论文:
VoxCeleb2: Deep Speaker Recognition
思想:显然,VoxCeleb2是在voxceleb基础上扩充和改进,仍然是两个贡献点:
1)扩大声纹识别数据集,由voxceleb的1251说话人超过19万句子,到voxceleb2的超过6000说话人共计超过百万的语音句子,适用于噪声和非约束场景下的声纹识别任务;
2)相比VGG-M,采用更深更先进的resnet-34和resnet-50网络架构,能够进一步提升识别效果
模型:
本文的网络结构采用了两种相较于VGG层数更深的resnet结构,resnet通过多个res-block串联而成,每个res-block包含多层卷积层和跳跃连接机制。本文实验了两种resnet结构,resnet-34和resnet-50;此外,类似于VoxCeleb,VoxCeleb2也采用了全局平均池化层来缩减训练参数和接受任意长度的test样本输入
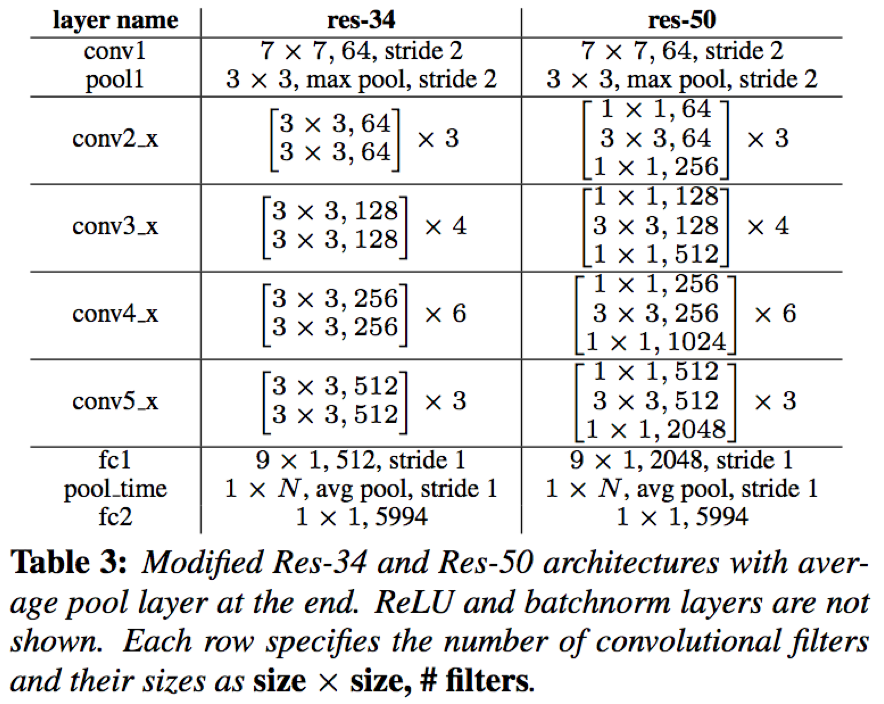
训练:
- 数据集:voxceleb2:6000+celebrities,over一百万utts.
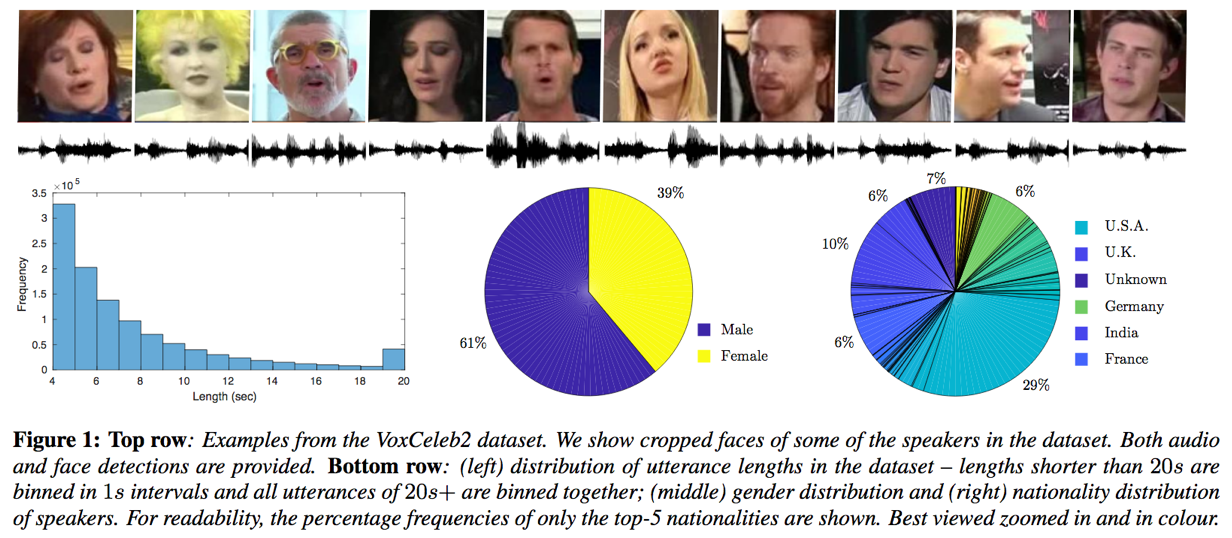
- 输入:对输入音频进行滑动切片,每片3s,得到512*300大小的频-时图输入到网络中;
- 预处理:CMVN,均值方差归一化
- tricks:网络中引入bn,激活函数ReLU
- 训练目标:
- 说话人辨别:CE交叉熵损失,输出单元为5994
- 说话人确认:对比损失contrastive loss,采样先CE预训练再siamese网络对比损失finetune策略,finetune时将最后一层全连接替换为维度为512的全连接
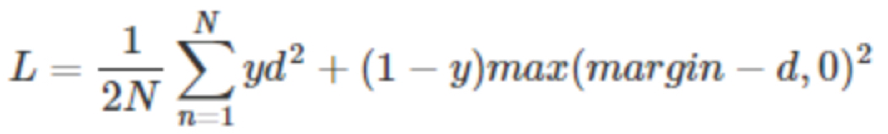
其中,d2为样本对之间的欧式距离,y属于{0,1},y=1表示样本对属于同一类,y=0表示不属于同一类;这样,对于同一类之间的距离越小,损失越小;对于不同类之间的距离越大,损失越小;这就起到缩小类内间距,同时扩大类间间距至少margin的目的
test augmentation:test时采用三种策略的特征表达计算
- 对测试音频采取滑窗形式切成3s的音频段,随机采样10个音频段,然后计算10个特征表达的均值(1)
- 采用平均池化层,能够接受任意长度输入,转化为固定维度的输出表达(2)
- 对测试音频采取滑窗形式切成3s的音频段,随机采样10个音频段,比较两个样本的相似度时,采取任意两两距离计算,得到10*10个距离得分,然后取均值作为最终距离得分(3
训练策略:
- epoch=30
- 早停
- batch-size=64
- SGD with momentum=0.9、weight decay=5E-4、对数衰减的学习率从10-2->10-8
实验结果:
- 在声纹确认任务中,实验结果表明resnet-50和resnet-30均取得了比i-vector based model和VGG-M更好的结果;此外,resnet-50相比于resnet-30优势更佳明显,得益于其更深的网络结构和skip-connection;再者,test时的三种特征表达中,计算10*10个距离的均值策略(3)要稍微优于平均池化层(2),同时平均池化层(2)有略优于10个音频段特征表达的均值(3)
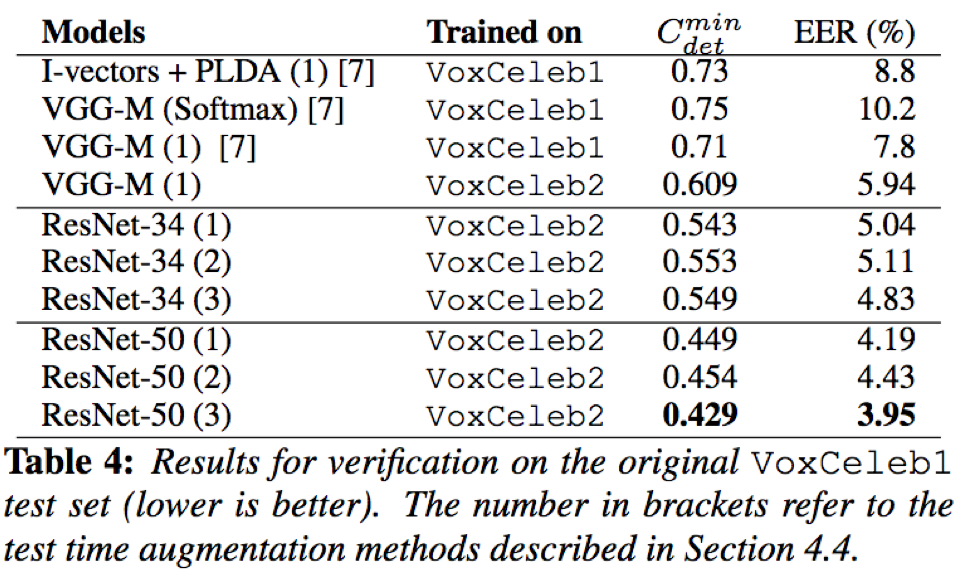
- 确认任务中,从voxceleb1数据集中抽取测试样本对进行测试,抽取时有两种策略,1)从整个voxceleb1中随机抽取581,480个样本对;2)从voxceleb1具有相同民族和相同性别的数据子集中抽取552,536个样本对;在两种策略下,测试效果都比较好,侧面反映了模型的泛化能力

结论:本文相当于在voxceleb上针对两个贡献点继续扩充和改进:
1)提供了一个更大规模(6000+speakers,over 100万utts)的声纹识别数据集,该数据来源于YouTube,同样适应于非约束性的数据场景;
2)采用相比于VGG-M深的多的CNN网络(resnet-34、resnet-50)进行说话人辨别和确认的基本框架,同样引入全局平均池化,一方面减少模型训练参数,另一方面test能够接受任意长度的输入;此外,resnet结构中引入了BN进行归一化,一定程度上加速训练过程
Reference:
[1] https://arxiv.org/pdf/1706.08612.pdf(voxceleb)
[2] https://arxiv.org/pdf/1806.05622.pdf(voxceleb2)