递归
假设你在祖母的阁楼中发现一个上锁的神秘手提箱。

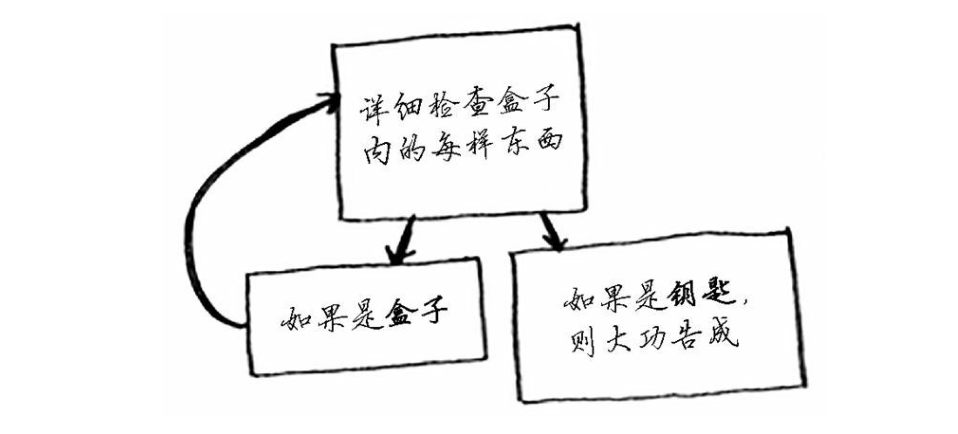
祖母告诉你,钥匙可能在下面这个盒子中。

这个盒子里有盒子,而盒子里的盒子又有盒子。钥匙就在某个盒子中。
为找到钥匙,你将使用什么算法?先想想这个问题,再接着往下看。
第一种方法使用的是while循环:只要
盒子堆不空,就从中取一个盒子,并在其中仔细查找。
def look_for_key(main_box):
pile = main_box.make_a_pile_to_look_through()
while pile is not empty:
box = pile.grab_a_box()
for item in box:
if item.is_a_box():
pile.append(item)
elif item.is_a_key():
print "found the key!"
第二种方法使用递归——函数调用自己,这种方法的伪代码如下。
def look_for_key(box):
for item in box:
if item.is_a_box():
这两种方法的作用相同,但在我看来,第二种方法更清晰。递归只是让
解决方案更清晰,并没有性能上的优势。实际上,在有些情况下,使用
循环的性能更好。我很喜欢Leigh Caldwell在Stack Overflow上说的一句
话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能
更容易理解。如何选择要看什么对你来说更重要。
基线条件和递归条件
由于递归函数调用自己,因此编写这样的函数时很容易出错,进而导致
无限循环。例如,假设你要编写一个像下面这样倒计时的函数。
> 3 ... 2 ... 1
为此,你可以用递归的方式编写,如下所示:
def countdown(i):
print i
countdown(i-1)
如果你运行上述代码,将发现一个问题:这个函数运行起来没完没了!
3...2...1...0...-1...-2...等等
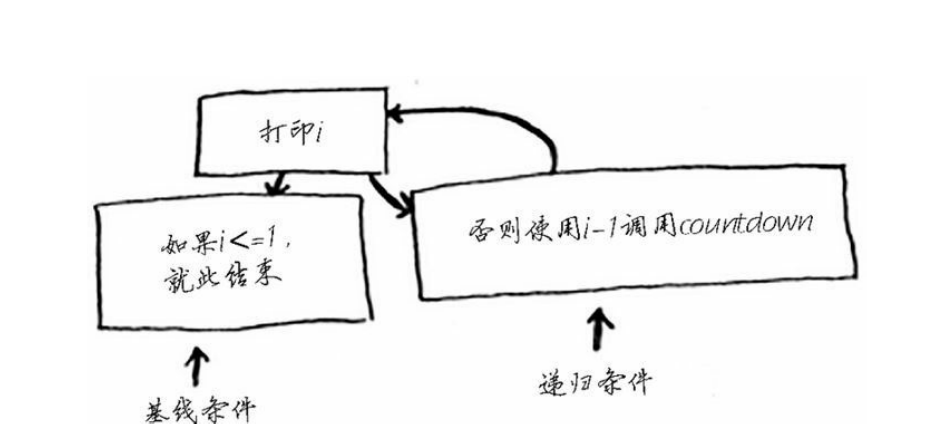
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函
数都有两部分:基线条件(base case)和递归条件(recursive case)。
递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自
己,从而避免形成无限循环。
我们来给函数countdown添加基线条件。
def countdown(i):
print i
if i <= 1: ←------基线条件
return
else: ←------递归条件
countdown(i-1)
现在,这个函数将像预期的那样运行,如下所示。