- flink 关联 hbase 表非主键
关联 Hbase 表非主键的功能,是我们一直都在做的事情,只是实现的方式不同。
在 Flink 1.10 版本的时候,SQL 关联 Hbase,都是在 SqlSubmit 程序启动的时候,基于配置文件生成 UDF 并注册成临时函数,直到 Flink 官方的 Hbase connector 支持 Lookup join,使用 lookup join 替换 udf 关联 hbase 表主键的部分。
udf 相对于 connector 还是有比较大的差距,udf 的输入输出都要基于配置文件,并且生成的 udf 只能查询固定的表的指定字段,条件也是提前确定好的,虽然也可以用,但是相对于 connector 灵活性上还是有很大的差距。
特别是这段时间,有个项目需要关联hbase 表的场景多,如果使用 udf 需要在启动的时候生成很多 udf,虽然对任务没什么影响,但是看着就很傻,所以就有了自己实现 hbase 的 lookup join source。
最近花了一些时间,尝试了一下自定义 sql source、mysql Table source 和支持 lookup join 的source,并实现了支持 lookup join hbase 非主键的 table source。
Flink 1.10 hbase udf
Flink 1.10 官方在源码的里面提供了 hbase udf 的样例,我们用这种方法实现流和hbase 表的关联
HBaseConnectorITCase.java
// 配置信息和 hbase 表、列族、列 信息
private static Map<String, String> hbaseTableProperties() {
Map<String, String> properties = new HashMap<>();
properties.put(CONNECTOR_TYPE, CONNECTOR_TYPE_VALUE_HBASE);
properties.put(CONNECTOR_VERSION, CONNECTOR_VERSION_VALUE_143);
properties.put(CONNECTOR_PROPERTY_VERSION, "1");
properties.put(CONNECTOR_TABLE_NAME, TEST_TABLE_1);
// get zk quorum from "hbase-site.xml" in classpath
String hbaseZk = HBaseConfiguration.create().get(HConstants.ZOOKEEPER_QUORUM);
properties.put(CONNECTOR_ZK_QUORUM, hbaseZk);
// schema
String[] columnNames = {FAMILY1, ROWKEY, FAMILY2, FAMILY3};
TypeInformation<Row> f1 = Types.ROW_NAMED(new String[]{F1COL1}, Types.INT);
TypeInformation<Row> f2 = Types.ROW_NAMED(new String[]{F2COL1, F2COL2}, Types.STRING, Types.LONG);
TypeInformation<Row> f3 = Types.ROW_NAMED(new String[]{F3COL1, F3COL2, F3COL3}, Types.DOUBLE, Types.BOOLEAN, Types.STRING);
TypeInformation[] columnTypes = new TypeInformation[]{f1, Types.INT, f2, f3};
DescriptorProperties descriptorProperties = new DescriptorProperties(true);
TableSchema tableSchema = new TableSchema(columnNames, columnTypes);
descriptorProperties.putTableSchema(SCHEMA, tableSchema);
descriptorProperties.putProperties(properties);
return descriptorProperties.asMap();
}
// lateral 方式 join hhbase 表
@Test
public void testHBaseLookupFunction() throws Exception {
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment streamTableEnv = StreamTableEnvironment.create(streamEnv, streamSettings);
StreamITCase.clear();
// prepare a source table
DataStream<Row> ds = streamEnv.fromCollection(testData2).returns(testTypeInfo2);
Table in = streamTableEnv.fromDataStream(ds, "a, b, c");
streamTableEnv.registerTable("src", in);
Map<String, String> tableProperties = hbaseTableProperties();
TableSource source = TableFactoryService
.find(HBaseTableFactory.class, tableProperties)
.createTableSource(tableProperties);
streamTableEnv.registerFunction("hbaseLookup", ((HBaseTableSource) source).getLookupFunction(new String[]{ROWKEY}));
// perform a temporal table join query
String sqlQuery = "SELECT a,family1.col1, family3.col3 FROM src, LATERAL TABLE(hbaseLookup(a))";
Table result = streamTableEnv.sqlQuery(sqlQuery);
DataStream<Row> resultSet = streamTableEnv.toAppendStream(result, Row.class);
resultSet.addSink(new StreamITCase.StringSink<>());
streamEnv.execute();
List<String> expected = new ArrayList<>();
expected.add("1,10,Welt-1");
expected.add("2,20,Welt-2");
expected.add("3,30,Welt-3");
expected.add("3,30,Welt-3");
StreamITCase.compareWithList(expected);
}
Flink lookup join rowkey
join hbase 表主键的样例,之前已经有博客写过,也不再赘述: flink sql join hbase demo
这里简单介绍一下 HBaseRowDataLookupFunction 的实现
还是一样的三件套,通过 java spi api 注册工厂 HBase2DynamicTableFactory,工厂创建 HBaseDynamicTableSource, TableSource 创建 HBaseRowDataLookupFunction(同步,或:HBaseRowDataAsyncLookupFunction 异步)
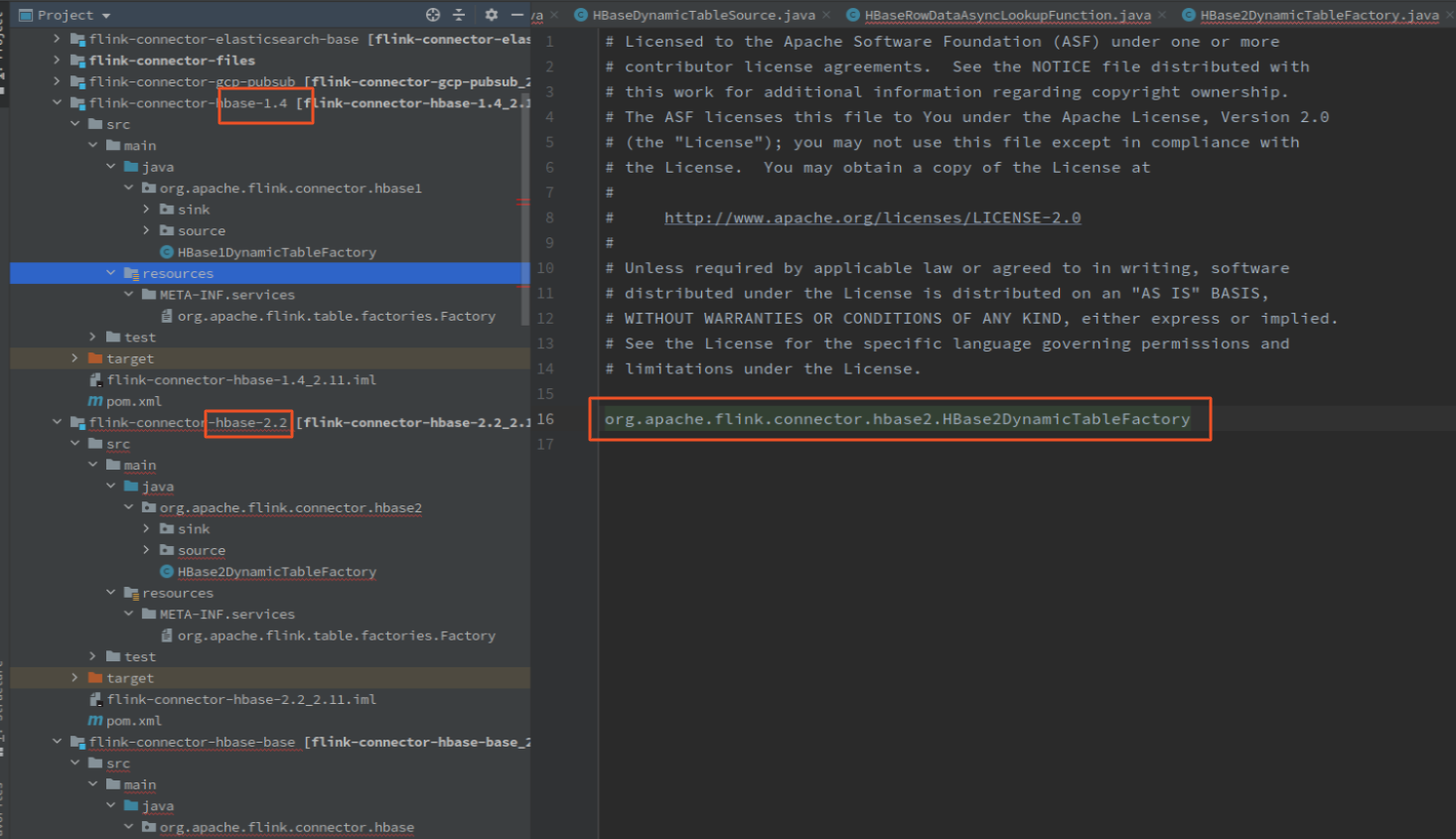
工厂和 TableSource 没什么好说的,直接看 HBaseRowDataLookupFunction
构造方法中传入需要的参数, open 方法初始化 缓存对象和hbase 连接
@Override
public void open(FunctionContext context) {
LOG.info("start open ...");
Configuration config = prepareRuntimeConfiguration();
try {
hConnection = ConnectionFactory.createConnection(config);
table = (HTable) hConnection.getTable(TableName.valueOf(hTableName));
this.cache =
cacheMaxSize <= 0 || cacheExpireMs <= 0
? null
: CacheBuilder.newBuilder()
.recordStats()
.expireAfterWrite(cacheExpireMs, TimeUnit.MILLISECONDS)
.maximumSize(cacheMaxSize)
.build();
if (cache != null) {
context.getMetricGroup()
.gauge("lookupCacheHitRate", (Gauge<Double>) () -> cache.stats().hitRate());
}
} catch (TableNotFoundException tnfe) {
LOG.error("Table '{}' not found ", hTableName, tnfe);
throw new RuntimeException("HBase table '" + hTableName + "' not found.", tnfe);
} catch (IOException ioe) {
LOG.error("Exception while creating connection to HBase.", ioe);
throw new RuntimeException("Cannot create connection to HBase.", ioe);
}
this.serde = new HBaseSerde(hbaseTableSchema, nullStringLiteral);
LOG.info("end open.");
}
lookup 的时候调用 eval 方法,执行 lookup 查询,官方提供的 hbase lookup source 只支持 hbase 的 rowkey 查询,所以 eval 方法输入的参数,就是 hbase 表对应的 rowkey,直接使用 rowkey 就可以做 hbase 查询。
方法中,先使用 rowkey 去缓存中找是否有缓存,存在就直接方法;如果缓存中不存在,再去 hbase 中查询结果,返回结果,并把结果放到缓存中。
/**
* The invoke entry point of lookup function.
*
* @param rowKey the lookup key. Currently only support single rowkey.
*/
public void eval(Object rowKey) throws IOException {
if (cache != null) {
RowData cacheRowData = cache.getIfPresent(rowKey);
if (cacheRowData != null) {
collect(cacheRowData);
return;
}
}
for (int retry = 0; retry <= maxRetryTimes; retry++) {
try {
// fetch result
Get get = serde.createGet(rowKey);
if (get != null) {
Result result = table.get(get);
if (!result.isEmpty()) {
if (cache != null) {
// parse and collect
RowData rowData = serde.convertToNewRow(result);
collect(rowData);
cache.put(rowKey, rowData);
} else {
collect(serde.convertToReusedRow(result));
}
}
}
break;
} catch (IOException e) {
LOG.error(String.format("HBase lookup error, retry times = %d", retry), e);
if (retry >= maxRetryTimes) {
throw new RuntimeException("Execution of HBase lookup failed.", e);
}
try {
Thread.sleep(1000 * retry);
} catch (InterruptedException e1) {
throw new RuntimeException(e1);
}
}
}
}
HBaseRowDataLookupFunction 的实现并不复杂,就是简单的创建 hbase 连接,用 get api 做主键查询,并设置需要查询的列。
flink lookup join hbase non rowkey
hbase 非主键的 lookup join 和 主键的查询基本上一样,只是在查询条件上有所差异。由于 hbase 的特性,主键固定为 rowkey,使用 get api 即可实现高性能的查询。非主键的查询,直接在主键的基础上,将唯一的主键替换一个或多个列,使用 scan api 配合 Filter 做查询,并设置需要查询的列。
比主键查询复杂的有以下两点:
- 主键可以用 get api 直接定位到结果,非主键只能用 scan api 配合 Filter 做全表扫描
- 主键查询只返回一条数据,非主键会返回一到多条数据
列选择
hbase 的主键查询是不需要指定查询列的,毕竟主键只有一个,非主键的查询则需要选择过滤器需要过滤的列。flink sql 中 表的 schema 的定义是在 sql 中定义的,所以需要在 sql 中定义 hbase 表的 schame(这部分和官方提供的一样),不一样的部分在 select 语句中。
hbase 主键查询 sql,需要使用时态表 join 来启动hbase 的 lookup 功能,用 build 表的指定字段 = rowkey 即可 :
SELECT a.user_id, a.item_id, a.category_id, a.behavior, concat('map_', c.cf.item_id), a.ts
FROM user_log a
left join hbase_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS c
ON a.user_id = rowkey
where a.behavior is not null;
非主键的查询正常来说,应该是这样的
create temporary table hbase_table_config(
rowkey string
,cf ROW(code string, `value` string, update_time string)
,cf2 ROW(code string, `value` string, update_time string)
)WITH(
'connector' = 'cust-hbase'
,'hbase.zookeeper.quorum' = 'thinkpad:12181'
,'zookeeper.znode.parent' = '/hbase'
,'hbase.tablename' = 'hbase_table_config'
,'hbase.null-string-literal' = 'null'
,'hbase.lookup.key' = 'cf:code,cf2:code'
,'hbase.lookup.cache.max.size' = '100'
,'hbase.lookup.cache.expire.ms' = '6'
,'hbase.lookup.max.retry.times' = '3'
,'hbase.timeout' = '10'
)
;
SELECT a.user_id, a.item_id, a.category_id, a.behavior, concat('map_', c.cf.item_id), a.ts
FROM user_log a
left join hbase_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS c
on a.user_id = c.cf.code and a.item_id = c.cf2.code
where a.behavior is not null;
但是 flink 的 sql 解析中,并不能识别 “c.cf.user_id” 这种字段,如果这样定义,在解析关联条件的时候,会解析不处理,并认为没有关联条件,报错:
Temporal table join requires an equality condition on fields of table [default_catalog.default_database.hbase_table_config].
解析 查询条件的源码 CommonPhysicalLookupJoin.allLookupKeys
val allLookupKeys: Map[Int, LookupKey] = {
// join key pairs from left input field index to temporal table field index
val joinKeyPairs: Array[IntPair] = getTemporalTableJoinKeyPairs(joinInfo, calcOnTemporalTable)
// all potential index keys, mapping from field index in table source to LookupKey
analyzeLookupKeys(
cluster.getRexBuilder,
joinKeyPairs,
calcOnTemporalTable)
}
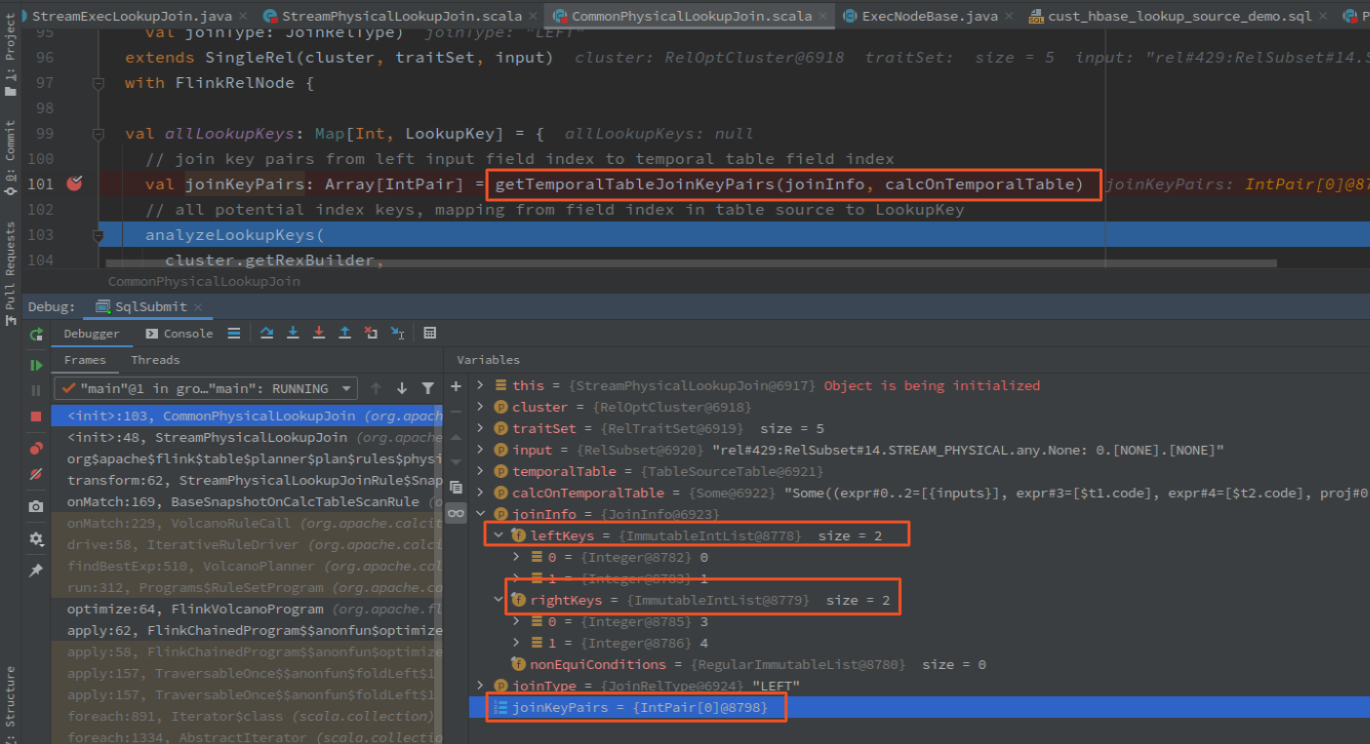
debug 进入具体解析的代码 CommonPhysicalLookupJoin.getIdenticalSourceField
private def getIdenticalSourceField(rexProgram: RexProgram, outputOrdinal: Int): Int = {
assert((outputOrdinal >= 0) && (outputOrdinal < rexProgram.getProjectList.size()))
val project = rexProgram.getProjectList.get(outputOrdinal)
var index = project.getIndex
while (true) {
var expr = rexProgram.getExprList.get(index)
expr match {
case call: RexCall if call.getOperator == SqlStdOperatorTable.IN_FENNEL =>
// drill through identity function
expr = call.getOperands.get(0)
case call: RexCall if call.getOperator == SqlStdOperatorTable.CAST =>
// drill through identity function
val outputType = call.getType
val inputType = call.getOperands.get(0).getType
val isCompatible = PlannerTypeUtils.isInteroperable(
FlinkTypeFactory.toLogicalType(outputType), FlinkTypeFactory.toLogicalType(inputType))
expr = if (isCompatible) call.getOperands.get(0) else expr
case _ =>
}
expr match {
case ref: RexLocalRef => index = ref.getIndex
case ref: RexInputRef => return ref.getIndex
case _ => return -1
}
}
-1
}
解析查询条件的时候,不能识别到 RexFieldAccess 这种复合类型,只能识别表达是或者通过 index 直接定位到字段
hbase 非主键,不能识别

hbase rowkey 主键,不需要解析
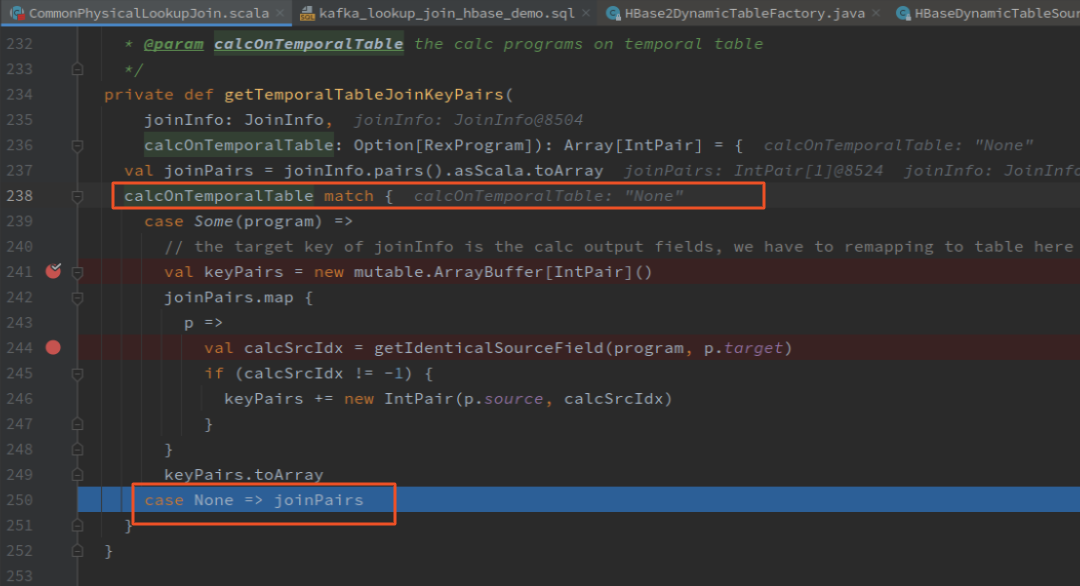
mysql 直接返回 RexInputRef 的 index
针对不能解析复合类型(c.cf.code)的关联条件的情况,绕了一下,在 hbase 表的定义中添加对应参数,确定需要做查询条件的列,在 select 语句中使用"拼接" 的方式,将查询条件对应的值传入。
hbase 表定义如下:
create temporary table hbase_table_config(
rowkey string
,cf ROW(code string, `value` string, update_time string)
,cf2 ROW(code string, `value` string, update_time string)
)WITH(
'connector' = 'cust-hbase'
,'hbase.zookeeper.quorum' = 'thinkpad:12181'
,'zookeeper.znode.parent' = '/hbase'
,'hbase.tablename' = 'hbase_table_config'
,'hbase.null-string-literal' = 'null'
,'hbase.lookup.key' = 'cf:code,cf2:code'
,'hbase.lookup.cache.max.size' = '100'
,'hbase.lookup.cache.expire.ms' = '6'
,'hbase.lookup.max.retry.times' = '3'
,'hbase.timeout' = '10'
)
查询语句,join 中 hbase 表侧的字段,只能写 rowkey(只能 join 用等值连接,hbase 表只能有一个简单字段,就是 rowkey)
SELECT a.user_id, a.item_id, a.category_id, a.behavior,c.rowkey, c.cf.`value`, c.cf2.`value`,a.ts
FROM user_log a
left join hbase_table_config FOR SYSTEM_TIME AS OF a.process_time AS c
-- 必须要一个key 做关联条件,实际上不会用这个做关联
-- lookup join may hive multiple join condition
-- 流输入端的字段使用 ',' 拼接的方式传入参数
-- hbase 端通过参数 'hbase.lookup.key' = 'cf:code,cf2:code' 传入过滤的字段,两边必须的数量必须匹配
ON concat(a.user_id,',',a.item_id) = c.rowkey --and a.item_id = c.cf.`code`
-- on a.user_id = c.cf.code and a.item_id = c.cf2.code
where a.behavior is not null;
这样查询的列和对应的值都通过 SQL 传入到了 flink 中,下面来看看 自定义 hbase lookup Source (非主键)的具体实现
自定义 hbase lookup Source (非主键)
如其他 TableSource,hbase lookup source 也包含 TableFactory、TableSource和SourceFunction,再加一个 HbaseOption 定义配置参数
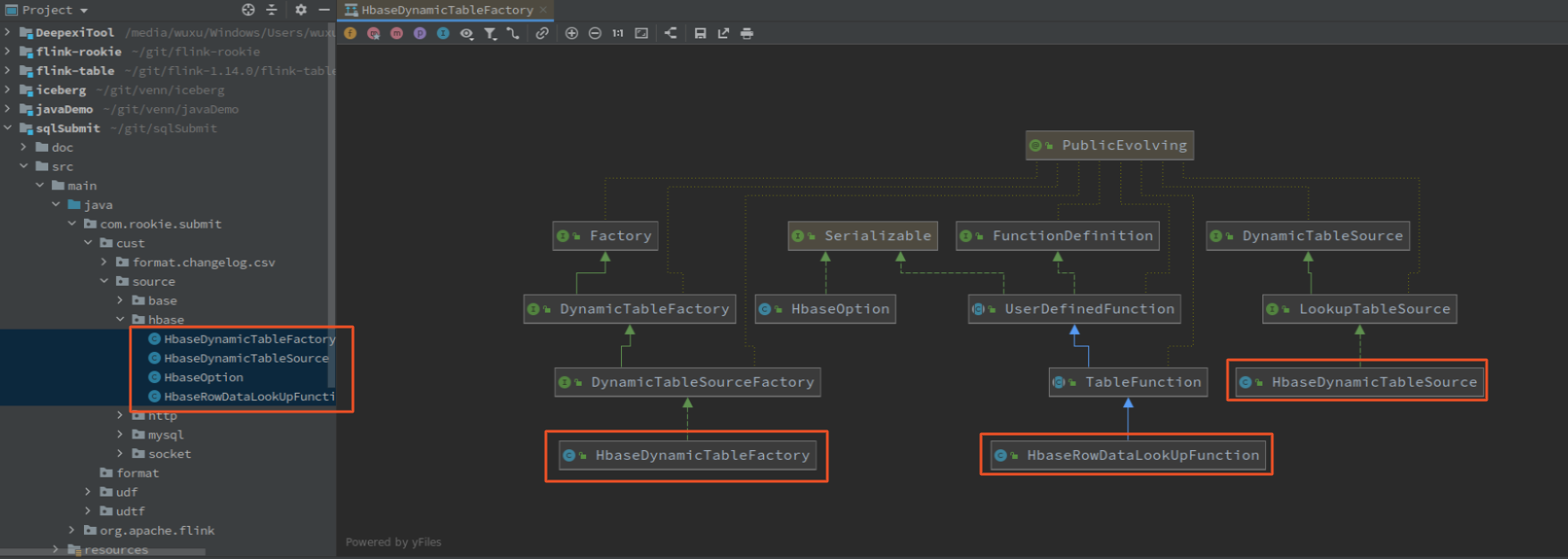
HbaseDynamicTableFactory
HbaseDynamicTableFactory 中定义 connector 标识: cust-hbase,定义必填、选填参数,从执行上下文获取参数/TableSchema,创建 HbaseDynamicTableSource
public class HbaseDynamicTableFactory implements DynamicTableSourceFactory {
@Override
// connector 标识
public String factoryIdentifier() {
// used for matching to `connector = '...'`
return "cust-hbase";
}
@Override
// 必填参数
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(HbaseOption.ZOOKEEPER_QUORUM);
options.add(HbaseOption.ZOOKEEPER_ZNODE_PARENT);
options.add(HbaseOption.NULL_STRING_LITERAL);
options.add(HbaseOption.TABLE);
options.add(HbaseOption.LOOKUP_KEY);
// options.add(FactoryUtil.FORMAT); // use pre-defined option for format
return options;
}
@Override
// 选填参数
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
// no optional option
options.add(HbaseOption.CACHE_MAX_SIZE);
options.add(HbaseOption.CACHE_EXPIRE_MS);
options.add(HbaseOption.MAX_RETRY_TIMES);
options.add(HbaseOption.TIME_OUT);
return options;
}
@Override
// 从执行上下文获取参数, 创建 HbaseDynamicTableSource
public DynamicTableSource createDynamicTableSource(Context context) {
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// validate all options
helper.validate();
// get the validated options
final ReadableConfig config = helper.getOptions();
HbaseOption option = new HbaseOption.Builder()
.setZookeeperQuorum(config.get(HbaseOption.ZOOKEEPER_QUORUM))
.setZookeeperZnodeParent(config.get(HbaseOption.ZOOKEEPER_ZNODE_PARENT))
.setNullStringLiteral(config.get(HbaseOption.NULL_STRING_LITERAL))
.setTable(config.get(HbaseOption.TABLE))
.setLookupKey(config.get(HbaseOption.LOOKUP_KEY))
.setCacheMaxSize(config.get(HbaseOption.CACHE_MAX_SIZE))
.setCacheExpireMs(config.get(HbaseOption.CACHE_EXPIRE_MS))
.setMaxRetryTimes(config.get(HbaseOption.MAX_RETRY_TIMES))
.setTimeOut(config.get(HbaseOption.TIME_OUT))
.build();
// derive the produced data type (excluding computed columns) from the catalog table
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
TableSchema physicalSchema =
TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
// create and return dynamic table source
return new HbaseDynamicTableSource(producedDataType, option, physicalSchema);
}
}
HbaseDynamicTableSource
犹豫这里只实现了 HbaseRowDataLookUpFunction,所以 HbaseDynamicTableSource 没有什么内容
HbaseRowDataLookUpFunction
HbaseRowDataLookUpFunction 是 LookUpFunction 的具体实现
构造方法
先从 配置中解析出了需要作为过滤的列,再从定义的 hbase 表 schame 中解析出需要返回的列族、列
public HbaseRowDataLookUpFunction(HBaseTableSchema hbaseSchema, HbaseOption options) throws UnsupportedEncodingException {
this.hbaseSchema = hbaseSchema;
this.cacheMaxSize = options.getCacheMaxSize();
this.cacheExpireMs = options.getCacheExpireMs();
this.maxRetryTimes = options.getMaxRetryTimes();
this.options = options;
// format lookup filter column
String lookupKeyConfig = options.getLookupKey();
lookupKey = new LinkedHashMap<>();
for (String key : lookupKeyConfig.split(",")) {
String[] tmp = key.split(":");
byte[] family = tmp[0].getBytes("UTF-8");
byte[] qualify = tmp[1].getBytes("UTF-8");
if (lookupKey.containsKey(family)) {
lookupKey.get(family).add(qualify);
} else {
List<byte[]> list = new ArrayList<>();
list.add(qualify);
lookupKey.put(family, list);
}
}
// format result qualifier
resultColumn = new LinkedHashMap<>();
for (String familyString : hbaseSchema.getFamilyNames()) {
byte[] family = familyString.getBytes("UTF-8");
byte[][] qualifies = hbaseSchema.getQualifierKeys(familyString);
for (byte[] by : qualifies) {
if (resultColumn.containsKey(family)) {
resultColumn.get(family).add(by);
} else {
List<byte[]> list = new ArrayList<>();
list.add(by);
resultColumn.put(family, list);
}
}
}
LOG.info("open end");
}
Open 方法
Open 方法中建了了Hbase 连接和创建了缓存对象
evil 方法
evil 方法是核心的数据处理方法
1、用组合的值 input 生产 RowData,从缓存中查询数据,存在就返回,这里需要注意的,缓存是 Cache<RowData, List
RowData keyRow = GenericRowData.of(input);
if (cache != null) {
List<RowData> cachedRows = cache.getIfPresent(keyRow);
if (cachedRows != null) {
for (RowData cachedRow : cachedRows) {
collect(cachedRow);
}
return;
}
}
2、查询 hbase
- 先用 lookupKey 创建列值过滤器(SingleColumnValueFilter ),添加到 scan 中,如果输入参数的数量和lookupKey的
int i = 0;
// add SingleColumnValueFilter
for (Map.Entry<byte[], List<byte[]>> entry : lookupKey.entrySet()) {
byte[] family = entry.getKey();
for (byte[] qualifier : entry.getValue()) {
Filter filter = new SingleColumnValueFilter(family, qualifier, CompareOperator.EQUAL, keys[i].getBytes("UTF8"));
scan.setFilter(filter);
// Avoid can't get all condition column in keys
// if have two filter column, but only get one key, just use first column as filter
if (i == keys.length - 1) {
break;
}
++i;
}
}
- scan 添加返回的列
// add result column
for (Map.Entry<byte[], List<byte[]>> entry : resultColumn.entrySet()) {
byte[] family = entry.getKey();
for (byte[] qualifier : entry.getValue()) {
scan.addColumn(family, qualifier);
}
}
- 查询和返回结果
// scan&parse result
try (ResultScanner resultSet = table.getScanner(scan)) {
Result result;
if (cache == null) {
while ((result = resultSet.next()) != null) {
// parse to RowData
RowData row = serde.convertToNewRow(result);
collect(row);
}
} else {
ArrayList<RowData> rows = new ArrayList<>();
while ((result = resultSet.next()) != null) {
// parse to RowData
RowData row = serde.convertToNewRow(result);
rows.add(row);
collect(row);
}
rows.trimToSize();
cache.put(keyRow, rows);
}
}
测试
自定义 hbase 表
为了更有代表性,这里定义了2个列族做测试
create temporary table hbase_table_config(
rowkey string
,cf ROW(code string, `value` string, update_time string)
,cf2 ROW(code string, `value` string, update_time string)
)WITH(
'connector' = 'cust-hbase'
,'hbase.zookeeper.quorum' = 'thinkpad:12181'
,'zookeeper.znode.parent' = '/hbase'
,'hbase.tablename' = 'hbase_table_config'
,'hbase.null-string-literal' = 'null'
,'hbase.lookup.key' = 'cf:code,cf2:code'
,'hbase.lookup.cache.max.size' = '100'
,'hbase.lookup.cache.expire.ms' = '6'
,'hbase.lookup.max.retry.times' = '3'
,'hbase.timeout' = '10'
)
hbase 表数据
put 'hbase_table_config','1','cf:code','code_cf'
put 'hbase_table_config','1','cf:value','value_cf_1'
put 'hbase_table_config','1','cf:update_time','1'
put 'hbase_table_config','1','cf2:code','code_cf2_1'
put 'hbase_table_config','1','cf2:value','value_cf2_1'
put 'hbase_table_config','1','cf2:update_time','1'
put 'hbase_table_config','2','cf:code','code_cf'
put 'hbase_table_config','2','cf:value','value_cf_2'
put 'hbase_table_config','2','cf:update_time','2'
put 'hbase_table_config','2','cf2:code','code_cf2_2'
put 'hbase_table_config','2','cf2:value','value_cf2_2'
put 'hbase_table_config','2','cf2:update_time','2'
场景1 关联一个列
SQL:
create temporary table hbase_table_config(
rowkey string
,cf ROW(code string, `value` string, update_time string)
,cf2 ROW(code string, `value` string, update_time string)
)WITH(
'connector' = 'cust-hbase'
,'hbase.zookeeper.quorum' = 'thinkpad:12181'
,'zookeeper.znode.parent' = '/hbase'
,'hbase.tablename' = 'hbase_table_config'
,'hbase.null-string-literal' = 'null'
,'hbase.lookup.key' = 'cf:code'
-- ,'hbase.lookup.key' = 'cf:code,cf2:code'
,'hbase.lookup.cache.max.size' = '100'
,'hbase.lookup.cache.expire.ms' = '6'
,'hbase.lookup.max.retry.times' = '3'
,'hbase.timeout' = '10'
)
INSERT INTO kakfa_join_mysql_demo(user_id, item_id, category_id, behavior,rowkey, behavior_map, behavior_map2, ts)
SELECT a.user_id, a.item_id, a.category_id, a.behavior,c.rowkey, c.cf.`value`, c.cf2.`value`,a.ts
FROM user_log a
left join hbase_table_config FOR SYSTEM_TIME AS OF a.process_time AS c
-- 参数顺序和配置顺序一匹配,即: a.behavior = c.cf2.code
ON a.behavior = c.rowkey
where a.behavior is not null;
输入一条数据
{"category_id":"category_id_1","user_id":"user_id_3","item_id":"abc","behavior":"code_cf","ts":"2021-11-16 15:01:41.327"}
返回数据
+I[user_id_3, abc, category_id_1, code_cf, 1, value_cf_1, value_cf2_1, 2021-11-16T15:01:41.327]
+I[user_id_3, abc, category_id_1, code_cf, 2, value_cf_2, value_cf2_2, 2021-11-16T15:01:41.327]

场景2 关联不同列族的两个列
SQL:
create temporary table hbase_table_config(
rowkey string
,cf ROW(code string, `value` string, update_time string)
,cf2 ROW(code string, `value` string, update_time string)
)WITH(
'connector' = 'cust-hbase'
,'hbase.zookeeper.quorum' = 'thinkpad:12181'
,'zookeeper.znode.parent' = '/hbase'
,'hbase.tablename' = 'hbase_table_config'
,'hbase.null-string-literal' = 'null'
,'hbase.lookup.key' = 'cf:code,cf2:code'
,'hbase.lookup.cache.max.size' = '100'
,'hbase.lookup.cache.expire.ms' = '6'
,'hbase.lookup.max.retry.times' = '3'
,'hbase.timeout' = '10'
)
INSERT INTO kakfa_join_mysql_demo(user_id, item_id, category_id, behavior,rowkey, behavior_map, behavior_map2, ts)
SELECT a.user_id, a.item_id, a.category_id, a.behavior,c.rowkey, c.cf.`value`, c.cf2.`value`,a.ts
FROM user_log a
left join hbase_table_config FOR SYSTEM_TIME AS OF a.process_time AS c
-- 参数顺序和配置顺序一匹配,即: a.category_id = c.cf.code and a.behavior = c.cf2.code
ON concat(a.behavior,',',a.category_id) = c.rowkey
where a.behavior is not null;
输入一条数据
{"category_id":"code_cf2_2","user_id":"user_id_3","item_id":"abc","behavior":"code_cf","ts":"2021-11-16 15:01:41.327"}
返回数据
+I[user_id_3, abc, code_cf2_2, code_cf, 2, value_cf_2, value_cf2_2, 2021-11-16T15:01:41.327]

欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
