join和join fetch是两回事,不要搞混! join取自SQL的join概念。被join的对象一般会出现在select,where等其他子句中。因为join的目的在于要对被join的对象做处理,比如过滤等等。
fetch则是抓取策略!它的作用就是指明root entity的哪些关联对象会在load这个entity时一同被load出来!因此,fetch的对象一般是没有别名的(如果需要进一步抓取集合单个元素的关联对象时就必须使用别名了),因为它不会以查询结果直接返回,也不会在where子句对它们进行过滤,它们是通过返回的root entity导航得到!
fetch 也不应该与 setMaxResults() 或 setFirstResult() 共用,这是因为这些操作是基于结果集的,而在预先抓取集合类时可能包含重复的数据,也就是说无法预先知道精确的行数。
fetch 还不能与独立的 with 条件一起使用。通过在一次查询中 fetch 多个集合,可以制造出笛卡尔积,因此请多加注意。
对 bag 映射来说,同时 join fetch 多个集合角色可能在某些情况下给出并非预期的结果,也请小心。最后注意,使用 full join fetch 与 right join fetch 是没有意义的。
超大集合不能一次性加载!它们的配制应该是:lazy必须为true! 动态抓取进也不应该抓取它!目前来看,只能提供额外的接口来分批获取集合。比如Forum.getThreads(int firstThreadIndex, int threadCount)
关于join与fetch的两个例子
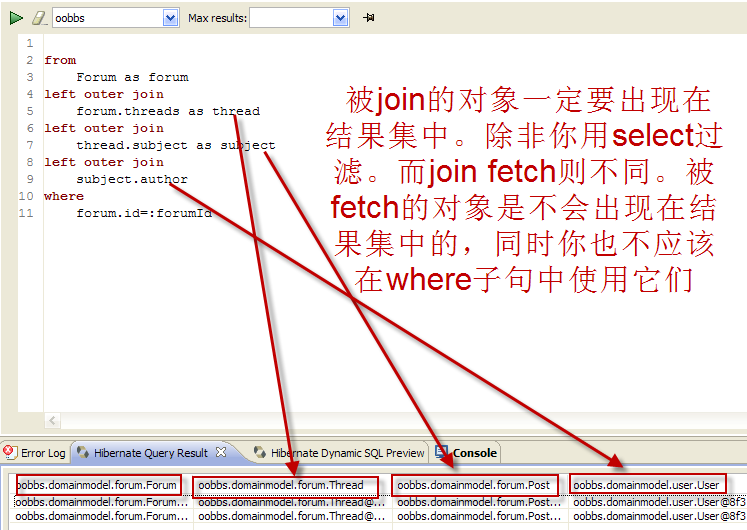

如果想过滤join和fetch中的重复对象,有两种方法:
1.将续集里封装成set.比如:Set noDupes = new LinkedHashSet(resultList))
2.使用DISTINCT。比如:select distinct i from Item i join fetch i.bids