地址:彼岸图网
第一、同步爬取第一页的图片并进行存储
代码分析:缺点:请求和数据持久化全部都是同步,耗费大量时间,如下:
仅仅只爬取了20张图片,就花费了35秒多时间,如果想实现分页爬取,不久gogo了。

 同步爬取第一页图片并存储
同步爬取第一页图片并存储第二、异步非阻塞方式爬取第一页的图片并进行存储
和同步相比是非常快的。引入新的第三方库:aiohttp
和Python3.4引入的一个标准库,直接内置了对异步IO的支持。asyncio模块提供了使用协程构建并发应用的工具。
此处就不做具体详解了。
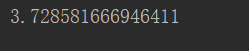

import aiohttp import requests from lxml import etree import time import asyncio headers = { 'User-Agent': "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36", } # 定义异步函数 async def get_img(img_name, img_detail_url): res = requests.get(img_detail_url, headers).text img_url = 'http://pic.netbian.com/' + etree.HTML(res).xpath('//div[@class="photo-pic"]/a/img/@src')[0] path = 'D:\imgs\netbian_async\' + img_name + img_url[-4::] # 异步发起请求,并保存数据 async with aiohttp.ClientSession() as session: async with await session.get(url=img_url, headers=headers) as response: img_data = await response.read() with open(path, "wb") as fp: fp.write(img_data) print(f"{img_name}, 下载成功!!!") if __name__ == "__main__": # 1.发起请求 url = 'http://pic.netbian.com/4kdongman/' response = requests.get(url, headers=headers) response.encoding = 'gbk' html = etree.HTML(response.text) img_li = html.xpath('//ul[@class="clearfix"]/li') start_time = time.time() async_list = [] for li in img_li: img_name = li.xpath('./a/b/text()')[0] img_detail_url = 'http://pic.netbian.com' + li.xpath('./a/@href')[0] print(img_name + "--" + img_detail_url) # 异步对象放入列表 async_list.append(get_img(img_name, img_detail_url)) asyncio.run(asyncio.wait(async_list)) end_time = time.time() print(end_time-start_time)
第三、异步非阻塞方式分页爬取图片并进行存储
后面补充