前言
上一篇对微服的演变、优缺点进行了概述,对于业务复杂项目,微服务算是比较合适的解决方案;对于咱们开发者来说,有好的解决方案肯定要跟进学习,但不能盲目追崇流行技术,目的还是为了解决问题。这里就把Asp.NetCore落地微服务架构技术栈汇总一下(当然不限于此),同时制定了个学习分享计划,和小伙们一起共勉;

正文
将涉及的技术栈将其分为如下几个阶段进行归类,后续学习分享的大方向也是如此:
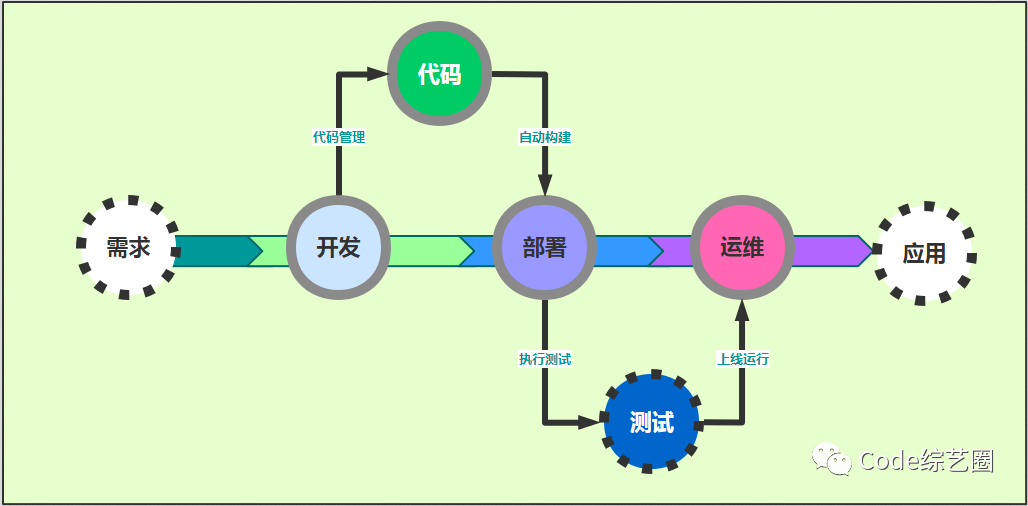
对于需求阶段业务分析、测试阶段相关及最后应用阶段的服务,这系列暂时就先不涉及,而是主要针对开发技术、代码管理、应用部署、运维管理方面的技术进行汇总和学习分享;对于上图的各个阶段,可能在很多大公司将其职责的划分很清晰,但对接避免不了(DevOps),所以了解和学习是很有必要的;如果是中小型公司,那可能开发是你、部署是你、运维还是你,技多不压身,来了就干,不服就来学。
注:不是在项目中使用以下提到的技术就是微服务,而微服务指的是业务之微,技术只是对其进行落地实现;
开发阶段
对于实现,在开发阶段涉及的组件或框架颇多,所以得花更多时间进行学习和实战,如下:
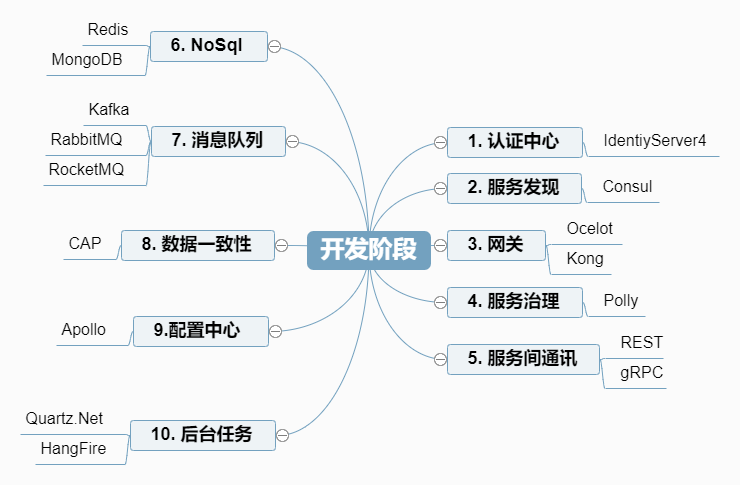
认证中心
当划分的服务增多时,单个服务的认证和授权显得更加冗余,更希望有一个统一的认证站点,每一个服务的认证都由认证中心站点进行认证和授权;咱们可以从零自己实现OAuth 2.0和OIDC提供授权和认证功能,轮子肯定有人造好了,拿来就用多好,IdentityServer 4将授权和认证都有很好的实现,从而使得开发人员有更多的时间关注在业务开发上。
服务发现
当服务不多的时候,可能手动进行API地址配置,实现调用还可以接受配置复杂性,如果是对服务增加服务器扩展时,还得手动进行配置,那干这活的肯定要喷脏话了。如果使用Consul做服务发现,自动发现各个服务,同时还能进行健康检查,及时过滤掉不可用服务,增强高可用,显得更加智能化;减少人工配置的复杂性,还能提升服务的高可用。
网关(Gateway)
网关的主要作用是进行路由转换、统一入口、隔离内网等,当然还可以做一些服务熔断、限流、重试、缓存等相关功能。功能具体是什么意思,怎么实现我们在做学习分享的时候会一一说到。而.NetCore中常用的网关为Ocelot和Kong;
- 路由转换:根据配置规则,将不同业务地址转换到对应的微服务地址上,让业务请求由对应的业务API进行处理;
- 统一入口:对于UI界面而言,只关心一个入口,即网关地址,不用和每个微服务直接打交道,降低请求访问复杂性;
- 隔离内网:对外提供地址为网关地址,内部服务通信都是通过内网,使得站点安全性增强;
- 其他功能会在后续实操中一一说到;
服务间通讯
虽然拆分成了各个小服务,但始终还是一个系统,对于一些业务依赖关系的服务会进行聚合或是通过服务间通信,将数据整合统一返回给UI层;常用的技术手段是通过Restful Api接口或是gRPC进行数据交互,然后再进行数据业务处理。
服务治理
每一个小服务也是一个程序,就有可能出现Bug、网络通信异常、服务器宕机等情况而导致服务不可用,通常我们理想状态肯定是希望其他服务不被异常服务影响,这样就需要对服务进行治理,比如失败重试、服务熔断、失败降级等,从而提升服务的可用性,避免单个异常服务导致整个系统雪崩的现象;.NetCore中会使用Polly库实现相关功能。
NoSql-非关系型数据库
通常的高并发场景下需要进行缓存和数据共享,实现高可用,而目前Redis是一个很不错的选择。对于一些文档型数据,MongoDB存储更有优势,当有大量数据时,会有一些列存储的数据;对于搜索实现,ElasticSearch存储实现会更加符合场景;
消息队列
消息队列的三大好处:异步处理、解耦、削峰;通常在微服务系统业务处理中,遇到一些复杂业务,需要耗费较长的时间,这样给用户体验就不太友好,咱们可以将涉及相关业务通过消息队列分发给不同服务处理,然后及时响应给用户,业务后台异步处理,体验感觉就不一样;可能有小伙伴还会说,直接多线程不就得了,如果是这样的话,那业务可能都耦合在一块,后期维护又是一个很大问题;对于一些高并发系统,估计平时服务器都能承载请求,但是存在某一时间段高峰访问,如果请求都打到后台服务数据库,数据库可能抗不住,像这种短时段高峰的情况,可以通过消息队列进行削峰,避免高峰时刻搞崩系统;目前比较常用的消息队列有:Kafka、RocketMQ、RabbitMQ。
CAP
微服务就是分布式,既然是分布式,那分布式事务就避免不了,最终数据一致性的问题那得解决;对于分布式来说,这是老生常谈的问题了,并且提供了相关的解决方案,而在.Net中,有大神就封装了CAP,并将其开源,配合消息队列很好的实现了分布式事务控制;
Apollo
试想,如果每个服务都有一套自己的配置文件,那部署和运维是不是很头痛,而且对于一些公共配置数据也会重复在每个服务中配置使用,如果有一套统一的配置中心是不是感觉非常良好,所有服务的配置数据通过一个点进行维护和使用,不管在开发维护、部署还是运维方面,都带来便捷性;可以自己实现,也可以使用第三方的,而Apollo现在相对来说是比较火的,也有一些直接使用Consul扮演配置中心的角色;当然还有使用在K8S自带的配置中心。
后台任务
既然用到微服务项目,应该数据量也不会小,通常会做一些报表分析,数据同步等操作,而这种耗时操作不希望在业务高峰时期执行,需要在空闲时间定时操作即可,针对这种场景后台定时任务就有用武之地啦。当然不仅仅是这种场景,还有一些做业务数据重放或修复,比如一个订单在操作中异步处理失败了,可以在后台任务检查过程中,进行再次处理等;在.Net中用的相对比较多的是Quartz.Net和Hangfire。
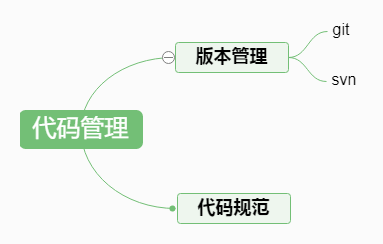
代码管理
代码应该不用多说了,小伙伴们应该都摸清门路了,简单画个图,如下:
代码规范
不管什么架构,代码规范一直是开发者严格要求的,开发过程中得有良好的编码规范,虽然每一个公司的要求不太一样,但最终的目的是一致的:规范化,这样在后期维护就不会花费大量的时间去研究代码为什么要这么写。为了规范,周期性的Code Review是必不可少的。
代码版本管理
对于代码版本管理工具,用的最多应该是git和svn了,其中对于分支的管理是非常重要的,比如临时修复线上Bug怎么办,常规开发怎么办,紧急功能开发又怎么划分处理,好的规划代码分支不会让代码版本混乱,从而引起功能的不完整或异常; 别小看这一件事,经常因为版本分支问题导致生产功能出问题的事件比比皆是,当然不会单独为其做一个文章讲解,但会在集成部署那块会提到;因为持续集成离不开代码的管理;
部署
提到部署,可能有的小伙伴会说,这不是运维搞的吗,或者说这不应该有专门的人搞吗?是的,理想是这样的,但事实就是,小伙伴不仅负责开发,还得要部署,对于职责分明的团队,至少你也得会,不然对接有一大堆的尴尬。
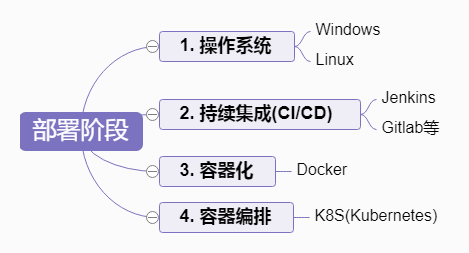
操作系统
现在部署更多的是推荐在Linux上了,像Redis、ES、nginx等都是在Linux中发挥更好的性能,而对于Linux估计有些小伙伴还不熟,甚至只是听说,还没操作,不说多的,关于开发和部署相关日常操作到时候我们来一起聊聊,高深操作可以抽时间再去研究。当然,Windows的操作到时候也能提到,毕竟现在Windows服务器也没有说不用。
持续集成(CI/CD)
老式的手动发布和部署在微服务中显得力不从心了,那么多服务,做重复操作,换做任何一个人也受不了,如果多发几次迭代,那这人就别干其他活,就负责发布妥了。 想想,如果这些事自动化解决岂不完美,而Jenkins搭配代码管理软件就能很好的实现,自动拉取代码->自动构建->自动部署,代码管理软件可以自己搭建,比如Gogs,或者使用gitlab、github等都行。通过监听代码的提交,就能自动完成,想想都美。
容器化
开发和运维干架啦,一个说在我这行,一个说在我那不行, 别说那么多,先干架再说;哈哈哈,为了不允许这种事发生,容器化显得很屌,开发发布打包生成镜像,运维拉下来就直接跑,啥都一样,还有的说吗;其实主要的目的还是提升工作效率啊,现如今Docker是火的旺旺的,但K8S的弃用能否让它走下坡路,这似乎好像不太好说;
容器编排
当容器集群扩展增多时,就得有一个东西进行管理,否则扩展会显得超级麻烦,而K8S就很吃香,针对容器集群管理更好的自动伸缩、自动部署,还能搭配探针实现自修复;
运维
功能开发完了、代码也上传了、站点也部署了,用户开始用吧,后续就很轻松了;no,no,no,这才开始,应该很少有小伙伴拍着胸脯说,没事,我做的功能都没问题,绝对没Bug,好,先假设开发没问题,断电、宕机、断网咋整,这种物理问题不能避免吧,不管是做异地多活也好,还是有其他方案,至少得去弄吧; 那如果是业务问题呢,排查问题更多的是靠日志了,对于微服务这种架构,有一个调用链的追踪会提供很好的辅助,来,先看看需要什么技术工具:
日志分析
之前单体架构,登上服务器,拷贝日志下来分析妥了,而对于微服务,这似乎不太可取,拷贝日志不仅麻烦还耗时。如果使用Exceptionless将日志统一收集在一起,是不是稍微好那么一点,再加上做一个ElasticSearch和Kibana的查询分析,是不是又加快了问题的分析速度。
链路追踪
微服务间的数据交互肯定避免不了,有一个可视化的调用链路及监控就显得更加直观,清楚的看到每次接口调用经过的服务点,对于定位问题来说也提供很大的帮助,能快速知道这次异常经过哪些服务处理,缩小范围。而用的相对比较多的是SkyWalking和Butterfly。
分布式监控系统
微服务情况下,只要一发布,就不知道什么情况,这样只有在问题发生之后,才能去排查;有没有一个监控系统,对系统和服务运行环境进行监控,能在危险范围内的时候提前给个告警,及时通知相关人员处理呢,prometheus搭配Grafana能将监控数据友好的展示和配置,从而实现对服务运行环境的监控。
总结
对于微服务,还是开篇说到的,不是使用以上技术就是微服务架构,而服务的划分更多是通过业务进行划分,技术只是帮助其落地;
以上针对于各阶段的技术栈汇总并不涵盖全部,仅仅是当下相对比较火,且周围朋友用的比较多的,有什么好的技术,小伙伴可以分享。
这个战线拉的很长,但肯定会坚持学习分享。 期间把Redis系列分享完之后,还会穿插数据库优化系列的文章。
一个被程序搞丑的帅小伙,关注"Code综艺圈",跟我一起学~
