https://zhuanlan.zhihu.com/p/279904125
我们曾在【3. 基本元素】中简单介绍了SRQ的概念,本文将带大家了解更多关于SRQ的细节。
基本概念
什么是SRQ
全称为Shared Receive Queue,直译为共享接收队列。我们知道,RDMA通信的基本单位是QP,每个QP都由一个发送队列SQ和接收队列RQ组成。
SRQ是IB协议为了给接收端节省资源而设计的。不同于每个QP都拥有一个独立的RQ,我们可以把一个RQ共享给所有关联的QP使用,这个公用的RQ就称为SRQ。当与其关联的QP想要下发接收WQE时,都填写到这个SRQ中。然后每当硬件接收到数据后,就根据SRQ中的下一个WQE的内容把数据存放到指定位置。

为什么要用SRQ
通常情况下,我们向SQ中下任务的数量要远远超过向RQ中下发任务的数量。为什么呢?请先回忆一下哪些操作类型会用到SQ,哪些又会用到RQ。
SEND/WRITE/READ都需要通信发起方向SQ中下发一个WR,而只有和SEND配合的RECV操作才需要通信响应方下发WR到RQ中。而我们又知道,SEND-RECV这一对操作通常都是用于传递控制信息,WRITE和READ才是进行大量远端内存读写操作时的主角,所以自然SQ的使用率是远远高于RQ的。
每个队列都是有实体的,占用着内存以及网卡的片上存储空间。在商用场景下,QP的数量是可能达到十万级甚至更高的,对内存容量提出了很高的要求,内存都是白花花的银子买的,SRQ就是IB协议为了节省用户的内存而设计的一种机制。
来看一下协议中对为什么要使用SRQ的官方解释(10.2.9.1章节):
Without SRQ, an RC, UC or UD Consumer must post the number of receive WRs necessary to handle incoming receives on a given QP. If the Consumer cannot predict the incoming rate on a given QP, because, for example, the connection has a bursty nature, the Consumer must either: post a sufficient number of RQ WRs to handle the highest incoming rate for each connection, or, for RC, let message flow control cause the remote sender to back off until local Consumer posts more WRs.
• Posting sufficient WRs on each QP to hold the possible incoming rate, wastes WQEs, and the associated Data Segments, when the Receive Queue is inactive. Furthermore, the HCA doesn’t provide a way of reclaiming these WQEs for use on other connections.
• Letting the RC message flow control cause the remote sender to back off can add unnecessary latencies, specially if the local Consumer is unaware that the RQ is starving.
简单来说,就是没有SRQ的情况下,因为RC/UC/UD的接收方不知道对端什么时候会发送过来多少数据,所以必须做好最坏的打算,做好突发性收到大量数据的准备,也就是向RQ中下发足量的的接收WQE;另外RC服务类型可以利用流控机制来反压发送方,也就是告诉对端”我这边RQ WQE不够了“,这样发送端就会暂时放缓或停止发送数据。
但是正如我们前文所说,第一种方法由于是为最坏情况准备的,大部分时候有大量的RQ WQE处于空闲状态未被使用,这对内存是一种极大地浪费;第二种方法虽然不用下发那么多RQ WQE了,但是流控是有代价的,即会增加通信时延。
而SRQ通过允许很多QP共享接收WQE(以及用于存放数据的内存空间)来解决了上面的问题。当任何一个QP收到消息后,硬件会从SRQ中取出一个WQE,根据其内容存放接收到的数据,然后硬件通过Completion Queue来返回接收任务的完成信息给对应的上层用户。
我们来看一下使用SRQ比使用普通的RQ可以节省多少内存[1]:
假设接受数据的节点上有N对QP,并且每个QP都可能在随机的时间收到连续的M个消息(每个消息都需要消耗一个RQ中的WQE),
- 如果不使用SRQ的话,用户一共需要下发N * M个RQ WQE。
- 如果使用SRQ的话,用户只需要下发K * M个RQ WQE,而K远小于N。
这个K是可以由用户根据业务来配置的,如果存在大量的并发接收的情况,那么就把K设置大一点,否则K设置成个位数就足够应付一般的情况了。
我们一共节省了(N - K) * M个RQ WQE,RQ WQE本身其实不是很大,大约在几个KB的样子,看起来好像占不了多少内存。但是如前文所说,实际上节省的还有用于存放数据的内存空间,这可是很大一块内存了,我们用图来说明:
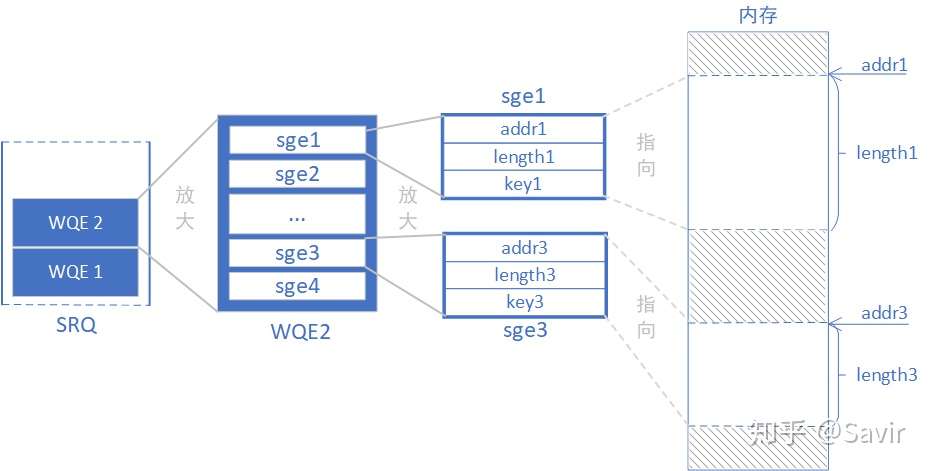
上图中的SRQ中有两个RQ WQE,我们看一下RQ WQE的内容,它们是由数个sge(Scatter/Gather Element)组成的,每个sge由一个内存地址,长度和秘钥组成。有了起始地址和长度,sge就可以指向一块连续的内存区域,那么多个sge就可以表示多个彼此离散的连续内存块,我们称多个sge为sgl(Scatter/Gather List)。sge在IB软件协议栈中随处可见(其实在整个Linux都很常见),可以用非常少的空间表示非常大的内存区域,IB的用户都使用sge来指定发送和接收区域的。
可以简单估算下每个sge可以指向多大的内存区域,length是一个32bit的无符号整型,可以表示4GB的空间。假设一个RQ WQE最大可以存放256个sge,那么一个RQ WQE一共就是1TB。当然实际上不可能这么大,这里只是想直观的告诉读者RQ WQE背后可能占用着多大的内存空间。
SRQC
即SRQ Context。同QPC一样,SRQC是用来告知硬件跟SRQ有关的属性的,包括深度、WQE大小等信息,本文不再赘述了。
SRQN
即SRQ Number。同QP一样,每个节点中可能存在多个SRQ,为了标识和区分这些SRQ,每个SRQ都有一个序号,称为SRQN。
SRQ的PD
我们在【7. Protection Domain】中介绍过Protection Domain的概念,它用来隔离不同的RDMA资源。每个SRQ都必须指定一个自己的PD,可以跟自己关联的QP的PD相同,也可以不同;SRQ之间也可以使用相同的PD。
如果在使用SRQ的时候,收到了数据包,那么只有在要访问的MR和SRQ处于同一个PD下,才会正常接收这个数据包,否则会产生立即错误。
异步事件
我们在【10. Completion Queue】一文中介绍过,IB协议根据错误的上报方式将错误类型分为立即错误,完成错误和异步错误。其中的异步错误类似于中断/事件,所以我们有时候也称其为异步事件。每个HCA都会注册一个事件处理函数专门用来处理异步事件,收到异步事件后,驱动程序会对其进行必要的处理和进一步上报给用户。
关于SRQ有一个特殊的异步事件,用来及时通知上层用户SRQ的状态,即SRQ Limit Reached事件。
SRQ Limit
SRQ可以设置一个水线/阈值,当队列中剩余的WQE数量小于水线时,这个SRQ会就上报一个异步事件。提醒用户“队列中的WQE快用完了,请下发更多WQE以防没有地方接收新的数据”。这个水线/阈值就被称为SRQ Limit,这个上报的事件就被称为SRQ Limit Reached。

因为SRQ是多个QP共享的,所以如果深度比较小的情况下,很有可能突然里面的WQE就用完了。所以协议设计了这种机制,来保证用户能够及时干预WQE不够的情况。
上报异步事件之后,SRQ Limit的值会被硬件重新设置为0(应该是为了防止一直上报异步事件给上层)。当然用户可以不使用这个机制,只需要将SRQ Limit的值设为0即可。
用户接口
控制面
还是老四样——“增、删、改、查”:
- 创建——Create SRQ
创建SRQ的时候,跟QP一样会申请所有SRQ相关的软硬件资源,比如驱动程序会申请SRQN,申请SRQC的空间并向其中填写配置。创建SRQ时还必须指定每个SRQ的深度(能存放多少WQE)以及每个WQE的最大sge数量。
- 销毁——Destroy SRQ
销毁SRQ的所有相关软硬件资源。
- 修改——Modify SRQ
除了SRQ深度等属性外,SRQ Limit的值也是通过这个接口设置的。因为每次产生SRQ Limit Reached事件之后,水线的值都会被清零,所以每次都需要用户调用Modify SRQ重新设置水线。
- 查询——Query SRQ
通常是用来查询水线的配置的。
数据面
Post SRQ Receive
跟Post Receive一样,就是向SRQ中下发接收WQE,里面包含了作为接收缓冲区的内存块的信息。需要注意的是,主语是SRQ,与QP没有任何关系,现在用户是不关心这个SRQ被哪些QP关联的。
SRQ和RQ的区别
从功能上来说,SRQ和RQ一样都是用来储存接收任务书的,但是由于SRQ的共享性,所以其和RQ有一些差异。
状态机
我们在【9. Queue Pair】中介绍过,QP有着复杂的状态机,不同的状态下QP的收发能力存在差异。而SRQ只有非错误和错误两种状态:
无论是哪种状态下,用户都可以向SRQ中下发WQE,但是在错误状态下,相关联的QP不能从这个SRQ中获得收到的数据。另外在错误状态下,用户也无法查询和修改SRQ的属性。
QP处于错误状态时,可以通过Modify QP来使其回到RESET状态,但是对SRQ来说,只能通过销毁它来退出错误状态。
接收流程
对于一个QP来说,RQ和SRQ不能同时使用,两者需选其一,如果对一个已经关联SRQ的QP的RQ下发WQE,那么会返回一个立即错误。
下面我们来对比看一下SRQ和RQ的接收流程。本小结的内容是本文的重点,相信读者看过之后,就对SRQ的机制有比较完整的了解了。
RQ的接收流程
首先,我们重温一下普通RQ的接收流程(结合发送端的完整流程请阅读【4. 操作类型】一文):
0. 创建QP。
- 通过Post Recv接口,用户分别向QP2和QP3的RQ下发接收WQE,WQE中包含接收到数据后放到哪块内存区域的信息。
2. 硬件收到数据。
3. 硬件发现是发给QP3的,那么从QP3的RQ中取出WQE1,将接收到的数据放到WQE1指定的内存区域。
4. 硬件完成数据存放后,向QP3的RQ关联的CQ3产生一个CQE,上报任务完成信息。
5. 用户从CQ3中取出WC(CQE),然后从指定内存区域取走数据。
6. 硬件收到数据。
7. 硬件发现是发送给QP2的,那么从QP2的RQ中取出WQE1,将接收到的数据放到WQE1指定的内存区域。
8. 硬件完成数据存放后,向QP2的RQ关联的CQ2产生一个CQE,上报任务完成信息。
9. 用户从CQ2中取出WC(CQE),然后从指定内存区域取走数据。
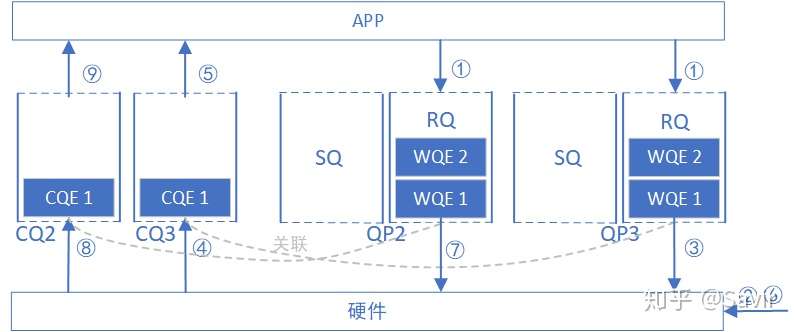
SRQ的接收流程
而SRQ的接收流程有一些区别:
0. 创建SRQ1,并创建QP2和QP3,都关联到SRQ1上。
- 通过Post SRQ Recv接口,用户向SRQ1中下发两个接收WQE,WQE中包含接收到数据后放到哪块内存区域的信息。
2. 硬件收到数据。
3. 硬件发现是发给QP3的,从SRQ1中取出第一个WQE(现在是WQE1),根据WQE内容存放收到的数据。
SRQ中的每个WQE是“无主的“,不关联到任何一个QP,硬件按队列顺序依次取出WQE就把数据放到里面了。
4. 硬件发现QP3的RQ关联的CQ是CQ3,所以向其中产生一个CQE。
5. 用户从CQ3中取出CQE,从指定内存区域取走数据。
细心地读者可能会问,用户下发WR时,每个WR都指定了一些未来用来存放数据的内存区域。但是SRQ是一个池子,里面每个WQE都指向了不同的若干段内存区域。用户收到某个QP对应的CQ中的WC后如何知道接收到的数据存放到哪里了呢?
WC中其实有wr_id信息,告知用户数据放到哪个WR(WQE)指定的内存区域了,既然WR是用户下发的,用户自然知道其指向的具体位置。
6. 硬件收到数据。
7. 硬件发现是发给QP2的,从SRQ1中取出第一个WQE(现在是WQE2),根据WQE内容存放收到的数据。
8. 硬件发现QP2的RQ关联的CQ是CQ2,所以向其中产生一个CQE。
9. 用户从CQ2中取出CQE,从指定内存区域取走数据。

总结
本文首先介绍了SRQ的基本概念,然后是其设计初衷、相关机制和用户接口,最后对比RQ描述了SRQ的接收流程。在实际业务中,SRQ的使用率还是蛮高的,希望读者能够深入理解。
就写到这里吧,感谢阅读。下一篇我将给大家介绍下Memeory Window。
协议相关章节
10.2.9 SRQ的设计思想以及相关操作
10.2.3 SRQ和QP的PD
10.8.2 关联SRQ的QP和不使用SRQ的QP的关系
10.8.5 SRQ相关的返回WC
11.5.2.4 异步事件
其他参考资料
[1] Linux Kernel Networking - Implement and Theory. Chapter 13. Shared Receive Queue