx.py
- 文件编码
- 文件模板
- 改变大小
6.注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
选中注释,ctrl+?
7.pyc文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
注:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
三、python的基础语法和规则
1.变量
①.变量的命名规则
语法:
(下划线或字母)+(任意数目的字母、数字或下划线)
变量名必须以下划线或字母开头,而后面接任意数目的字母、数字或下划线。下划线分割。
区分大小写: SPAM和spam不同
不能使用python内置关键字,以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
②声明变量
1 # !/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 age = 19 4 print(age)
上述代码声明了一个变量,变量名为: age,变量age的值为:"18"
变量的作用:昵称,其代指内存里某个地址中保存的内容
2.输入和输出

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 将用户输入的内容赋值给 name 变量
name = raw_input("请输入用户名:")
# 打印输入的内容
print name
如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 import getpass
5
6 # 将用户输入的内容赋值给 name 变量
7 pwd = getpass.getpass("请输入密码:")
8
9 # 打印输入的内容
10 print pwd
注: getpass方法不能直接在IDE中执行,应该去终端执行,方能实现不可见功能。
3.判断语句
语法:
1 if 条件 and 条件2:
2 print('True')
3 elif 条件:
4 print('')
5 else:
6 print('Flase')
注意缩进,空四格。
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 import getpass
4 Type = input('请输入职业:')
5 if Type == "学生":
6 name = input('请输入用户名')
7 if name == 'hexin':
8 passwd = getpass.getpass('请输入密码:')
9 if passwd == '1234':
10 print('验证成功,欢迎登录',name)
11 else:
12 print('验证失败,再见')
4.循环语句
语法:
while 条件:
# 循环体
# 如果条件为真,那么循环体则执行
# 如果条件为假,那么循环体不执行
i = 1
value = 0
while i < 101:
i += 1
value = value + i
print(value)
四、python的基本数据类型

注:运算符的执行顺序,从前往后
2、比较运算:

3、赋值运算:

4、逻辑运算:

5、成员运算:

6、整数
- 创建
- 转换
- 查看数据类型
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
- 创建
- 转换
- 创建
- 转换
- 字符串的拼接
name = '1' gender = '女' new_str = name + gender print(new_str)
- 字符串格式化
1 name = '我是%s,年龄%d'%('hexin',18)
2 # new_name = name%('hexin',18)
3 print(name)
%d,占位符,数字
- 判断子序列是否在其中
content = "123是女孩"
if "是" in content:
print('包含敏感字符')
else:
print(content)
- 移除空白
val = " 123 " print(val) # new_val = val.strip() # 左右 # new_val = val.lstrip()# 左边 # new_val = val.rstrip() # 右边 # print(new_val)
- 分割
user_info = "t sb123 9"
# v = user_info.split('|')
# v = user_info.split('|',1)
# v = user_info.rsplit(' ',1)
- 长度
val = "sb" v = len(val) print(v)
- 索引
val = "sb"
v = val[0]
print(v)
val = input('>>>')
i = 0
while i < len(val):
print(val[i])
i += 1
- 切片
name = '我叫123,性别我今年18岁,我在说谎!' print(name[0]) print(name[0:2]) print(name[5:9]) print(name[5:]) print(name[5:-2]) print(name[-2:])
9.列表
- 创建:
a = ['dog','狗','eric',123] a = list(['dog','狗','eric',123])
- in判断:
if 'do' in a: pass
if 'do' in a[0]: pass
- 索引:
val = a[0]
- 长度:
val = len(a)
- 切片:
a = ['dog','狗','eric',123] v = a[0::2] print(v)
- 追加:
a = ['dog','狗','eric',123]
a.append('xxoo')
print(a)
- 插入:
a = ['dog','狗','eric',123] a.insert(0,'牛') print(a)
- 删除:
a = ['dog','eric','狗','eric',123]
# a.remove('eric')
del a[0]
print(a)
- 更新:
a = ['dog','eric','狗','eric',123] a[1] = '阿斯顿发送到' print(a)
- For循环:
a = ['dog','eric','狗','eric',123] for item in a: print(item) # break # continue
10.字典操作
- 创建
v = {
'name': 'dog',
'password': '123123'
}
- 索引获取值
# n = v['name'] # print(n)
- 增加,无,增加;有,修改
# v['age'] = 19 # print(v)
- 删除
# del v['name'] # print(v)
- 循环
# for item in v.keys(): # print(item) # for item in v.values(): # print(item) # for key,val in v.items(): # print(key,val)
- 长度
print(len(user_dict))
- 相互嵌套
user_dict = {
'k1': 'v1',
'k2': {'kk1':'vv1','kk2':'vv2'},
'k3': 123,
'k4': ['tom','eric',['a','b','c'],'dog',{'k11':'vv1'}],
}
user_dict['k4'][2].append('123')
user_dict['k4'][4]['n'] = '过啥龙'
- 应用:
user_list = [
{'name':'dog','pwd':'123123','times':1},
{'name':'eric','pwd':'123123','times':1},
{'name':'tony','pwd':'123123','times':1},
]
user = input('用户名:')
pwd = input('密码:')
for item in user_list:
if user == item['name'] and pwd == item['pwd']:
print('登录成功')
break
11.文件操作
- 打开并读取
f1 = open('db','r')
data = f1.read()
f1.close()
- 清空并写入
f2 = open('db','w')
f2.write(target)
f2.close()