论文:
EXPLORING ARCHITECTURES, DATA AND UNITS FOR STREAMING END-TO-END SPEECH RECOGNITION WITH RNN-TRANSDUCER,2018
CTC的一个问题在于,其假设当前帧的输出与历史输出之间的条件独立性;RNN-T引入预测网络来弥补CTC这种条件独立性假设带来的问题
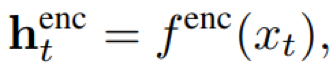

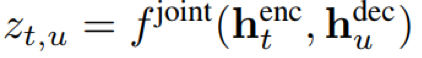
思想:
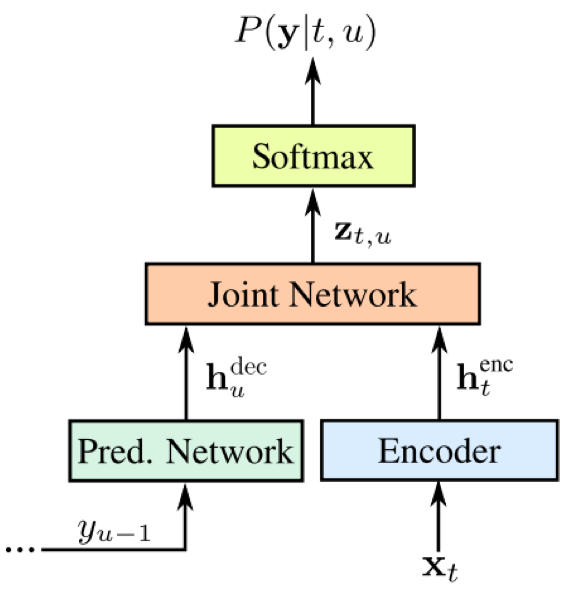
1)针对CTC网络的条件独立性假设(当前时刻输出与之前的输出条件独立),引入语言模型预测网络分支,通过联合前馈神经网络将二者结合,在预测最终输出时能够同时利用声学和语言特征信息;
2)在grapheme作为建模单元基础上,引入了词组单元wordpieces,能够捕获更长的文本信息,有利于减少替换错误;
模型:
- CTC网络: 采用多级任务CTC,建模单元包括音素phoneme、字母grapheme、词条wordspieces,音素CTC结构采用5层LSTM(700cell)、字母CTC采用10层LSTM(700cell)、词条CTC采用12层LSTM(700cell);此外,在字母LSTM输出时,通过时域卷积(kenel size=3)来缩短时间片长度,减少参数量,加速训练的同时对效果不造成影响
- 预测网络: 对于字母建模单元,预测网络采用两层LSTM(1000cell);对于词条单元,因为词条标签数目较多,在LSTM之前引入一个较短的embedding层,维度为500
- 联合网络:采用前馈神经网络结构,即一层全连接层(700)+softmax+CTC损失
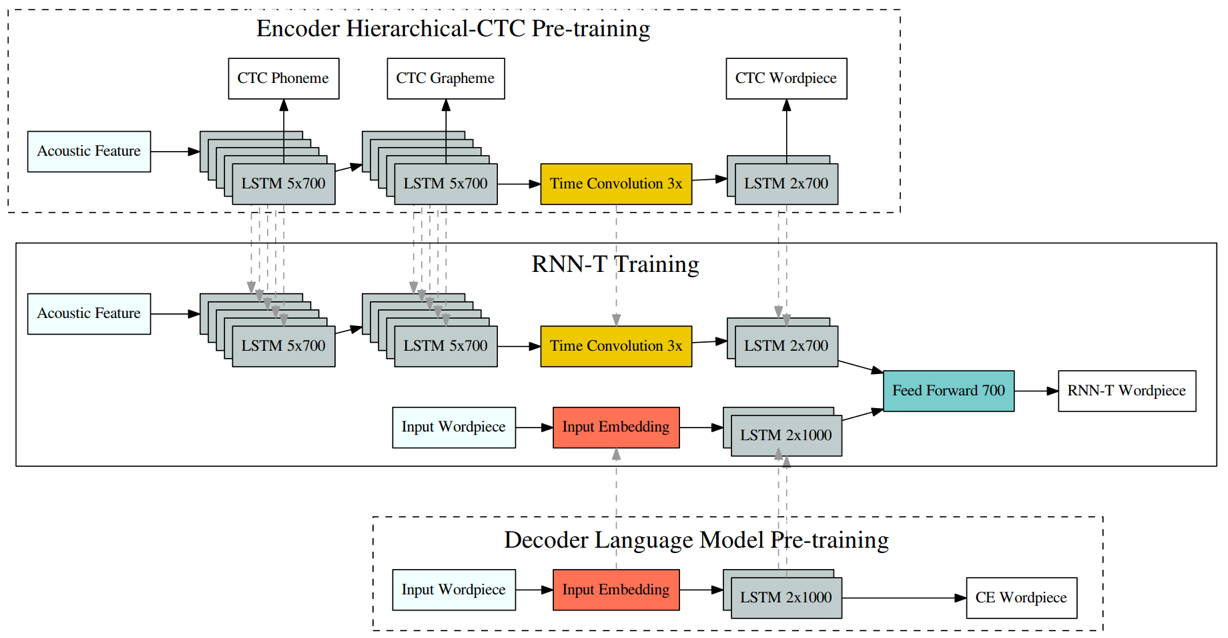
细节:
- 输入特征:声学特征输入特征80logfbank+一阶差分+二阶差分=240维;语言模型特征采用词组词典对应的one-hot向量
- 训练数据采用[2]中的数据增强,添加噪声和混响,每个样本得到20个左右的混响或噪声增强数据
- CTC网络预训练采用多级(phonemes、graphemes、wordspieces)多任务CTC目标损失/预测网络预训练采用交叉熵损失/联合网络采用词条单元wordspieces CTC目标损失
- 音素级CTC的输出单元个数为61个phoneme+blank;字母级CTC的输出单元个数为44grapheme+blank;词条级CTC的输出单元个数为1000~30000有效词条+blank

grapheme

wordspiece
- 解码:beam search,输出单元为grapheme beam width=100;输出单元为词条时beam width=25
训练:
- 声学模型训练数据集:18000小时voice-search、voice-dictation+混响和噪声增强;语言模型训练数据集:10亿句文本数据,来源于voice-search、voice-dictation、匿名化google搜索等日志;测试集15000voice-search utts+15000voice-dictation utts
- CTC网络和预测网络采用预训练进行初始化,联合网络随机初始化
- grapheme beam width=100,wordpieces beam width=25
预测:当前步输出yu = p(y|xt,yu-1),如果yu为non-blank,那么下一步预测输出为p(y|xt,yu),否则下一步输出为p(y|xt+1,yu-1);当最后一个时间步T输出为blank时终止
实验:
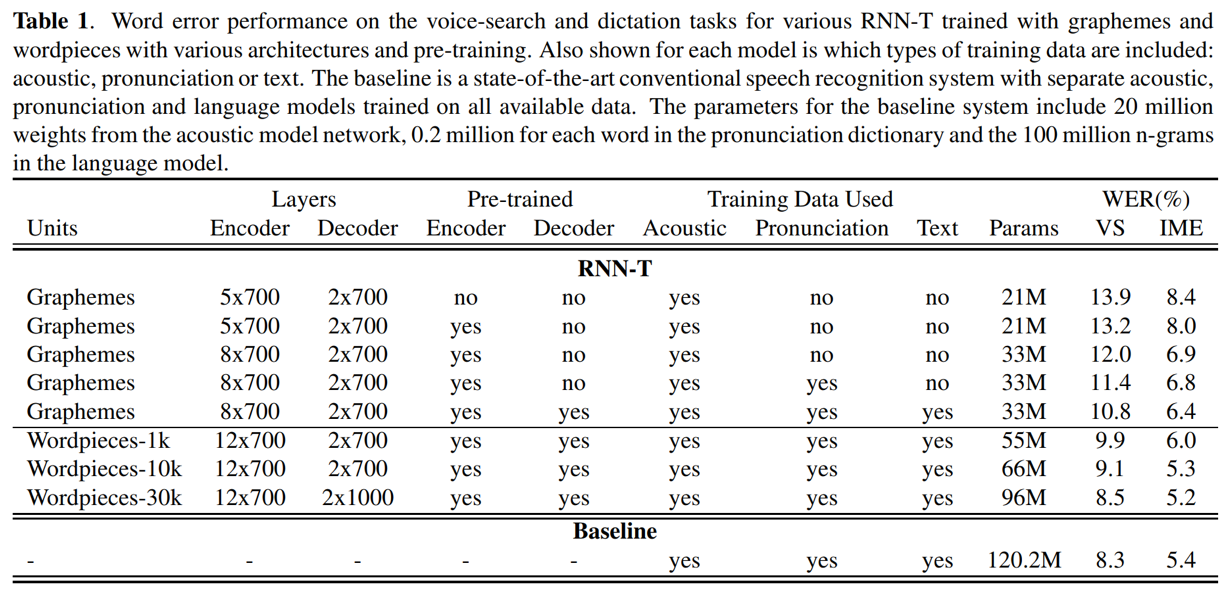
- 论文中RNN-T取得了接近state-of-the-art的效果WER :voicesearch 8.5% voice-dictation 5.2%
- CTC网络和语言模型预训练,均有助于提升效果
- 提升LSTM深度从5层到8层,带来10%相对提升
- wordspiece RNN-T相对于grapheme RNN-T实际效果更好,原因在于wordspiece作为输出单元能够降低替换错误
- grapheme LSTM输出,通过时域卷机操作(kernel size=3),在不影响实际效果的情况下,有效减少wordpiece输入的时间片维度,节省wordpiece LSTM参数训练和解码的时间
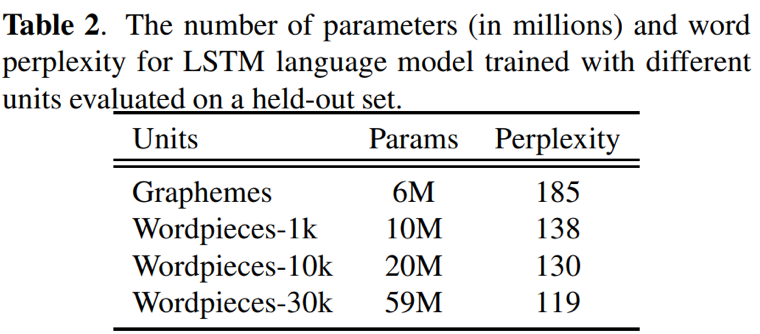
- wordspiece作为输出单元时,相对于grapheme,语言模型困惑度更低
- 增加wordspiece输出单元个数1k->30k,有助于进一步降低语言模型困惑度,提升实际效果,但也相应的增大了参数量
https://github.com/ZhengkunTian/rnn-transducer/blob/master/rnnt/model.py
环境:
- kaldi特征提取+CMVN
- pytorch模型构建及训练
数据集:aishell1 178h train/dev/test
输入:3*left-context+current frame+0*right-context=4*40=160维
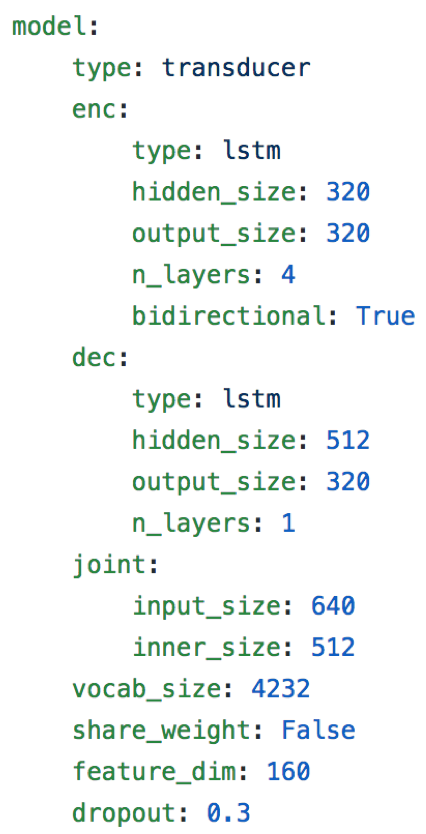
模型:
- CTC网络4*Bi-LSTM(320)
- 预测网络:1*LSTM(512)
- 联合网络:1*full_connect(512)+tanh+softmax(4232)
训练:
- SGD
- max_gram=200
- lr=0.0001
- momentum=0.9
- weight_ratio=0.5
解码:贪心搜索,每一个时间步取最大概率对应的输出
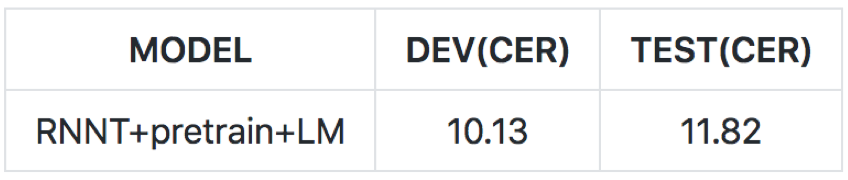
效果:aishell dev:10.13/test:11.82