怎么办?进行Active Learning主动学习
Active Learning是最近又流行起来了的概念,是一种半监督学习方法。
一种典型的例子是:在没有太多数据的情况下,算法通过不断给出在决策边界上的样本,让打标者进行打标,使得算法明确分类边界,该算法结合On-Line的使用和灰度测试等方法,可以在有大量无标签数据和大量用户资源的时候,从无到有地创建良好的分类器。
如何进行主动学习
周志华的《机器学习》里介绍主动学习的时候提到,利用SVM进行主动学习的时候,应该先用少量有标签的样本训练一个基本的SVM分类器,然后给出无标签样本的时候,只考量到分类面的几何距离小于支持向量的点,因为只有这些点有可能变成新的支持向量从而进一步明确分类面,对于其他远离分界面的样本,可以把他们直接置为对应的标签。
周老师给出的例子略显粗糙,一种改进是:对于有松弛变量的分类器,可以把靠近支持向量的n个点都进行打标,这样有一些点会涉及松弛变量的也可以被覆盖。
进一步优化算法
很多情况下,上面的方法意味着还是需要大量的打标,那么解决这个问题的方法,就是更高效地打标,在原本范围内进行更高效的打标,即使是分类面内也不全部都打。
考虑SVM的分类面实际上上是一组参数,把数据转移到参数空间,一个分类面就是一个点,而一个样本就构成对参数空间的一个限制,一个分界面
即考虑两个空间:
特征空间F:样本以特征为坐标轴产生的空间,每一个点对应一个特征样本,对应参数空间中中的一个超平面(对参数空间的一种限制,也即是一种划分方式)
参数空间W:以SVM的各个参数作为轴产生的空间,每一个点对应一套参数,对应特征空间中的一个超平面(一个划分方式)
参数空间W:以SVM的各个参数作为轴产生的空间,每一个点对应一套参数,对应特征空间中的一个超平面(一个划分方式)
因此在参数空间中的特征限制下的空间称为可行域,未标记的数据会在这个可行域中留下分割,Active Learning就是这这个区域里寻找最有意义的分割并提出标注请求。
因此,因此分界面的可行域如图中中间的四边形,可以想象,SVM尝试找到一个到红色和绿色(支持向量)的半径最大的圆,这就是SVM的中心点
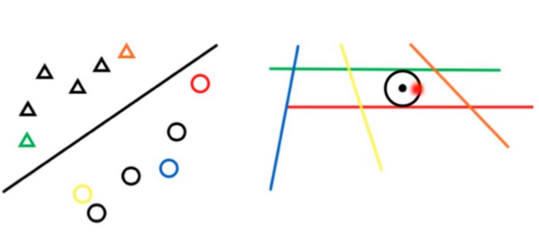
那么,把当出现了一个把可行域分割的样本的时候,在样本空间,这个样本肯定比两个支持向量更靠近分界面的:
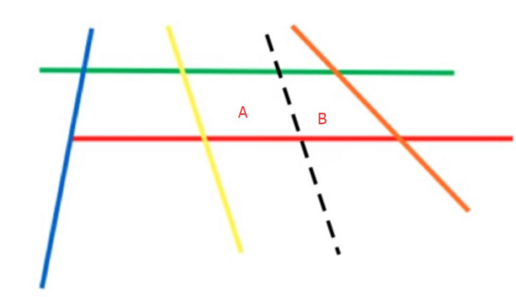
问题是,对于一个样本,到底应该选择A区还是B区呢?自然地,可以选择一个能画出半径最大的圆的区域。
当有好几个线经过可行域的时候,一种方法是只给最靠近原来的圆心的点进行打标,这样就可以最有效地分割可行域:
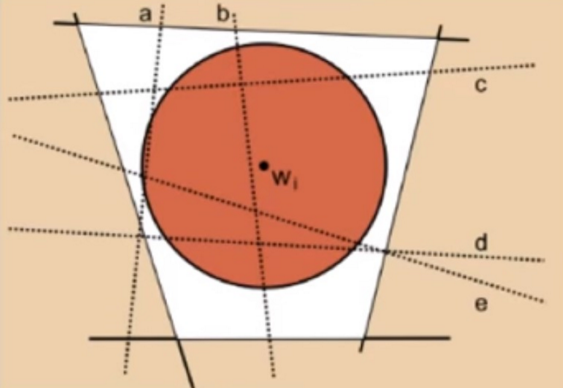
但是实际上,这样不一定能选到最好的圆心(分界面),上面这个图中大家每一次更新圆心都考虑最近的线看看,会陷入局部最优
所以实际上应该寻求这些割裂的白色区域里最大的那个,怎么选呢,这里有一种径向距离法:
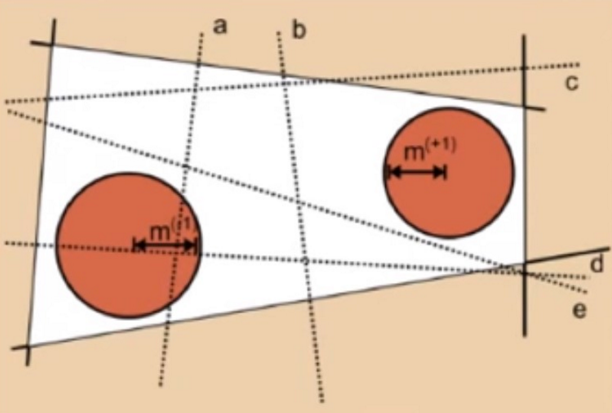
径向距离法就是:
在支持向量所夹的区域里面,对每一个样本,在其能够成最临近的(中间什么都没有)的那一个样本组合之间测量距离,取这样的组合里最大距离的样本,作为能获得最大内空间的径向划分,对这对样本进行标注
如何实现径向距离法
推荐在经典的LibSVM上修改实现,LibSVM的代码很好懂