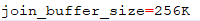一、索引单表优化案例
where和order by后面的字段建立索引,如果where后面有字段是范围查找,则该字段不建索引,否则后面的索引会失效。




能查出结果,说明对错的问题解决了。

分析:type为all,即全表扫描,不好。Using filesort:产生了文件排序。
![]()
现在除了主键索引,没有建其他索引。

开始优化:
1.1、新建索引+删除索引。
现在只能尝试着建索引,我们也不知道索引建得对不对,好不好,只能慢慢调整。
现在用到了三个字段:category_id、comments、views.由于where条件后面需要被查询到的要建索引。

由于要把category_id、comments、views三个单词写全,则索引名字太长了,这里取首字母,简写为ccv.


之前只有一个主键索引,现在三个字段category_id、comments、views构成了一个复合索引,而且已经排好序,在检索的时候,先找category_id ,再找comments,最后找views。

分析:
首先复合索引已经被用到了。由于comments>1,所以type为range,已经达到了最低要求range。虽然全表扫描没有了,但是Using filesort仍然存在。但是如果将comments改为等于1,发现type一下子从range变成了ref,ref为const,const,并且没有了filesort。这种情况下是最好的,但是不能这样做。

由于你建的索引是category_id、comments、views,正常来说可以用上索引,因为都是等于的时候,这三个字段都有。而现在comments>1,这是一个范围,而不是一个常量,此时mysql无法排序,故产生文件排序。而范围会导致索引失效,后面的索引也用不上。
以后给产品经理提需求,尽量让产品经理提等于的需求。如form表单中重要的字段用红色的*表明此处必填,这些字段从底层往前推你会发现,产品经理只图好看,只关心表现层,他不关心哪些字段重要,哪些字段不重要,他恨不得每一个字段都是必填项。产品经理做的产品原型的字段对我们java程序员而言是表字段,你建好了索引,他给你的字段有没有,是大于范围还是等于常量,对你系统的sql写的难易程度和查得是否快很有影响。你自己跟产品经理碰需求的时候,要返过来引导并建议产品经理,这个字段不能为空,否则程序会慢而不是我做不出。这是从技术角度合理的建议。

只好把当前不太合适的索引删除。

由于comments>1是一个范围,我们可以绕开comments,只用category_id、views建立组合索引。
第二次新建索引:




发现:type为ref(非唯一性索引扫描),也用到了索引,又没有Using filesort,且ref为const。此时检索(查询)和排序同时用到了索引。

二、索引两表优化案例
左连接,左表全表扫,索引加在右表;右连接,右表全表扫,索引加在左表。
创建book和class表结构

往class表插入数据
往book表插入数据



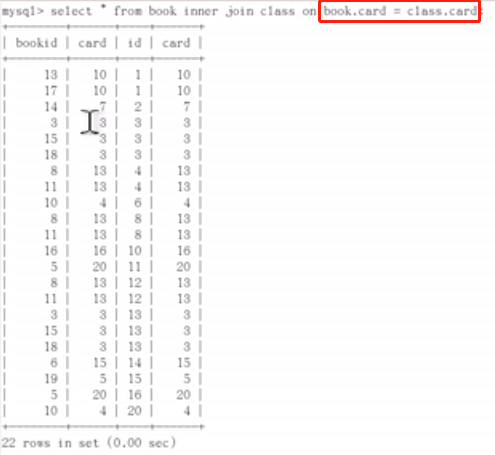
有了主外键以后,索引是应该写在左表还是右表?加在哪些字段。
单表好说,我不停的改,但是左外连接和右外连接就有点啰嗦了。
下面开始explain分析:

发现:type为all,左连接和右连接总有一个表是来驱动的,
现在两张表都有card字段,是加在book.card还是加在class.card?我们可以进行尝试,
1、先给book表的card字段建立索引。


发现:class表(左表)class仍为all,但是给book表添加索引后,type变为了ref,ref为db0629.class.card,rows变为1。book表为右表。即左连接,左表全表扫,索引加在右表上面;右连接,索引加在了左表上面。


2、先给class表的card字段建立索引。


由于ref要优于index,在左连接的前提下,同样的sql,索引加在右表比加在左表要好。
DBA建数据库的索引是为全局负责,他不是为你负责,如果DBA把索引建在class表,则你应该把sql写成:Select * from book left join class on class.card=book.card;如果DBA把索引建在book表,则你应该把sql写成:select * from class left join book on class.card=book.card;
右连接,右表全表扫,索引加在左表。



三、索引三表优化案例
当使用两个left join时,给后面两个表的连接字段加索引。
在上面的案例下再加一张表:
创建phone表

向phone表中插入数据


现在是三张表。三张表除了主键索引均无其他索引。


三表连接的SQL:select * from class left join book on class.card=book.card left join phone on book.card=phone.card;由于是左连接,即class left join book on class.card=book.card,故需要在右表建立索引。在这之后又有一个left join,故要在phone表上建立索引。
select * from class left join book on class.card=book.card left join phone on book.card=phone.card;


Explain后发现,没有加索引会导致三个表都是全表扫描。


给第三张表和第二张表建了外键索引之后,进行explain,效果如下:

发现:后两行的type都是ref且总rows优化很好,效果不错。因此索引最好设置在需要经常查询的字段中。
四、结论:
Join语句的优化:
1、尽可能减少join语句中的NestedLoop(嵌套循环)的循环总次数(不要join过多或嵌套),“永远用小的结果集驱动大的结果集(用小表驱动大表)”。如class表中的都是书籍类,而book表中的都是书籍,书籍的数量远比书籍类的数量多,故class表是小表,book表是大表,故用class表驱动book表,即在左连接中,class表在book表的左边,在book表中建索引,这样,小表全表扫描导致的IO访问次数少。
2、优先优化NestedLoop(嵌套循环)的内层循环。最里面的快了,才能轮到外面。
3、保证join语句中被驱动表上join(连接)条件字段已经被索引。
4、当无法保证被驱动表的join(连接)条件字段被索引且内存资源充足的前提下,不要太吝惜joinBuffer的设置。将my.ini配置文件中将joinBuffer调大。