Python实现Knn算法
关键词:KNN、K-近邻(KNN)算法、欧氏距离、曼哈顿距离
KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
KNN算法的思想总结:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
#coding:utf-8 import requests, json, time, re, os, sys, time import urllib2 import random import numpy as np #设置为utf-8模式 reload(sys) sys.setdefaultencoding( "utf-8" ) #读取文本文件,构建二维数组 def readDataFile(filename,format): if format: pass else: format = ',' list = [] #去除首位空格 filename = filename.strip() #判断数据文件是否存在 if os.path.isfile(filename): pass file_object = open(filename,'rb') lines = file_object.readlines() for line in lines: tmp = [] line = line.strip() for value in line.split(format)[:-1]: tmp.append(float(value)) tmp.append(line.split(format)[-1]) list.append(tmp) else: print "%s is not exists " % (filename) return list #读取文本数据,拆分原始数据为特征和标签,返回特征值和标签值 def createData(filename,format=','): data_label = readDataFile(filename,format) if len(data_label) > 0: label = [] data = [] #data_label = [[1,100,123,'A'],[2,99,123,'A'],[100,1,12,'B'],[99,2,23,'B']] for each in data_label: label.append(each[-1]) data.append(each[:-1]) return data,label #根据输入数据和测试数据,进行分类 def calculateDistance(input,data,label,k): classes = 'Error' if len(data[0])==0 or len(label) == 0: print 'data or label is null' pass elif k > len(data) : print "k : %s is out of bounds" % (k) pass elif len(input) <> len(data[0]): print "特征变量值不够,输入变量特征个数为:%s,训练特征变量个数为:%s" % (len(input),len(data[0])) pass else: result = [] length = len(input) for i in range(len(data)): sum = 0 for j in range(length): #pow(5,2) 标识5的平方为25,取两点之间的距离的平方并累加 sum = sum + pow(input[j] - data[i][j],2) #取平方根 sum = pow(sum,0.5) result.append(sum) #print result result = np.array(result) #argsort()根据元素的值从小到大对元素进行排序,返回下标 sortedDistIndex = np.argsort(result) #统计前k个数中各个标签的个数 classCount={} for i in range(k): voteLabel = label[sortedDistIndex[i]] ###对选取的K个样本所属的类别个数进行统计 #dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回默认值None。 classCount[voteLabel] = classCount.get(voteLabel,0) + 1 ###选取出现的类别次数最多的类别 maxCount = 0 for key,value in classCount.items(): if value > maxCount: maxCount = value classes = key return classes filename = '/home/shutong/jim/crawl/data.csv' data,label = createData(filename) input = [1,20] k = 4 result = calculateDistance(input,data,label,k) print input,result
其中测试数据如图:
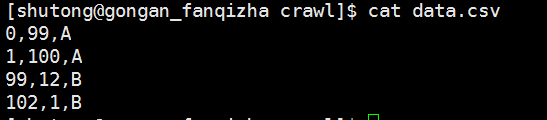
输入数据为:input = [1,20],预测它的标签为A还是B?
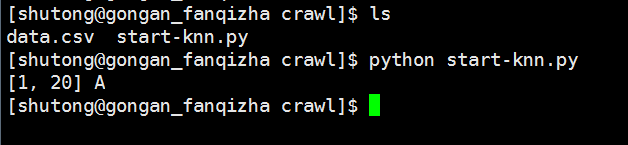
最终预测结果为:A