中文乱码问题, 一直陪伴着我,时不时这里出现,那里出现!
这回的问题 跟记事本有关, Windows记事本, 你懂的, 酸爽的一比。
源文件的 是记事本创建的,当然,也是记事本保存的(公司有些同事 竟然喜欢记事本, 我无语凝噎) 我平时都是使用 notepadd++。 编码格式不同,导致的问题。网上也有很多人吐槽这个记事本。
如下:
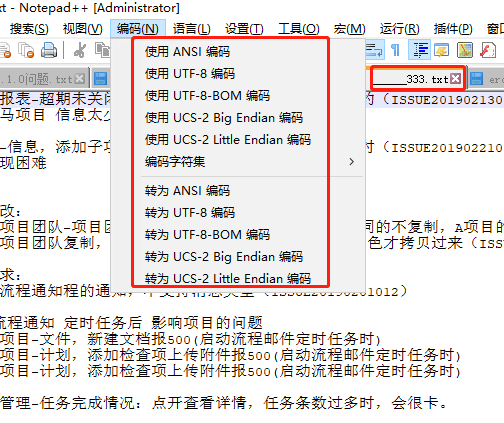
用notepadd++ 打开记事本创建的txt文件, 都是正常的, 也没有乱码,但是文件上传之后,默认以 UTF-8存储, 然后再次预览、下载下来查看 就出现问题了:

这样的文件 蛋疼。
怎么办呢? 其实很简单,需要进行编码探测,EncodingDetect 搞一下就好了! 仔细测试一下,发现还有问题, 发现, 编码问题似乎是好了,但是 内容长度有所减少,而且 后面出现了一个 奇怪的 乱码符合:
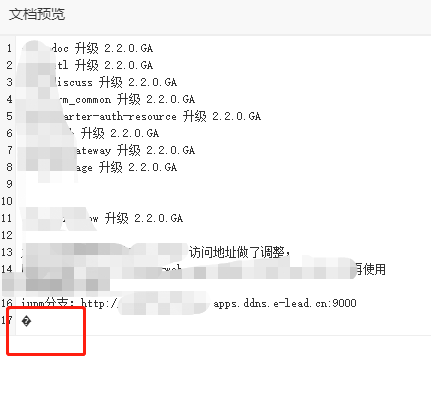
后面发现,注意到, 重新编码之后, 其长度也发生了变化,
String name = downloadFilename(request, filename); response.addHeader(HttpHeaders.CONTENT_DISPOSITION, "attachment;filename="" + name + """); if (contentLength != null) { response.addHeader(HttpHeaders.CONTENT_LENGTH, "" + contentLength); } if (StringUtils.isNotBlank(contentType)) { response.setContentType(contentType); } out = new BufferedOutputStream(response.getOutputStream()); out.write(buffer); out.flush();
上面的 contentLength 是bytes 的长度, 应该是重新编码后的 bytes 的长度 !!
终于好了!
不过, 另外 需要注意的是, 这个时候, 如果用浏览器的 控制台查看,发现是乱码,

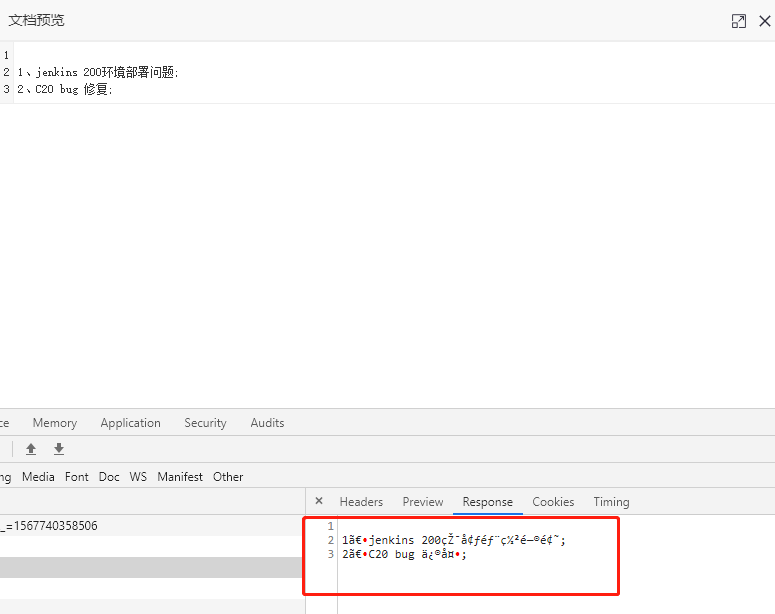
估计跟 响应头有关:
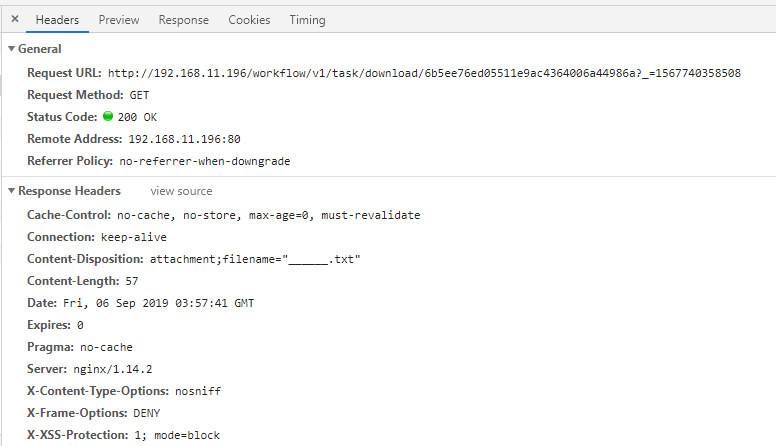
可以考虑设置 ContentType 或者 ;charset=
这个其实是不要紧的, 暂时 忽略即可。。