Part Ⅰ 视频学习心得及问题总结
1.绪论
1.1从专家系统到机器学习
1.1.1人工智能的发展经历了三个阶段:推理期、知识期、学习期。

- 知识工程/专家系统——根据专家定义的知识与经验,进行推理和判断,从而模拟人类专家的决策过程来解决问题。
- 机器学习——从数据中自动的提取出知识或模式。
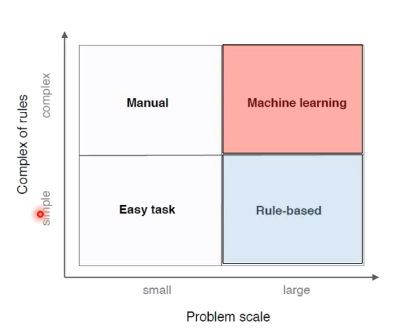
1.1.2专家系统vs机器学习
| 专家系统 | 机器学习 |
|---|---|
| 基于手工设计规则建立专家系统 | 基于数据自动学习 |
| 结果容易解释 | 减少人工繁杂工作,但结果可能不易解释 |
| 系统构建费时费力 | 提高信息处理的效率,且准确率较高 |
| 依赖于专家主观经验,难以保证一致性和准确性 | 来源于真实数据,减少人工规则主观性,可信度高 |
 |
1.2从传统机器学习到深度学习
1.2.1 传统机器学习
在实际应用中,特征比分类器更重要。原始数据经过数据预处理、特征提取、特征选择,最后经过分类预测识别得到最后的结果。在传统的机器学习中,人工会去手动的设计特征。
1.2.2 深度学习
在深度学习中,首先选择深度学习的模型以及模型的参数,然后把收集到的数据和选择好的模型交给计算机,让计算机去优化这个深度模型中的参数。在这个过程中,人工参与的部分比较少,可能只是在前期收集数据和选择深度模型有一定程度的参与。
1.3深度学习的能与不能
了解深度学习的能与不能,对我们拓展深度学习的应用的研究具有比较深刻的意义。
1.3.1 深度学习之能——视觉与语义结合
在这里,我们介绍视觉与语义的结合,语义slam的原理和技术框架。语义slam不仅要获得环境几何信息,还要收集个体的位置姿态和功能属性等语义信息,以获得更加智能的结果。语义slam的技术框架:语义提取(图像的处理、对图像进行识别和分割、加语义标签)+slam的定位与建图
1.3.2 深度学习之不能
- 算法输出不稳定,容易被攻击(改变图像的像素点,可能导致识别的结果发生偏差)
- 模型的复杂度高,难以纠错和调试(谷歌翻译出错,难以修改)
- 模型层级复合程度高,参数不透明
- 端到端训练方式对数据依赖性强,模型增量性差
- 专注直观感知类问题,对开放性推理问题无能为力(鹦鹉学语,乌鸦喝水)
- 人类知识无法有效引入进行监督,机器偏见难以避免(谷歌在识别一些黑人的图像时,会显示识别结果为大猩猩,这是一种严重的种族歧视)
2.深度学习概述
2.1浅层神经网络
2.1.1生物神经元到单层感知器,多层感知器
-
生物神经元
多输入单输出的信息处理单元;具有阈值特性;分为兴奋性和抑制性;具有空间整合和时间整合特性。 -
M-P神经元
具有多个输入,每个输入对应一个权值,这个权值需要预先设定,所以M-P神经元没有学习能力。每个神经元还有一个阈值和一个激活函数。

-
单层感知器
单层感知器的结构与M-P神经元一致,但是单层感知器中的权值是可以通过学习来改变的,所以单层感知器是首个可以学习的人工神经网络。 -
多层感知器
由于单层感知器并不能解决非线性问题,多层感知器由此而生。多层感知器是在一层单层感知器的基础,叠加一层单层感知器,从而解决非线性问题(例如异或问题)。
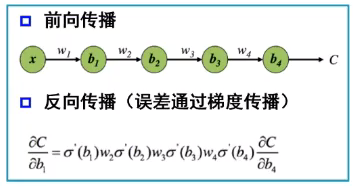
2.1.2反向传播
误差的反向传播,对参数进行更新,实现对神经网络的学习过程。网络建立之后,数据从输入层进入,经过隐含层的调整,最后得到一个输出,与实际的输出相比较,就会产生一个误差。
2.1.3梯度消失
- 万有逼近定理
单隐层:如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数
双隐层:当隐层足够宽时,双隐层感知器(输入-隐层-隐层-输出)可以逼近任意非连续函数,可以解决任何复杂的分类问题 - 神经网络结构的作用
增加节点数:增加维度,增加线性转换能力
增加层数:增加激活函数的次数,增加非线性转换次数
神经网络的作用:学习如何利用矩阵的线性变换和激活函数的非线性变换,将原始输入空间投影到线性可分的空间去分类和回归 - 深度和宽度的增加对函数复杂度的贡献是不同的,深度的增加的贡献是指数增加,而宽度的增加的贡献是线性增加的。在神经元数目相同的情况下,增加网络深度可以比增加网络宽度带来更强的网络表示能力。
- 但是,一味的增加深度也是不行的。因为,在实践中发现多层神经网络存在一些问题:首先,增加深度会造成梯度消失,误差无法传播;其次,多层网络容易陷入局部极值,难以训练。这两个问题,都导致多层神经网络无法实现网络的更新。
- 梯度消失的原因:误差是通过梯度反向传播的,但是在这个反向传播过程中,到了某一层的梯度变成了零,这就是梯度消失。梯度消失使反向传播没有了意义,因为并没有实现参数的更新,而神经网络也并没有进行学习。
2.2神经网络到深度学习
对于多层神经网络存在的两个问题,对应的会有相应的对策。由此,才使深度学习成为了现实。
| 问题 | 解决对策 |
|---|---|
| 增加深度会造成梯度消失,误差无法传播 | 三层神经网络是主流 |
| 多层网络容易陷入局部极值,难以训练 | 预训练、使用新的激活函数 |
2.2.1逐层预训练

在这个过程中,逐层进行预训练,将训练结果逐层叠加,直至最后一层提供一个监督信息,然后根据这个监督信息进行微调。
2.2.2自编码器
- 假设输入与输出相同,把自身的输入作为监督信息,没有额外的输入信息
- 误差来源于直接重构后信号与原输入相比得到的
- 训练目标是使输出层与输入层误差最小
- 最终的预训练,是在每一层建立一个自编码器,形成堆叠自编码器。然后逐层重构,直到最后一层的监督信息,然后进行反向微调
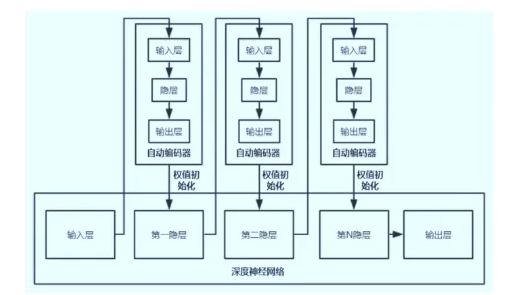
- 这里要注意的是,自编码器不一定是三层的,也可能是很多层。但是,他的基本结构是编码-解码的这样一个框架的。
Part Ⅱ 代码练习
1.图像处理基本练习
子模块名称 主要实现功能
io 读取、保存和显示图片或视频
data 提供一些测试图片和样本数据
color 颜色空间变换
filters 图像增强、边缘检测、排序滤波器、自动阈值等
draw 操作于numpy数组上的基本图形绘制,包括线条、矩形、圆和文本等
transform 几何变换或其它变换,如旋转、拉伸和拉东变换等
morphology 形态学操作,如开闭运算、骨架提取等
exposure 图片强度调整,如亮度调整、直方图均衡等
feature 特征检测与提取等
measure 图像属性的测量,如相似性或等高线等
segmentation 图像分割
restoration 图像恢复
util 通用函数
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import skimage#skimage是一个数字图像处理库
from skimage import data#data模块含有很多图片
from skimage import io#读取、保存和显示图片或视频
colony = io.imread('yeast_colony_array.jpg')
print(type(colony))#skimage.io读出来的数据是numpy格式的
print(colony.shape)#输出可以看出skimage读图片的大小的是(height,width, channel)
<class 'numpy.ndarray'>
(406, 604, 3)
astronaut 航员图片 coffee 一杯咖啡图片
lena lena美女图片 camera 拿相机的人图片
coins 硬币图片 moon 月亮图片
checkerboard 棋盘图片 horse 马图片
page 书页图片 chelsea 小猫图片
hubble_deep_field 星空图片 text 文字图片
clock 时钟图片 immunohistochemistry 结肠图片
#如果我们想知道一些skimage图片信息
from skimage import io, data
img = data.chelsea()
io.imshow(img)
print(type(img)) #显示类型
print(img.shape) #显示尺寸
print(img.shape[0]) #图片高度
print(img.shape[1]) #图片宽度
print(img.shape[2]) #图片通道数
print(img.size) #显示总像素个数
print(img.max()) #最大像素值
print(img.min()) #最小像素值
print(img.mean()) #像素平均值
print(img[0][0])#图像的像素值
#图片通道问题
#描述一个像素点,如果是灰度,那么只需要一个数值来,就是单通道
#如果一个像素点,有RGB三种颜色来描述它,就是三通道。RGB三通道分别对应0,1,2
#而四通道图像,就是R、G、B加上一个A通道,表示透明度。
#通过通道可以改变图像的色相和颜色,例如如果你保存红色通道,那么图像本身就只保留红色的元素和信息。
#一幅图像,如果关闭了红色通道,那么图像就偏青色。如果关闭了绿色通道,那么图像就偏洋红色。如果关闭了蓝色通道,那么图像就偏黄色。
# Plot all channels of a real image
plt.subplot(121)#一行两列第一个位置
plt.imshow(colony[:,:,:])#显示三通道
plt.title('3-channel image')
plt.axis('off')
# Plot one channel only
plt.subplot(122)#一行两列第二个位置
plt.imshow(colony[:,:,0])#显示R通道
plt.title('1-channel image')
plt.axis('off');
# Get the pixel value at row 10, column 10 on the 10th row and 20th column
camera = data.camera()#512*512的二维矩阵
print(camera[10, 20])
# Set a region to black
camera[30:100, 10:100] = 0 #0-black 255-white
plt.imshow(camera, 'gray')
# Set the first ten lines to black
camera = data.camera()
camera[:10] = 0
plt.imshow(camera, 'gray')
# Set to "white" (255) pixels where mask is True
camera = data.camera()
mask = camera < 80#bool型矩阵
camera[mask] = 255#注意这个形式
plt.imshow(camera, 'gray')
# Change the color for real images
cat = data.chelsea()
# Set brighter pixels to red
red_cat = cat.copy()#不对原图像产生任何影响
reddish = cat[:, :,0] > 160
red_cat[reddish] = [255, 0,0]
plt.imshow(red_cat)
# Change RGB color to BGR for openCV
BGR_cat = cat[:, :, ::-1]#openCV使用BGR形式,而非RGB形式
plt.imshow(BGR_cat)
#图像数据类型转换
Data type Range
uint8 0 to 255
uint16 0 to 65535
uint32 0 to 232
float -1 to 1 or 0 to 1
int8 -128 to 127
int16 -32768 to 32767
int32 -231 to 231 - 1
from skimage import img_as_float, img_as_ubyte
float_cat = img_as_float(cat)#uint8转float
uint_cat = img_as_ubyte(float_cat)#float转uint8;float转为unit8,有可能会造成数据的损失,因此会有警告提醒
#常用类型转换函数
Function name Description
img_as_float Convert to 64-bit floating point.
img_as_ubyte Convert to 8-bit uint.
img_as_uint Convert to 16-bit uint.
img_as_int Convert to 16-bit int.
#图像像素直方图统计
img = data.camera()
print(img)
plt.hist(img.ravel(), bins=256, histtype='step', color='black');#ravel()将多维数组降维成一维,会影响原始矩阵; flatten()同样降维成一维,但是不影响原始矩阵
#图像分割
# Use colony image for segmentation
colony = io.imread('yeast_colony_array.jpg')
# Plot histogram
img = skimage.color.rgb2gray(colony)#转灰度图
plt.hist(img.ravel(), bins=256, histtype='step', color='black');
#图像颜色空间转换常用函数
skimage.color.rgb2grey(rgb)
skimage.color.rgb2hsv(rgb)
skimage.color.rgb2lab(rgb)
skimage.color.gray2rgb(image)
skimage.color.hsv2rgb(hsv)
skimage.color.lab2rgb(lab)
plt.imshow(img>0.5)#???
from skimage.feature import canny
from scipy import ndimage as ndi
img_edges = canny(img)#描绘图像边缘
img_filled = ndi.binary_fill_holes(img_edges)#沿着图像边缘把图像填满
# Plot
plt.figure(figsize=(18, 12))
plt.subplot(121)
plt.imshow(img_edges, 'gray')
plt.subplot(122)
plt.imshow(img_filled, 'gray')
颜色图谱 描述
autumn 红-橙-黄
bone 黑-白,x线
cool 青-洋红
copper 黑-铜
flag 红-白-蓝-黑
gray 黑-白
hot 黑-红-黄-白
hsv hsv颜色空间, 红-黄-绿-青-蓝-洋红-红
inferno 黑-红-黄
jet 蓝-青-黄-红
magma 黑-红-白
pink 黑-粉-白
plasma 绿-红-黄
prism 红-黄-绿-蓝-紫-...-绿模式
spring 洋红-黄
summer 绿-黄
viridis 蓝-绿-黄
winter 蓝-绿
直方图均衡化就是一种能仅靠输入图像直方图信息自动达到这种效果(得到高对比度的图像)的变换函数。它的基本思想是对图像中像素个数多的灰度级进行展宽,而对图像中像素个数少的灰度进行压缩,从而扩展取值的动态范围,提高了对比度和灰度色调的变化,使图像更加清晰。那么这个过程就被称为直方图均衡化。而直方图均衡后的图像的累计分布函数大致是线性的。
# Load an example image
img = data.camera()
plt.imshow(img, 'gray')
# Contrast stretching
##对比度拉伸
from skimage import exposure
p2, p98 = np.percentile(img, (2, 98))#计算一个多维数组的任意百分比分位数,此处的百分位是从小到大排列,只需用np.percentile即可;计算图像的像素的
img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98))
plt.imshow(img_rescale, 'gray')
# Equalization
## 直方图均衡化
img_eq = exposure.equalize_hist(img)
plt.imshow(img_eq, 'gray')
# Adaptive Equalization
# 局部对比度增强
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)
plt.imshow(img_adapteq, 'gray')
# Display results
def plot_img_and_hist(img, axes, bins=256):
"""Plot an image along with its histogram and cumulative histogram.
"""
img = img_as_float(img)
ax_img, ax_hist = axes
ax_cdf = ax_hist.twinx()#twinx()函数表示共享x轴;twiny()表示共享y轴
# Display image绘图
ax_img.imshow(img, cmap=plt.cm.gray)
ax_img.set_axis_off()#坐标系不可见
ax_img.set_adjustable('box')
# Display histogram
ax_hist.hist(img.ravel(), bins=bins, histtype='step', color='black')
ax_hist.ticklabel_format(axis='y', style='scientific', scilimits=(0, 0))
ax_hist.set_xlabel('Pixel intensity')
ax_hist.set_xlim(0, 1)
ax_hist.set_yticks([])
# Display cumulative distribution累计分布函数
img_cdf, bins = exposure.cumulative_distribution(img, bins)
ax_cdf.plot(bins, img_cdf, 'r')
ax_cdf.set_yticks([])
return ax_img, ax_hist, ax_cdf
fig = plt.figure(figsize=(16, 8))
axes = np.zeros((2, 4), dtype=np.object)
axes[0, 0] = fig.add_subplot(2, 4, 1)
for i in range(1, 4):
axes[0, i] = fig.add_subplot(2, 4, 1+i, sharex=axes[0,0], sharey=axes[0,0])
for i in range(0, 4):
axes[1, i] = fig.add_subplot(2, 4, 5+i)
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img, axes[:, 0])
ax_img.set_title('Low contrast image')
y_min, y_max = ax_hist.get_ylim()
ax_hist.set_ylabel('Number of pixels')
ax_hist.set_yticks(np.linspace(0, y_max, 5))
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_rescale, axes[:, 1])
ax_img.set_title('Contrast stretching')
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_eq, axes[:, 2])
ax_img.set_title('Histogram equalization')
ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_adapteq, axes[:, 3])
ax_img.set_title('Adaptive equalization')
ax_cdf.set_ylabel('Fraction of total intensity')
ax_cdf.set_yticks(np.linspace(0, 1, 5))
fig.tight_layout()
plt.show()
2.pytorch 基础练习
2.1定义数据
pytorch具有两种数据类型:Tensor和Variable
2.1.1Tensor
Pytorch里面处理的最基本的操作对象就是Tensor(张量),其实就是一个多维矩阵,并有矩阵相关的运算操作。
Tensor支持各种各样类型的数据,包括:torch.float32, torch.float64, torch.float16, torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64。
创建Tensor有多种方法,包括:ones, zeros, eye, arange, linspace, rand, randn, normal, uniform, randperm.....
# 可以是一维数组(向量)
x = torch.tensor([1,2,3,4,5,6])
print(x)
tensor([1, 2, 3, 4, 5, 6])
# 可以是二维数组(矩阵)
x = torch.ones(2,3)
print(x)
tensor([[1., 1., 1.],
[1., 1., 1.]])
# 可以是任意维度的数组(张量)
x = torch.ones(2,3,4)
print(x)
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
x = torch.empty(5,3)
print(x)
tensor([[8.5919e-36, 0.0000e+00, 3.3631e-44],
[0.0000e+00, nan, 0.0000e+00],
[1.1578e+27, 1.1362e+30, 7.1547e+22],
[4.5828e+30, 1.2121e+04, 7.1846e+22],
[9.2198e-39, 7.0374e+22, 0.0000e+00]])
# 创建一个随机初始化的张量
x = torch.rand(5,3)
print(x)
tensor([[0.3192, 0.8946, 0.0310],
[0.2872, 0.6571, 0.9302],
[0.2974, 0.0274, 0.7934],
[0.1466, 0.6276, 0.1238],
[0.9328, 0.2548, 0.7596]])
# 创建一个全0的张量,里面的数据类型为 long
x = torch.zeros(5,3,dtype=torch.long)
print(x)
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
# 基于现有的tensor,创建一个新tensor,
# 从而可以利用原有的tensor的dtype,device,size之类的属性信息
y = x.new_ones(5,3) #tensor new_* 方法,利用原来tensor的dtype,device
print(y)
tensor([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]])
z = torch.randn_like(x, dtype=torch.float)
# 利用原来的tensor的大小,但是重新定义了dtype
print(z)
tensor([[-1.0960, -0.4387, 2.0565],
[-1.6043, 0.1653, -0.1710],
[ 0.9969, 1.4946, 1.0085],
[ 0.8282, 1.1303, 0.9358],
[ 1.0664, -0.2047, 0.5249]])
2.1.1Variable
Pytorch里面的Variable类型数据功能更加强大,相当于是在Tensor外层套了一个壳子,这个壳子赋予了前向传播,反向传播,自动求导等功能,在计算图的构建中起的很重要的作用。
其中最重要的两个属性是:data和grad。Data表示该变量保存的实际数据,通过该属性可以访问到它所保存的原始张量类型,而关于该 variable(变量)的梯度会被累计到.grad 上去。
import torch
from torch.autograd import Variable
# 定义三个Variable变量
x = Variable(torch.Tensor([1, 2, 3]), requires_grad=True)
w = Variable(torch.Tensor([2, 3, 4]), requires_grad=True)
b = Variable(torch.Tensor([3, 4, 5]), requires_grad=True)
# 构建计算图,公式为:y = w * x^2 + b
y = w * x * x + b
# 自动求导,计算梯度
y.backward(torch.Tensor([1, 1, 1]))
print(x.grad)
print(w.grad)
print(b.grad)
#上述代码的计算图为y = w * x^2 + b。对x, w, b分别求偏导为:x.grad = 2wx,w.grad=x^2,b.grad=1
2.2定义操作
- 基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等具体在使用的时候可以百度一下
- 布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
- 线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等
3.螺旋数据分类
对于线性模型与两层神经网络模型训练的结果的差距,是由于在模型中加入了一层激活函数。线性模型进行的仅仅是矩阵运算,加入了激活函数,改变这一特性。
对于常用的激活函数,进行相关的整理:
sigmod
在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率。sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。
当然,流行也是曾经流行,这说明函数本身是有一定的缺陷的。
-
当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。
-
函数输出不是以0为中心的,这样会使权重更新效率降低。对于这个缺陷,在斯坦福的课程里面有详细的解释。
-
sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
tanh
首先相同的是,这两个函数在输入很大或是很小的时候,输出都几乎平滑,梯度很小,不利于权重更新;不同的是输出区间,tanh的输出区间是在(-1,1)之间,而且整个函数是以0为中心的,这个特点比sigmod的好。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数。不过这些也都不是一成不变的,具体使用什么激活函数,还是要根据具体的问题来具体分析,还是要靠调试的。
ReLU函数
ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmod函数和tanh函数,它有以下几个优点:
-
在输入为正数的时候,不存在梯度饱和问题。
-
计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
当然,缺点也是有的:
-
当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。
-
我们发现ReLU函数的输出要么是0,要么是正数,这也就是说,ReLU函数也不是以0为中心的函数。
ELU函数
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
PReLU函数
PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势吧。
我们看PReLU的公式,里面的参数α一般是取0~1之间的数,而且一般还是比较小的,如零点零几。当α=0.01时,我们叫PReLU为Leaky ReLU,算是PReLU的一种特殊情况吧。
4.回归分析
通过这段代码,我了解了不同的优化器的原理,参照https://www.cnblogs.com/YeZzz/p/13068953.html。
热爱学习,拒绝划水