又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。
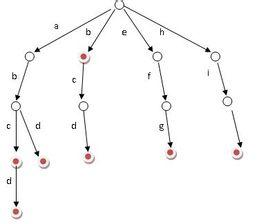
可见根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
用途:
1.就是用来查找单词的。
比如有一堆单词,给定一个单词要求判断是否出现过。
显然可以使用map或set什么的,但是对于多组**数据,是会T的,这就需要使用字典树了。
2.查询某前缀是否出现过,或者出现了几次。
显然还可以用map(STL大法好),不过还是可以用字典树跑得快些。
实现:
从上图中我们可以发现:
我们令根节点为空,其余节点为字符,我们顺着某一条路径走下去就能找到一个单词。
这就牵扯到了两个操作:插入,查找。
插入:
从图中可以直观看出,从左到右扫这个单词,如果字母在相应根节点下没有出现过,就插入这个字母;否则沿着字典树往下走,看单词的下一个字母。
具体操作: 我们给每个节点一个编号,显然一个节点最多有26个子节点(以下无特殊说明均认为只包含小写字母) 我们开一个数组,trie[i][j]表示编号为i的节点的j子节点的编号是什么(1<=j<=26),我们给每个点开26个子节点,不管是否用上(反正用不上就是编号为0)。
查找:
从左往右以此扫描每个字母,顺着字典树往下找,能找到这个字母,往下走,否则结束查找,即没有这个前缀;
前缀扫完了,表示有这个前缀。
具体: 其实有了我们的trie数组,一切都好解决了
代码实现(查前缀是否出现过):
void _insert(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=s[i]-'a'; if(!trie[now][x]) trie[now][x]=++total; now=trie[now][x]; } } bool find(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=s[i]-'a'; if(!trie[now][x]) return 0; now=trie[now][x]; } return 1; }
那么我们怎么查单词呢?
我们记录_word[i]表示以i为结尾是不是单词,显然在插入单词时将结尾元素的_word变成1就好了。同时,在find时将return 1;改为return word[now];
例题:
统计难题:
描述:cym最近遇到一个难题,Z交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在Z要他统计出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
输入: 输入数据的第一部分是一张单词表,每行一个单词,单词的长度不超过10,它们代表的是Z交给cym统计的单词,
一个空行代表单词表的结束.
第二部分是一连串的提问,每行一个提问,每个提问都是一个字符串.
注意:本题只有一组测试数据,处理到文件结束.
输出: 对于每个提问,给出以该字符串为前缀的单词的数量。
这道题不同之处在于要查找某个前缀出现的次数,我们可以在_insert()的同时记录以每个节点为结尾的前缀的出现次数sum,在find()时返回sum[now]即可。
void _insert(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=s[i]-'a'; if(!trie[now][x]) trie[now][x]=++total; sum[trie[now][x]]++; now=trie[now][x]; } } int find(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=s[i]-'a'; if(!trie[now][x]) return 0; now=trie[now][x]; } return sum[now]; } int main() { string s; while(getline(cin,s)) { if(s=="")break; _insert(s); } while(cin>>s) cout<<find(s)<<endl; }
void _insert(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=s[i]-'a'; if(!trie[now][x]) trie[now][x]=++total; now=trie[now][x]; } _word[now]=1; } bool find(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=s[i]-'a'; if(!trie[now][x]) return 0; now=trie[now][x]; } return _word[now]; } int main() { scanf("%d",&n); for(int i=1;i<=n;i++) { string s; cin>>s; _insert(s); } scanf("%d",&m); for(int i=1;i<=m;i++) { string s; cin>>s; if(_map[s]) { cout<<"REPEAT"<<endl; continue; } if(find(s)) { cout<<"OK"<<endl; _map[s]=1; } else cout<<"WRONG"<<endl; } }
[USACO08DEC]秘密消息
这道题的查找分两部分:
1.之前密码长度更长: 即查找前缀s的出现次数
2.之前密码长度更小: 即查找有多少单词是s的前缀。
重点放在2.
我们令s1表示s的前若干位,并去查找有多少单词等于s1
答案即为两部分之和
注:题目没说不会有重复密码
#include<iostream> #include<cstdio> #include<algorithm> #include<string> #include<map> using namespace std; int n,m,trie[500010][3],_word[500010],sum[500010],total,point; map<string,int>_time; string ss[500010]; void _insert(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x; if(s[i]=='0')x=0;else x=1; if(!trie[now][x])trie[now][x]=++total; sum[trie[now][x]]+=_time[s];//预处理的成果在这里 now=trie[now][x]; } _word[now]=1; } int find_sum(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x; if(s[i]=='0')x=0;else x=1; if(!trie[now][x])return 0; now=trie[now][x]; } return sum[now]; } bool find(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x; if(s[i]=='0')x=0;else x=1; if(!trie[now][x])return 0; now=trie[now][x]; } return _word[now]; } int main() { scanf("%d%d",&n,&m); for(int i=1;i<=n;i++)//我们记录每个单词出现的次数(因为字典树是不会插入重复的单词的),进行预处理: { int x; string s=""; scanf("%d",&x); for(int j=1;j<=x;j++) { char c; cin>>c; s+=c; } _time[s]++; if(_time[s]==1) ss[++point]=s; } for(int i=1;i<=point;i++)_insert(ss[i]); for(int i=1;i<=m;i++)//重点就是下面一段以及两个find函数 { int x,ans=0; string s="",s1=""; scanf("%d",&x); for(int j=1;j<=x;j++) { char c; cin>>c; s+=c; } ans+=find_sum(s); for(int j=0;j<x-1;j++) { s1+=s[j]; if(find(s1))ans+=_time[s1]; } printf("%d\n",ans); } }
前缀单词
字典树上的DP问题。
如果令f[i]表示以i为根的子树上的集合数,那么显然f[i]=所有儿子的f的乘积,如果以i为结尾是一个单词,那么f[i]+=1.(选了i就不能选他的儿子了),注意要考虑空集
#include<iostream> #include<cstdio> #include<algorithm> #include<string> using namespace std; int n,trie[10010][26],v[10010],total; void _insert(string s) { int now=0; int size=s.size(); for(int i=0;i<size;i++) { int x=(int)s[i]-'a'; if(!trie[now][x]) trie[now][x]=++total; now=trie[now][x]; } v[now]=1; } long long DP(int now) { long long ans=1; for(int i=0;i<26;i++) if(trie[now][i]) { ans*=DP(trie[now][i]); } return ans+v[now]; } int main() { scanf("%d",&n); for(int i=1;i<=n;i++) { string s; cin>>s; _insert(s); } printf("%lld",DP(0)); }
总结:
操作: 找前缀,找单词
技巧: 结合map(逃)
从入门到精通到入土: 多刷题吧,多学习一些技巧。