github代码地址:https://github.com/mrlibw/ControlGAN
关键词:T2I,文本生成图像,ControlGAN
Introduction:
现在的许多模型如果改变了输入文本的其中一个部分,那么输出的图片会与原来文本生成的图片大相径庭,没法实现一部分的修改。如下图所示。

controlGAN,由三个部分组成:
1.word-level spatial and channel-wise attention-drive generator,采用了attention机制,多层次结构。
2.word-level discriminator,研究词与图像子区域的关系,来区分不同视觉属性。
3.perceptual loss,通过减少生成过程中的随机性,强制generator保持与修改文本无关的部分。
Controllable Generative Adversarial Network
给定一段文本S,目标是合成一张与S语义相关的图像I',同时使生成过程可控,即当S修改为Sm时,合成结果I''应与Sm语义相关,同时保留与修改的文本无关的内容。
模型结构。
ControlGAN基于multi-stage AttnGAN。
给定文本S,输入到text encoder(一个预训练的双向RNN),得到文本特征s∈RD,和w属于RDxL,s有D维,words数量L。
对s做conditioning augumentation(CA),得到增强后的文本特征s'。生成一个随机变量z,s'和z连接到一起作为输入送到stage I。
整个模型逐阶段生成从粗糙到精细的图片,对于每个阶段,网络输出一个隐藏的可视特征vi,vi是相对应的generator Gi的输入。
spatial attention和channel-wise attention会将w和vi作为输入,输出attentive word-context feature。这个特征会vi contact一起,作为下一阶段的输入。
spatial attention只将word与单个空间位置关联起来,不考虑channel信息。
论文新提出的channel-wise attention考虑word与channel的关联。
实验发现channel-wise attention与对应词的语义信息关联,而spatial attention与颜色相关,因此该结构可以用来区分不同的视觉属性。
Channel-Wise Attention,结构如图所示。
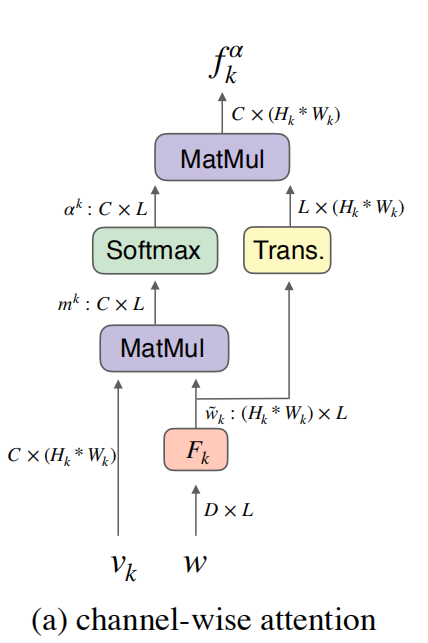
在第k层,输入word特征w∈RDxL和视觉特征vk∈RCx(Hk*Wk),Hk和Wk分别代表第k层特征图的高和宽。
w通过一个perception layer Fk被映射到与vk相同的语义空间,即w'k=Fkw,Fk∈R(Hk*Wk)xD.
记channel-wise attention矩阵为mk∈RCxL,mk=vk * w'k,从而mk聚集了所有空间位置的channel和words的联系信息。接着,使用softmax函数对mk进行归一化,得到αk,如下图。
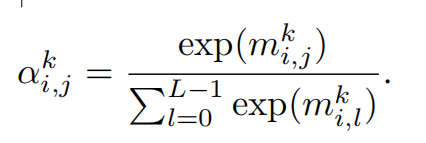
attention weight αki,j 代表vk的第i个channel和文本S中的第j个单词之间的关系,越大代表关联越近。
最后,fαk=αk*(w'k)T, 其中 fαk∈RCx(Hk*Wk)。
fαk中蕴含了每个channel和word的关系,因此具有更高关联值的channel在生成过程中会被增强,从而将生成过程中的每个channel给分开,并且降低无关的channel带来的影响。
Word-level Discriminator,如图所示。

为了让generator只修改部分图像内容,discriminator应向generator提供详细的训练数据。
输入word特征w和w',w和w'∈RDxL,其中,w根据原始文本S编码得到,w'是从一个随机采样的不匹配文本中编码得到。视觉特征nreal和nfake,由基于GoogleNet的图片encoder得到,它们分别有real image I和生成的image I'得到。
为了简单起见,使用n∈RCx(H*w)来代表nreal和nfake。使用w属于RDxL来代表两个文本特征w和w'。
word-level discriminator包含一个perception layer F',它用于对准n和w的channel维度,即得到 n'=F' * n,其中F'∈RDxC,是一个待学习的权重矩阵。
接着,计算word-context关联矩阵m=wT * n',其中m∈RLx(H*W)。然后使用softmax函数进行归一化得到关联矩阵β。
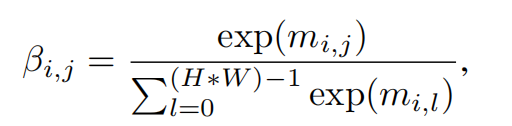
其中, βi,j代表第i个word和第j个图像子区域只见的关联值。 然后计算感知图像子区域的word特征b,b=n' * βT,b∈RDxL。b包含了所有空间信息。
此外,通过一个word-level的self-attention得到一维向量γ,长度L代表每个单词的相对重要性。重复γ D次得到γ',γ'属于∈RDxL。
计算b'=b⊙γ',⊙代表element-wise的乘积,即b'i,j为bi,j*γ'i,j.
最后根据如下公式得到第i个单词和整副图片的关联。

σ是sigmoid函数。
最后,计算Image和Sentence的最终关联Lcorre,Lcorre=Σi=0L-1ri.将其反馈给generator就可以进一步帮助修改每一个子区域。
Perceptual Loss
由于没有在于文本无关的图像区域施加限制,生成的图片可能有高度随机性,也可能会和其他内容语义不相关。为了减少随机性,本论文引入了基于16-layer VGG network的perceptual loss,该模型在ImageNet数据集上预训练过。该网络结构用于从生成的图片I'和真实的图片I中提取语义特征,定义如下:

其中Φi(I)代表VGG的第i层的activation。
目标函数
generator和discriminator是通过交替训练来降低generator loss LG和discriminator loss LD
generator loss LG包括对抗损失LGk,感知损失Lper,文本和图片关联度损失Lcorre和基于余弦相似度的文本图片匹配损失LDAMSM。
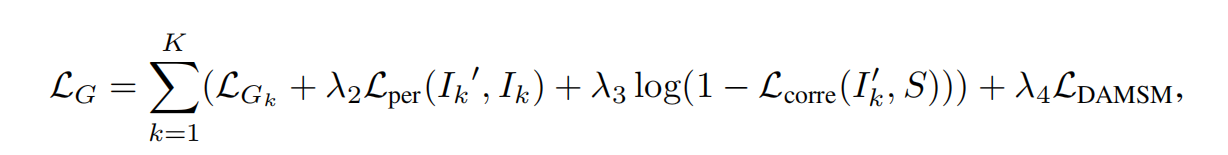
K是stage数,Ik是从真实数据分布Pdata中采样得到的图片的第k个stage。I'k是从模型分布PGk中采样得到的。
三个λ是超参数。
LGk由非条件对抗损失和条件对抗损失构成,其中非条件对抗损失用于确保图片的真实度,条件对抗损失保证文本和图片匹配。

discriminator loss.
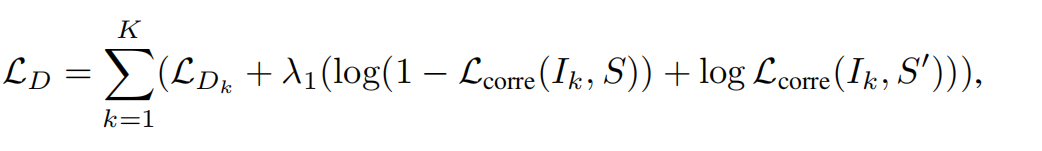
其中,Lcorre代表与单词相关的区域是否存在,S'是从文本数据集中随机采样的与Ik不匹配的句子。
对抗损失LDk与generator相同。

实验
数据集
基于CUB和COCO。CUB包含8855训练图片和2933测试图片,每张图片有10个对应文本。COCO包含82783训练图片和40504验证图片,每张图片有5个对应文本。使用StackGAN中介绍的方法对其进行数据预处理。
实现
其他:
Image Caption,即 Image-To-Text。