前言:
互联网最初,数据仅仅只是单机的mysql就能满足需求,但随着互联网大数据时代的来临,并发量也上升了好几个量级,因此相关高并发的解决方案也随之诞生
一:垂直拆分
主从复制,读写分离思想
注意:无论是垂直拆分还是水平拆分,它仅仅是一种思想
解决方案:Memcached(缓存)+MySQL+垂直拆分
优化数据结构和索引-->文件缓存(I/O)-->Memcached
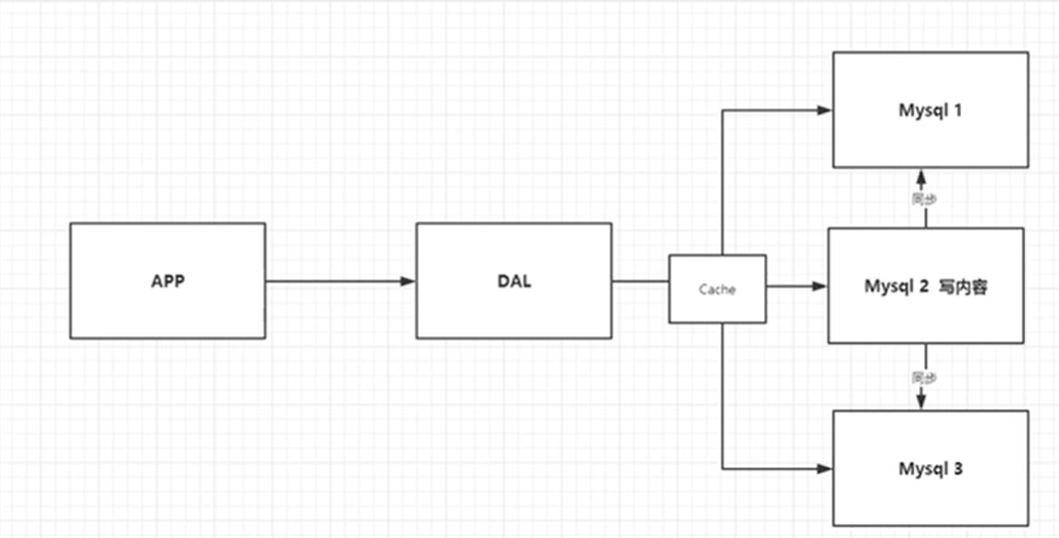

因为网站大多数情况下读操作是占比较大的一部分,所以缓存处理的解决方案非常的适合,因此诞生了读写分离+出从复制;这也是后续提高并发的基础
二,水平拆分
解决方案:分库分表+MySQL集群+水平拆分
解释:就是将原本一个表的数据分成多个,在客户访问时,访问信息也分成多个,去相应表中查,最后和成一个完整的信息返回个客户端
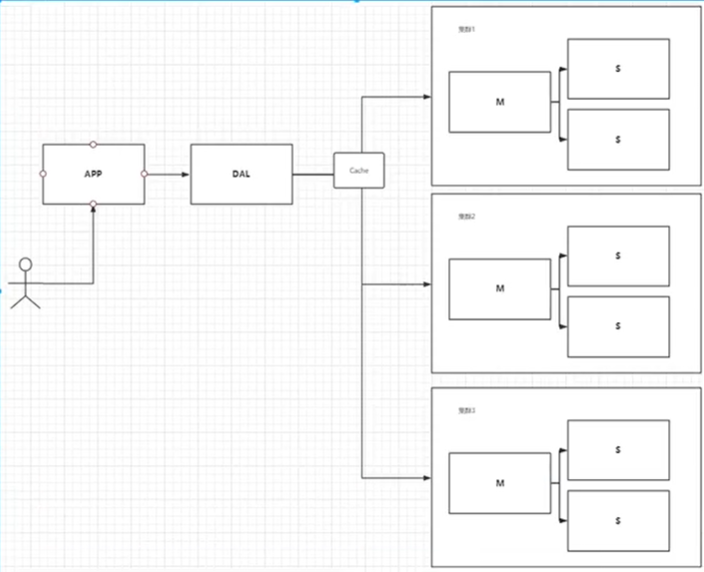
本质:提高并发量的本质就是对读写进行分析
拓展:行锁和表锁
答:当数据量庞大时:如果是表锁,用户搜索一条数据,数据库会把整个表锁上,知道查询出结果后,其他进程才能去访问当前表,而行锁就解决了此问题
这是MyISAM和Innodb的区别之一
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
三,当今时代
当今时代不仅仅集成的以前的解决方案思想,由于当前并发量十分的庞大,比如热点榜单,要满足实时的高并发的读写操作,此时关系型(ORM)数据库已经不能满足需求了
因此nosql被引进过来,它结构简单(kv键值对),所以能很好的配置orm数据库实现高并发的操作
四,拓展:NoAQL~not only SQL
NoSQL四大基本类型:
kv键值对:redis
列存储:HBase
图存储:Grap
文档:MongoDB
非关系型数据库,本质(解耦)
优点:
高扩展性(数据库直接没有关系,扩展方便)
读写能力强(高并发,一秒能写8万次,读取11万次,NoSQL)
数据类型是多样型的(不需要事先设计数据库,随去随用)
没有固定的查寻语言(最常用:get set)