HBase 分布式数据库 允许几千台服务器去存储海量文件::
HBase 的底层技术:文件存储系统:HDFS 海量数据处理:Hadoop MapReduce 协同管理服务:Zookeeper
HBase
数据模型:把每个存储的值都存储为未经解释的字符串
数据操作:都存在一张表里
基于列存储
只支持对行键的简单索引
会保留旧的版本
借助于整个分布式集群
数据仓库产品Hive去访问底层HBase当中的数据---HiveSQL
HBase行键 列族 列限定符 时间戳 通过这四个元素去定位一个具体的数据
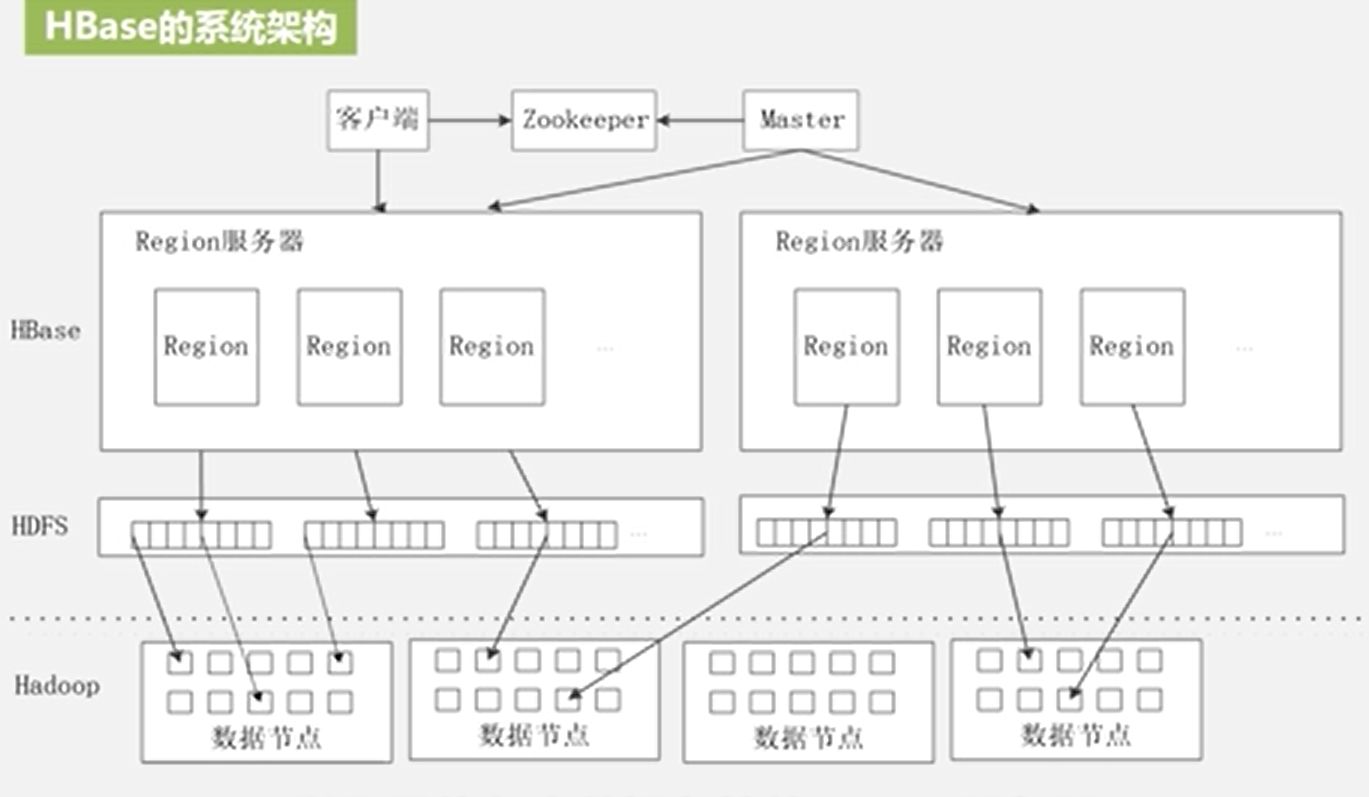
HBase的功能组件 :库函数 (一般用于链接每个客户端)
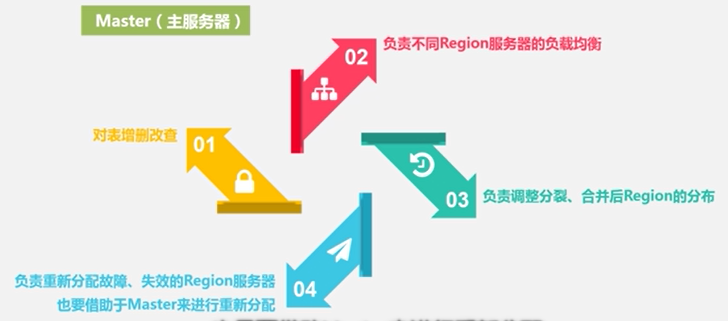
Master服务器 :充当管家的作用
Region服务器:负责存储不同的Region

客户端访问数据时的“三级寻址”首先访问ZooKeeper服务器,ZooKeeper文件记录了-ROOT-表地址
,取出ROOT表地址,然后获得相应的.META.表 ,然后再从META表当中定位用户数据表Region的位置信息,最终到达region服务器,把数据取出来,就是这样一个三级寻址过程,而且为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题(采用惰性解决机制,每次不去管它是否失效,反正只要缓存一次,后面访问一直用这次缓存,直到用这些缓存查找数据发现无法找到这时才会再次经历三级寻址过程,再把最新的Region id 这个位置缓存下来)。
HBase当中的数据是借助于Hadoop的HDFS去完成数据存储的
HDFS是架构在底层的Hadoop集群之上
Region服务器具体负责数据存储和管理 Region就是具体用户数据
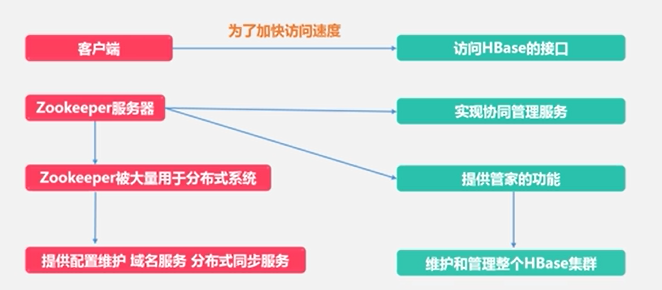
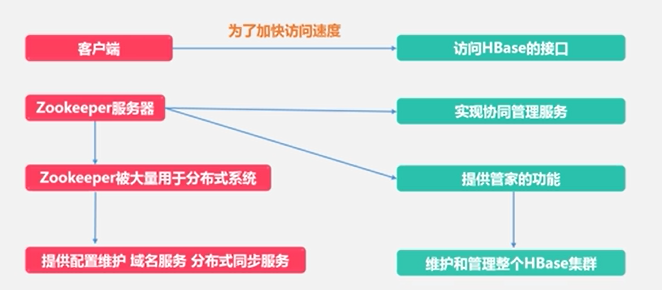 Zookeeper
Zookeeper
Master
实例:创建一个表,表名称为tempTable,包含3个列族f1,f2和f3
create 'tempTable' , 'f1','f2','f3'
list命令:列出HBase中所有的表信息
一次只能为一个表的一行数据里的一个列添加数据
put 'tempTable' , 'r1', 'f1:c1','hello ,dblab' 列族下面的c1列添加数据
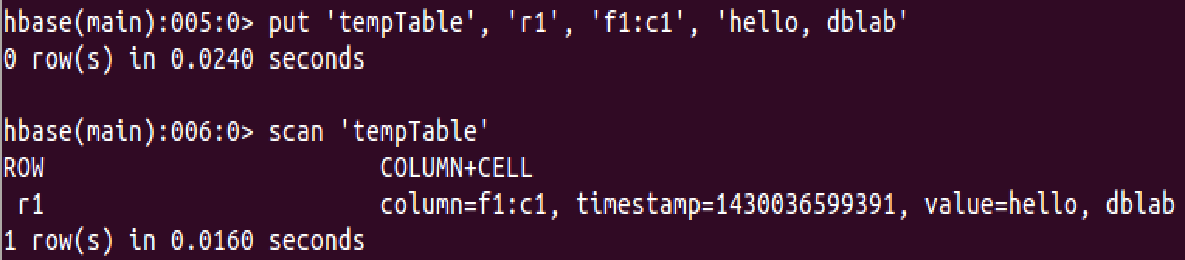
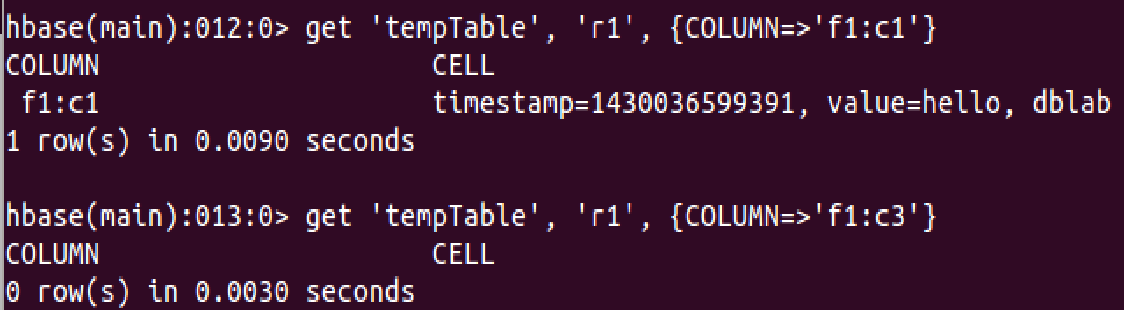
get:通过表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值
如果你想去删除一个表,必须要先让这个表失效,disable 'tempTable'使整个表失效
然后再执行drop ‘tempTable’删除表