论文:
SpecAugment: A Simple Data Augmentation Methodfor Automatic Speech Recognition
思想:
SpecAugment是一种log梅尔声谱层面上的数据增强方法,可以将模型训练的过拟合问题转化为欠拟合问题,以便通过大网络和长时训练策略来缓解欠拟合问题,提升语音识别效果
模型:
- 输入特征:log梅尔声谱
- 声谱增强:将log梅尔声谱的时域和频域看作二维图像,时间片长度为τ,频域长度ν
- 时间扭曲,穿过图像中心的水平直线上,(W,τ-W)范围内的随机点,向左或向右平移w距离,0=<w<=W
- 时间掩蔽,沿时间轴方向的[t0,t0+t)范围内的连续时间步进行掩蔽,其中0=<t0<τ,t服从[0,T]均匀分布
- 频率掩蔽,沿频域轴方向的[f0,f0+f)范围内的连续频率通道进行掩蔽,其中0=<f0<ν,f服从[0,F]均匀分布

- 网络框架采用LAS结构[1],encoder部分采用2conv+max_pooling(stride=2)+d层的Bi-LSTM(cell=w)+attention结构;decoder部分采用2LSTM(cell=w)
- 语言模型融合[2]:embeddng (1024 for LibriSpeech/256 for Switchboard)+2LSTM(cell=300)
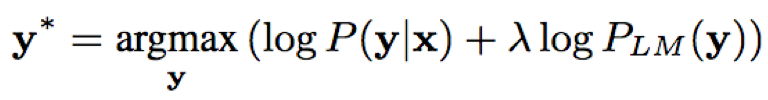
- 解码:beam search,beam width=8
训练策略:
- 数据集:LibriSpeech 960h/Switchboard 300h
- 输入特征:80维fbanks,batch size=512
- 学习率策略:学习率策略是一种能够提升识别效果的重要因子,分为快速启动-稳定-指数衰减(Sr,Si,Sf)
- 快速启动阶段(0~r),学习率lr从零开始增长到0.001
- 稳定阶段(Sr~Si)学习率保持稳定
- 指数衰减阶段(St~Sf): 学习率指数衰减到学习率最大值的1/100=0.00001
- 权重噪声策略:标准差为0.075的高斯噪声,权重噪声有助于提升模型鲁棒性,开始时间Snoise


其中1、2、3分别为模型训练的迭代次数三只模式,由短到长,Sr为学习率快速上升阶段的step,Snoise为应用权重噪声的开始的step,Si为学习率指数衰减开始的step,Sf为指数衰减终止的step
- 均匀标签平滑:不确定度为0.1,即正确的类别标签置信度降低0.9,其他类别标签置信度相应提升0.1,但是当学习率较小时,标签平滑容易导致模型训练不稳定,所以最好在学习率衰减之前应用权重噪声较好
实验效果:
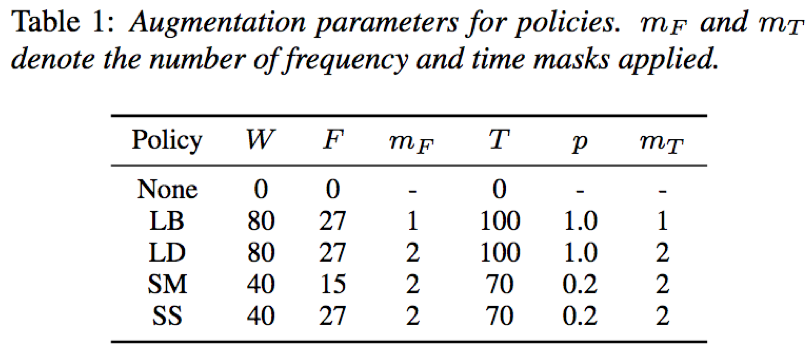
实验中的增强参数如下
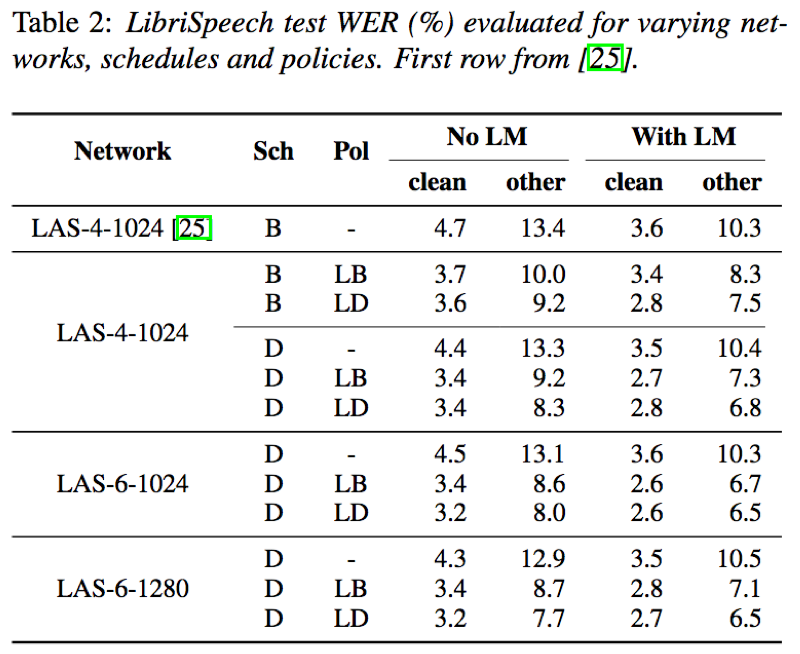
- log梅尔声谱增强、学习率/权重噪声策略、增加LSTM深度和结点数均有助于提升识别效果;其中LAS-d-w,d为LSTM层数,w为结点数
- 不采用LM情况下,LAS-specaugment即可得到state-of-the-art效果,采用LM时进一步提升了state-of-the-art效果

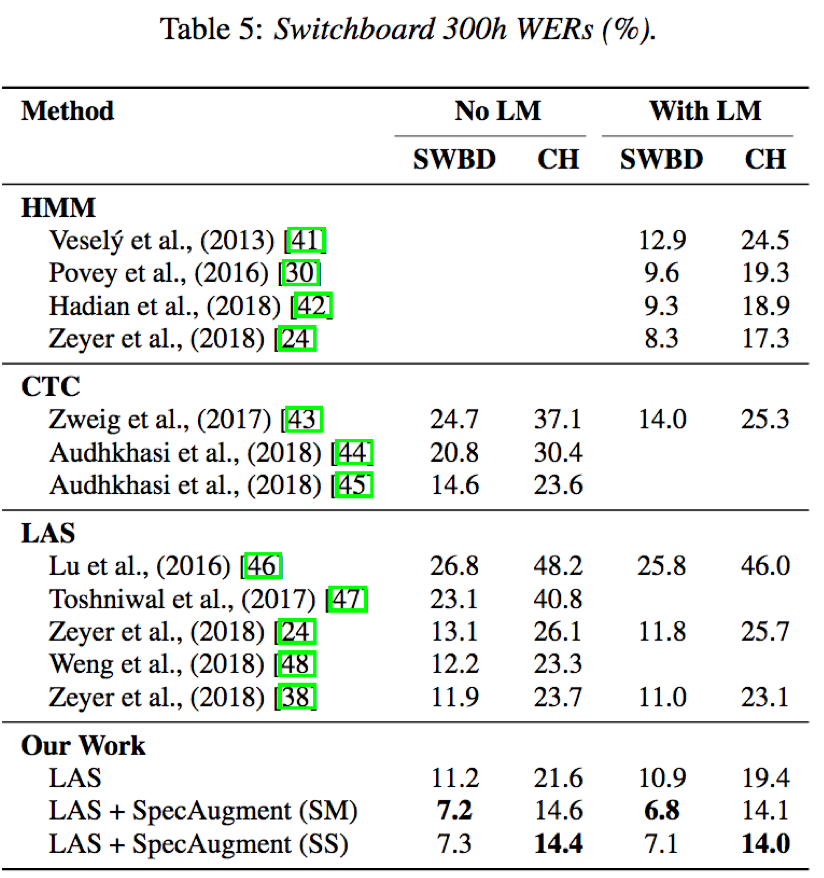
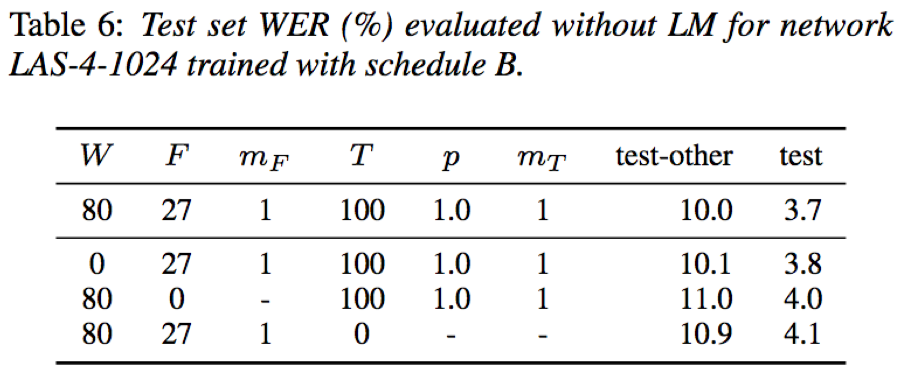
- 声谱增强的三种策略中,时间扭曲策略相比时间和频率掩蔽策略对结果的提升最小,并且计算代价最大
结论:
- 时间扭曲有助于提升识别效果,但是相对时间和频率掩蔽策略重要性最低,且计算代价最高
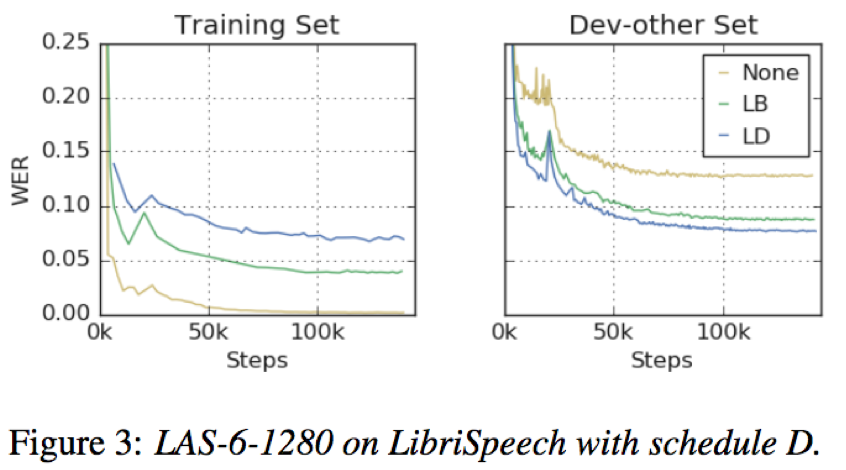
- log梅尔声谱增强能够将模型训练的过拟合问题转化为欠拟合问题,从而可以通过大模型和长时训练予以缓解
- 标签平滑策略容易使模型训练不稳定,尤其当学习率较小时更为严重,所以标签平滑策略最好应用在学习率快速上升和hold阶段
env:
- tensorflow/pytorch
- python3
- numpy
- librosa
- matplotlib
安装:pip3 install SpecAugment
Usage:python3 spec_augment_test_TF.py/spec_augment_test_pytorch.py
增强效果:
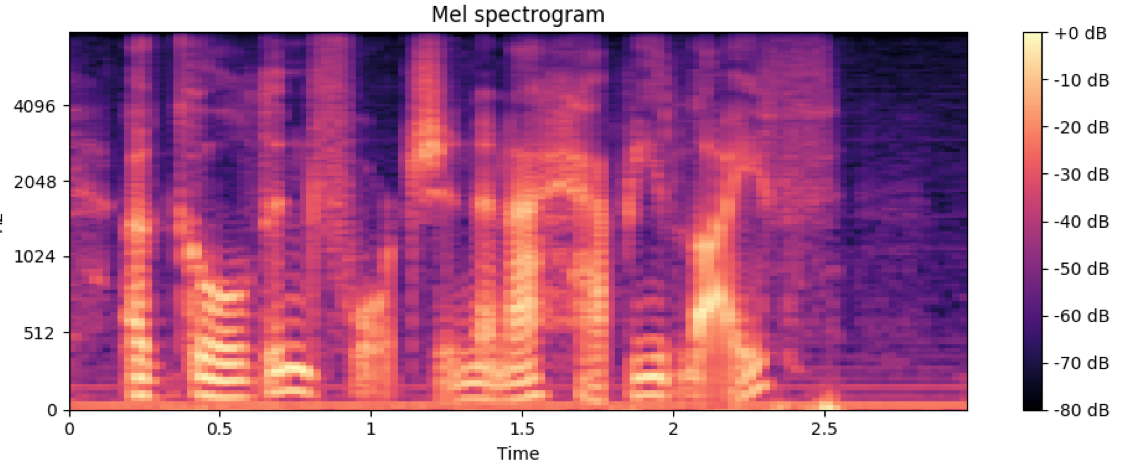
原始声谱

时域和频域掩蔽
Reference: