1.先上一下爬取之后保存的成果,然后顺便将要求给说明一下,需要爬取的是文章等的标题,文章等的链接,以及文章的内容,含有div,和p标签,以及,img,但不包含alt标签,
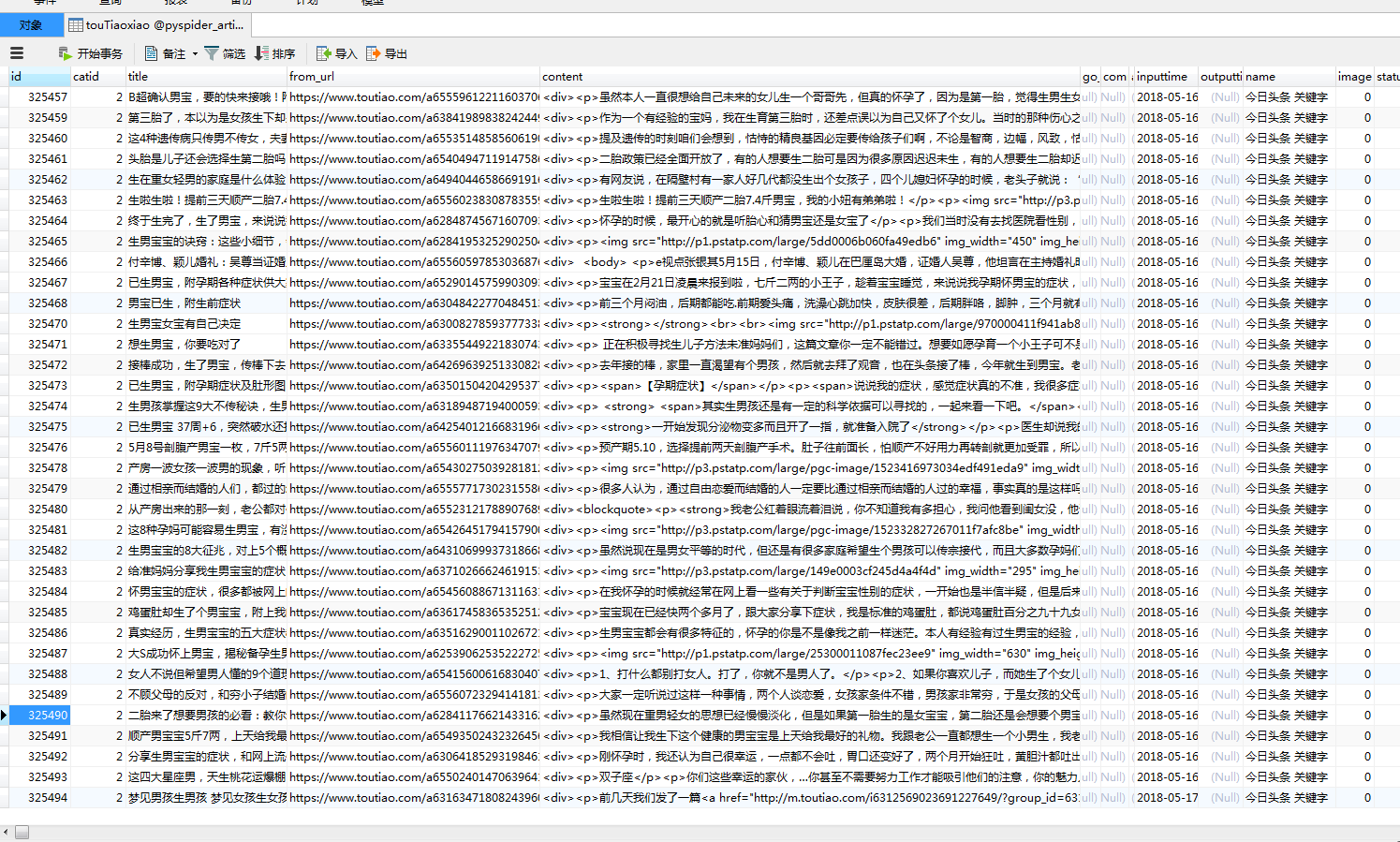
2.设置请求headers,在craw_config中设置,当然,设置on_start方法中也是没有问题的

3.由于进入今日头长的关键字界面,需要输入关键字,这部分是从数据库中的拿取,当然也可以手动的输入,但此由于量比较大,采用的是从数据库中提取,代码如下,
connect = pymysql.connect(
host='192.168.1.128',
port=3306,
user='jtcm',
password='qA0130',
db='zhousicaiji',
charset='utf8'
)
cursor = connect.cursor()
cursor.execute("select name from toutiao_key_xiaoyu where state = 1 limit 10000")
keywords = cursor.fetchall()
#print(keywords)
for key in keywords:
#print(key)
#print(type(key))
keyword = "".join(key)
print(keyword)
#print(type(keyword))
keyword = keyword.encode('utf-8')
print(str(keyword))
4.找到关键字的的接口部分的数据,通过抓包工具和分析网页,发现是需要传入这些参数,代码如下
params = {
'offset': 1,
'format': 'json',
'keyword':str(keyword),
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(params)
5.拼接出完整的url后,再调用self.crawl,然后在这里调用index_page方法
self.crawl(url, callback=self.index_page,validate_cert=False,exetime=time.time()+30*60)
6.通过正则找到该网页中的文章的链接组,将这些链接通过for循环,变成单个的url
def index_page(self, response):
print(response.url)
print(response.text)
result = response.text
#正则匹配网址
pattern = re.compile('"article_url": "(http://toutiao.com/group/d+/)"')
article_urls = pattern.findall(result)
#print(article_urls)
for article_url in article_urls:
print(article_url)
7.再调用self.crawl,然后在这里调用detail_page方法
self.crawl(article_url, callback=self.detail_page,validate_cert=False,exetime=time.time()+30)
8.提取出文章等的内容,标题,链接,图片链接
#print('----11------')
title = response.doc('title').text()
#print(response.url)
print(response.text)
article_content = re.findall(r'articleInfo:(.*?{[sS]*?),[\ns]*commentInfo', response.text)
#print(article_content)
9.对内容进行清洗,过滤。
for content_o in article_content:
print('----12------')
a = execjs.eval(content_o)
print(a['content'])
content = a['content']
#提取内容
content = content.replace('<','<')
content = content.replace('>','>')
content = content.replace('=','=')
content = content.replace('"','"')
#print('alt="%s"'%title)
content = content.replace('alt="%s"'%title,'')
print(content)
name = u'今日头条 关键字'
link = response.url
print(link)
now_time = datetime.date.today()
catid = "2"
9.存入数据库
# 连接mysql
connect = pymysql.connect(
host='192.168.1.128',
port=3306,
user='jtcm',
password='qA0130',
db='pyspider_articles',
charset='utf8'
)
cursor = connect.cursor()
try:
cursor.execute("insert into touTiaoxiao(catid,from_url,title,content,inputtime,name) values ('%s','%s','%s','%s','%s','%s')"%(catid,response.url,title,content,now_time,name))
connect.commit()
except pymysql.err.IntegrityError:
print('该文章已存在!')
.以下是完整代码,大致了解一下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-05-16 09:42:41
# Project: test_touTiao
from pyspider.libs.base_handler import *
import pymysql
from urllib import urlencode
import time
import re
import datetime
import pymysql
import json
import execjs
from bs4 import BeautifulSoup
import requests
#此版作为后来的完整版,开始设置为大规模爬取
class Handler(BaseHandler):
crawl_config = {
'headers' : {
"proxy-Connection":"keep-alive",
"Pragma":"no-cache",
"Cache-Control":"no-cache",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
}
}
@every(minutes=2 * 60)
def on_start(self):
connect = pymysql.connect(
host='192.168.1.128',
port=3306,
user='jtcm',
password='qA0130',
db='zhousicaiji',
charset='utf8'
)
cursor = connect.cursor()
cursor.execute("select name from toutiao_key_xiaoyu where state = 1 limit 10000")
keywords = cursor.fetchall()
#print(keywords)
for key in keywords:
#print(key)
#print(type(key))
keyword = "".join(key)
print(keyword)
#print(type(keyword))
keyword = keyword.encode('utf-8')
print(str(keyword))
params = {
'offset': 1,
'format': 'json',
'keyword':str(keyword),
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(params)
#print(url)
self.crawl(url, callback=self.index_page,validate_cert=False,exetime=time.time()+30*60)
#print('----1------')
#更改该关键词的状态为取出中
cursor.execute('update toutiao_key_xiaoyu set state = 0 where name = "%s"' % keyword)
#print('----2------')
connect.commit()
#关闭数据库连接
cursor.close()
connect.close()
@config(age=1 * 6 * 60 * 60)
def index_page(self, response):
print(response.url)
print(response.text)
result = response.text
#正则匹配网址
pattern = re.compile('"article_url": "(http://toutiao.com/group/d+/)"')
article_urls = pattern.findall(result)
#print(article_urls)
for article_url in article_urls:
print(article_url)
self.crawl(article_url, callback=self.detail_page,validate_cert=False,exetime=time.time()+30)
@config(priority=2)
def detail_page(self, response):
#print('----11------')
title = response.doc('title').text()
#print(response.url)
print(response.text)
article_content = re.findall(r'articleInfo:(.*?{[sS]*?),[\ns]*commentInfo', response.text)
#print(article_content)
for content_o in article_content:
print('----12------')
a = execjs.eval(content_o)
print(a['content'])
content = a['content']
#提取内容
content = content.replace('<','<')
content = content.replace('>','>')
content = content.replace('=','=')
content = content.replace('"','"')
#print('alt="%s"'%title)
content = content.replace('alt="%s"'%title,'')
print(content)
name = u'今日头条 关键字'
link = response.url
print(link)
now_time = datetime.date.today()
catid = "2"
# 连接mysql
connect = pymysql.connect(
host='192.168.1.128',
port=3306,
user='jtcm',
password='qA0130',
db='pyspider_articles',
charset='utf8'
)
cursor = connect.cursor()
try:
cursor.execute("insert into touTiaoxiao(catid,from_url,title,content,inputtime,name) values ('%s','%s','%s','%s','%s','%s')"%(catid,response.url,title,content,now_time,name))
connect.commit()
except pymysql.err.IntegrityError:
print('该文章已存在!')
print('-----1-----')
cursor.close()
connect.close()
return {
"url": response.url,
"title": response.doc('title').text(),
"content":content,
}