
1.介绍
以前的方法都是编码为一个固定的长度,然后翻译,但是这样的话针对长句子就不友好,记忆不了那么长的句子。
与基本的编码器/解码器相比,此方法最重要的区别在于,它不会尝试将整个输入语句编码为单个固定长度的向量。
取而代之的是,它将输入的句子编码为一系列向量,并在解码翻译时自适应地选择这些向量的子集。
这使神经翻译模型不必将源句子的所有信息(无论其长度如何)压缩为固定长度的向量。 我们证明这可以使模型更好地应对较长的句子。
2.背景
从概率的角度,机器翻译相同当于给定源语言x/目标语言y配对的样本,求![]() 这个条件概率最大化,一旦翻译模型学习了条件分布,给定源句子,就可以通过搜索使条件概率最大化的句子来生成相应的翻译。
这个条件概率最大化,一旦翻译模型学习了条件分布,给定源句子,就可以通过搜索使条件概率最大化的句子来生成相应的翻译。
2.1 RNN编码-解码
首先会对输入序列x编码,t时刻的隐状态由t时刻的输入xt和t-1时刻的隐状态决定,![]()
源语言就会被编码为:
![]()
一个固定长度的矩阵吧,c由固定长度的隐向量组成,然后解码部分:
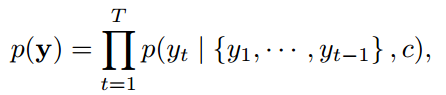
每一个word的生成都由之前的word和上下文环境c来预测,每一个条件概率被写为:
![]()
由之前的word,当前的隐状态,上下文共同决定。
2.2 学习对齐和翻译模型
在解码的部分定义每一个条件概率为:
![]()
yi由上一个单词、当前的隐状态、当前词i的上下文决定。
可以看到有所不同了,yi不是完全由固定的c决定的,而是由不同的针对每一个word的ci决定的。
![]()
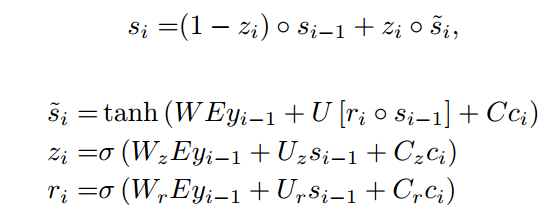
si由上一个时刻的隐状态、上一个单词、当前单词的上下文决定。其中Eyi-1是词yi-1的词向量,
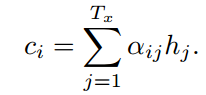
Let αij be a probability that the target word yi is aligned to, or translated from, a source word xj. Then, the i-th context vector Ci is the expected annotation over all the annotations with probabilities αij.
令αij为目标单词yi与源单词xj对齐或从源单词xj转换过来的概率。 然后,第i个上下文向量Ci是所有具有概率αij的注释上的期望注释。
αij就是权重系数,hj是针对源语言输入的编码隐状态,如下图所示,双向RNN,hj就是两个方向的隐状态的拼接,
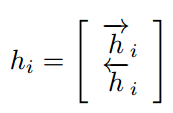

首先经过eij,然后softmax求出当前预测的wordi针对每一个输入j的权重attention值,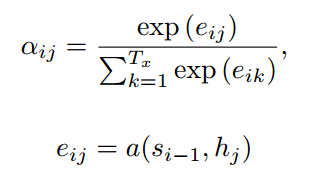
eij的计算就简单地使用了全连接层,但是输入的是i-1,为什么计算的结果下标是i了呢?![]()
也就是说当前wordi的上下文是由前一个word的隐状态和所有输入的源编码决定的。
最终yi的计算是这样来的:
我不怎么明白这个ti是什么意思?
3.什么是上下文context向量ci?
到底由哪些成分来组成?按照第二节,ci的计算是由si-1和hj来决定的,那为什么和si-1之前的无关呢?又为什么只用si-1呢?
原论文中有这么一句:
The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words。
然后,模型基于与这些源位置和所有先前生成的目标词关联的上下文向量来预测目标词。
也就是说这个模型就是使用前一个word关联的上下文来预测当前词,忽然明白,如果是没有这个软对齐的过程,那么就直接由上一个word和固定长度的向量来预测下一个单词,而有了软对齐之后,上一个word就可以有所重点的学习关键的单词来预测下一个单词,然后生成wordi,wordi的生成就是由wordi-1和其上下文关系来生成的。
翻译问题的关键是,如何根据我们有的上下文来预测下一个word。
4.翻译实例
https://zhuanlan.zhihu.com/p/31589962,这个讲的简直太好了,将抽象的公式映射到了具体的例子中。
ci计算得到的就是对应源语言中单词的权重,权重高就翻译这个单词来得到yi。
st-1不仅仅包含了t-1位置的word的信息,它包含:

5.物理含义
本文提出的是soft attention的思想,它的实际意思是什么呢?
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率.
因为在传统的机器翻译中,存在着专门的对齐的步骤:

是很依赖于对源语言和目标语言的语法分析的。