【Broker端进行消息过滤】
在Broker端进行消息过滤,可以减少无效消息发送到Consumer,少占用网络宽带从而提高吞吐量。
【过滤方式1——通过Tag过滤】
[ 关于Tag和Key ]
对一个应用来说,尽可能只用一个Topic,不同消息子类型用Tag来标识,每条消息只能有一个Tag,服务端基于Tag进行过滤,并不需要读取消息体的内容,效率较高。Producer发送消息设置了Tag以后,Consumer在订阅消息时,才会利用Tag在Broker端做消息过滤。
消息的Key,发送的消息设置好Key,以后可以根据这个Key来查询消息,这个Key一般用消息在业务层面的唯一标识码识别,这样后续查询消息异常、消息丢失等都很方便。Broker会创建专门的索引文件,来存储Key到消息的映射,由于Hash索引,应尽量使Key唯一,避免潜在的Hash冲突。
Tag和Key主要差别是试用场景不同,Tag用在Consumer的代码汇总,用来进行服务端消息过滤,Key主要用于通过命令行查询消息。
[ 通过Tag进行消息过滤 ]
Tag标签是一个普通字符串,在创建Message时添加,一个Message只能有一个Tag,使用Tag方式过滤非常高效,Broker端可以在ConsumerQueue中做这种过滤,只从CommitLog里读取过滤后被命中的消息。
Consumer的存储格式如下:
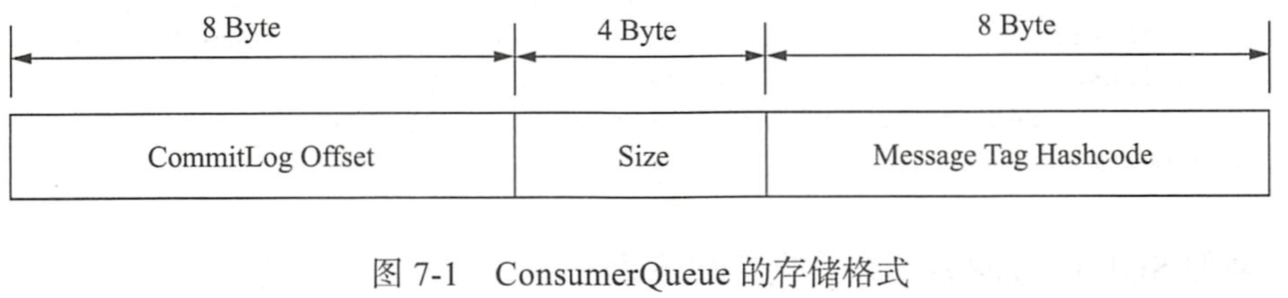
ConsumerQueue的第三部分存储的是Tag对应的HashCode,是一个定长的字符串通过Tag过滤的过程就是对比定长的Hashcode,经过hashcode对比,符合要求的消息从CommitLog中读取出来,不用担心Hash冲突问题,消息在被消费前,会对比完整的MessageTag字符串,消除Hash冲突造成的误读。
【过滤方式2——用SQL表达式的方式进行过滤】
Tag方式虽然高效,但是支持的逻辑比较简单。
在Producer端构造Message时,还可以通过putUserProperty方法来增加多个自定义的属性,基于这些属性可以做复杂的过滤逻辑。
[ 构建Message的代码 ]
String tag= "AAA"; Message message = new Message("TopicA",tag,"Hello RocketMQ ".getBytes(RemotingHelper.DEFAULT_CHARSET)); message.putUserProperty("a",String.valueOf(1)); message.putUserProperty("b","hello");
[ 消费端的代码 ]
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("GROUP_A"); //过滤属性a的值在0-3之间 consumer.subscribe("TopicA", MessageSelector.bySql("a between 0 and 3")); consumer.registerMessageListener(new MessageListenerConcurrently() { @Override public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) { return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; } }); consumer.start();
类似SQL表达式,支持如下语法:
1.数字对比:比如 >、>=、<、<=、BETWEEN、= 2.字符串对比:比如=、<>、IN 3.IS NULL 或 IS NOT NULL 4.逻辑符号 AND、OR、NOT
支持的数据类型:
1.数字型,比如123,456 2.字符型,比如 'abc',注意必须用单引号 3.NULL,这个特殊字符 4.布尔类型,TRUE或FALSE
SQL表达式的过滤需要Broker先读出消息里的属性内容,然后做SQL计算,增大磁盘压力,没有Tag方式高效。
【过滤方式3——Filter Server 方式过滤】
Filter Server方式是一种比SQL方式更灵活的过滤方式,允许用户自定义Java方法,根据Java方法的逻辑进行过滤。