1.前言
Mysql的数据类型往往很重要,因为它对于DBA开发或者运维人员在开始设置表结构的时候往往会起到关键性作用,只要了解了它的数据类型之后,我们再创建表的时候就会找到最符合该表的最佳的数据类型了。
2.Mysql数据类型之数值类型( tinyint、smallint、mediumint、int、bigint、float、double、dec(M,D)、decimal(M,D)、bit(M) )
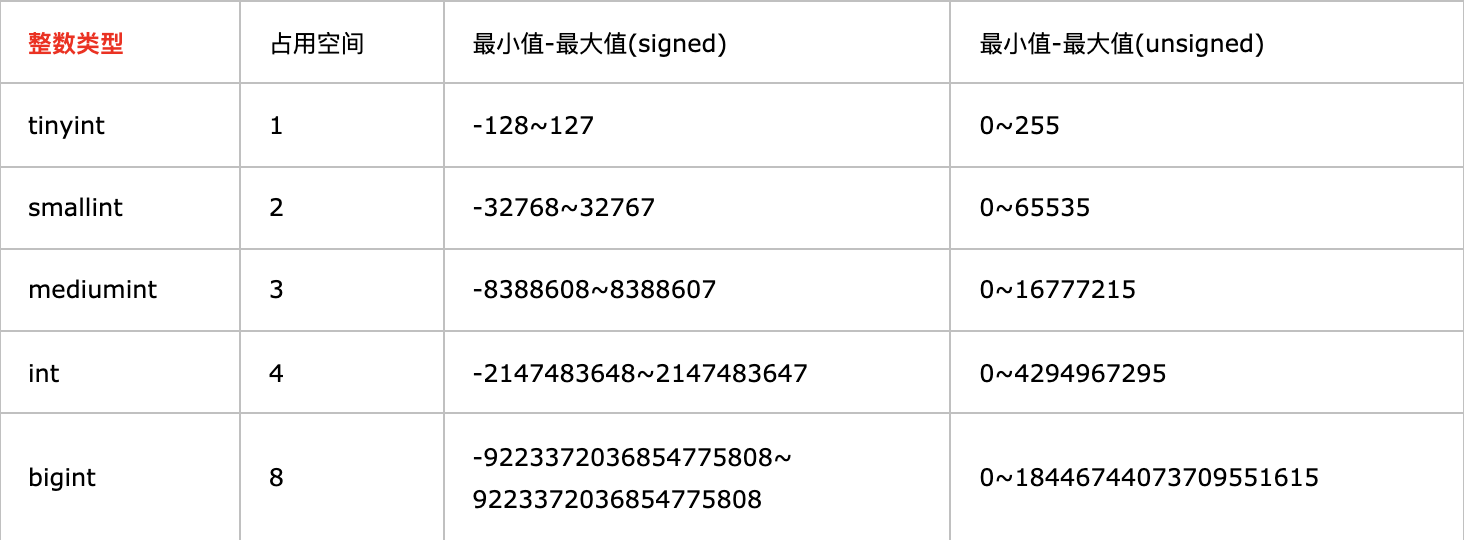



(M,D) :其中M显示的是M位数字(整数位+小数位),D表示小数位的位数。
- 上面主要介绍了几种数字类型所占用的空间,以及signed和unsigned的最大值和最小值(计算方法:如果占用一个一节,表示2的8次方=256,后面以此类推)。
- 其中signed表示有符号(正负),unsigned表示无符号(只有正号,无负号)。这里根据建议选用signed,不建议使用unsigned。
- 自增整型类型做主键,务必使用类型 BIGINT,而非 INT,后期表结构调整代价巨大;
- MySQL 8.0 版本前,自增整型会有回溯问题,做业务开发的你一定要了解这个问题
- 当达到自增整型类型的上限值时,再次自增插入,MySQL 数据库会报重复错误;
3.Mysql数据类型之字符串类型(char、varchar、binary、blob、text、enum、set)

- CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,请牢记,N 表示的是字符,而不是字节。VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字符。
- 在超出 65536 个字符的情况下,可以考虑使用更大的字符类型 TEXT 或 BLOB,两者最大存储长度为 4G,其区别是 BLOB 没有字符集属性,纯属二进制存储。
- 和 Oracle、Microsoft SQL Server 等传统关系型数据库不同的是,MySQL 数据库的 VARCHAR 字符类型,最大能够存储 65536 个字符,所以在 MySQL 数据库下,绝大部分场景使用类型 VARCHAR 就足够了。
字符集:
在表结构设计中,除了将列定义为 CHAR 和 VARCHAR 用以存储字符以外,还需要额外定义字符对应的字符集,因为每种字符在不同字符集编码下,对应着不同的二进制值。常见的字符集有 GBK、UTF8,通常推荐把默认字符集设置为 UTF8。
而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E。
包括 MySQL 8.0 版本在内,字符集默认设置成 UTF8MB4,8.0 版本之前默认的字符集为 Latin1。因为不同版本默认字符集的不同,你要显式地在配置文件中进行相关参数的配置:
[mysqld] character-set-server = utf8mb4 ...
另外,不同的字符集,CHAR(N)、VARCHAR(N) 对应最长的字节也不相同。比如 GBK 字符集,1 个字符最大存储 2 个字节,UTF8字符集 1 个字符最大存储 3个字节,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储内核看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储.
其中查看当前Mysql支持的字符集的字符集默认的排序规则可以用命令:-->show charset ;
修改字符集:
ALTER TABLE emoji_test CHARSET utf8mb4;
##上述修改只是将表的字符集修改为 UTF8MB4,下次新增列时,若不显式地指定字符集,新列的字符集会变更为 UTF8MB4,但对于已经存在的列,其默认字符集并不做修改
因此,你可以通过如下方法进行修改:
mysql> SHOW CREATE TABLE emoji_testG *************************** 1. row *************************** Table: emoji_test Create Table: CREATE TABLE `emoji_test` ( `a` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`a`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec) -------------------------------------------------------------------------------------------------------------------------- 可以看到,列 a 的字符集依然是 UTF8,而不是 UTF8MB4。因此,正确修改列字符集的命令应该使用 ALTER TABLE ... CONVERT TO...这样才能将之前的列 a 字符集从 UTF8 修改为 UTF8MB4: mysql> ALTER TABLE emoji_test CONVERT TO CHARSET utf8mb4; Query OK, 0 rows affected (0.94 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> SHOW CREATE TABLE emoji_testG *************************** 1. row *************************** Table: emoji_test Create Table: CREATE TABLE `emoji_test` ( `a` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL, PRIMARY KEY (`a`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)
排序规则:
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,你可以用命令 SHOW CHARSET 来查看:
mysql> SHOW CHARSET LIKE 'utf8%'; +---------+---------------+--------------------+--------+ | Charset | Description | Default collation | Maxlen | +---------+---------------+--------------------+--------+ | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 | +---------+---------------+--------------------+--------+ 2 rows in set (0.01 sec) mysql> SHOW COLLATION LIKE 'utf8mb4%'; +----------------------------+---------+-----+---------+----------+---------+---------------+ | Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute | +----------------------------+---------+-----+---------+----------+---------+---------------+ | utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD | | utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD | | utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD | | utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD | | utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE | ......
排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。需要注意的是,比较 MySQL 字符串,默认采用不区分大小的排序规则
绝大部分业务的表结构设计无须设置排序规则为大小写敏感!除非你能明白你的业务真正需要。
枚举类型(ENum)
通常我们在表设计中遇到性别设计的时候,通过会把该字段类型设置为ENum类型。但是也有会有很多程序开发者喜欢将它设置我tinyint类型,但是这样的有一些缺陷:
-
表达不清:在具体存储时,0 表示女,还是 1 表示女呢?每个业务可能有不同的潜规则;
-
脏数据:因为是 tinyint,因此除了 0 和 1,用户完全可以插入 2、3、4 这样的数值,最终表中存在无效数据的可能,后期再进行清理,代价就非常大了。
在 MySQL 8.0 版本之前,可以使用 ENUM 字符串枚举类型,只允许有限的定义值插入。如果将参数 SQL_MODE 设置为严格模式,插入非定义数据就会报错:
mysql> SHOW CREATE TABLE UserG *************************** 1. row *************************** Table: User Create Table: CREATE TABLE `User` ( `id` bigint NOT NULL AUTO_INCREMENT, `sex` enum('M','F') COLLATE utf8mb4_general_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB 1 row in set (0.00 sec) mysql> SET sql_mode = 'STRICT_TRANS_TABLES'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> INSERT INTO User VALUES (NULL,'F'); Query OK, 1 row affected (0.08 sec) mysql> INSERT INTO User VALUES (NULL,'A'); ERROR 1265 (01000): Data truncated for column 'sex' at row 1
由于类型 ENUM 并非 SQL 标准的数据类型,而是 MySQL 所独有的一种字符串类型。抛出的错误提示也并不直观,这样的实现总有一些遗憾,主要是因为MySQL 8.0 之前的版本并没有提供约束功能。自 MySQL 8.0.16 版本开始,数据库原生提供 CHECK 约束功能,可以方便地进行有限状态列类型的设计:
mysql> SHOW CREATE TABLE UserG *************************** 1. row *************************** Table: User Create Table: CREATE TABLE `User` ( `id` bigint NOT NULL AUTO_INCREMENT, `sex` char(1) COLLATE utf8mb4_general_ci DEFAULT NULL, PRIMARY KEY (`id`), CONSTRAINT `user_chk_1` CHECK (((`sex` = _utf8mb4'M') or (`sex` = _utf8mb4'F'))) ###这一行是约束条件。。。 ) ENGINE=InnoDB 1 row in set (0.00 sec) mysql> INSERT INTO User VALUES (NULL,'M'); Query OK, 1 row affected (0.07 sec) mysql> INSERT INTO User VALUES (NULL,'Z'); ERROR 3819 (HY000): Check constraint 'user_chk_1' is violated. ##不符合条件时就会报错。。。
4.Mysql数据类型之日期时间类型(date、datetime、timestamp、time、year)
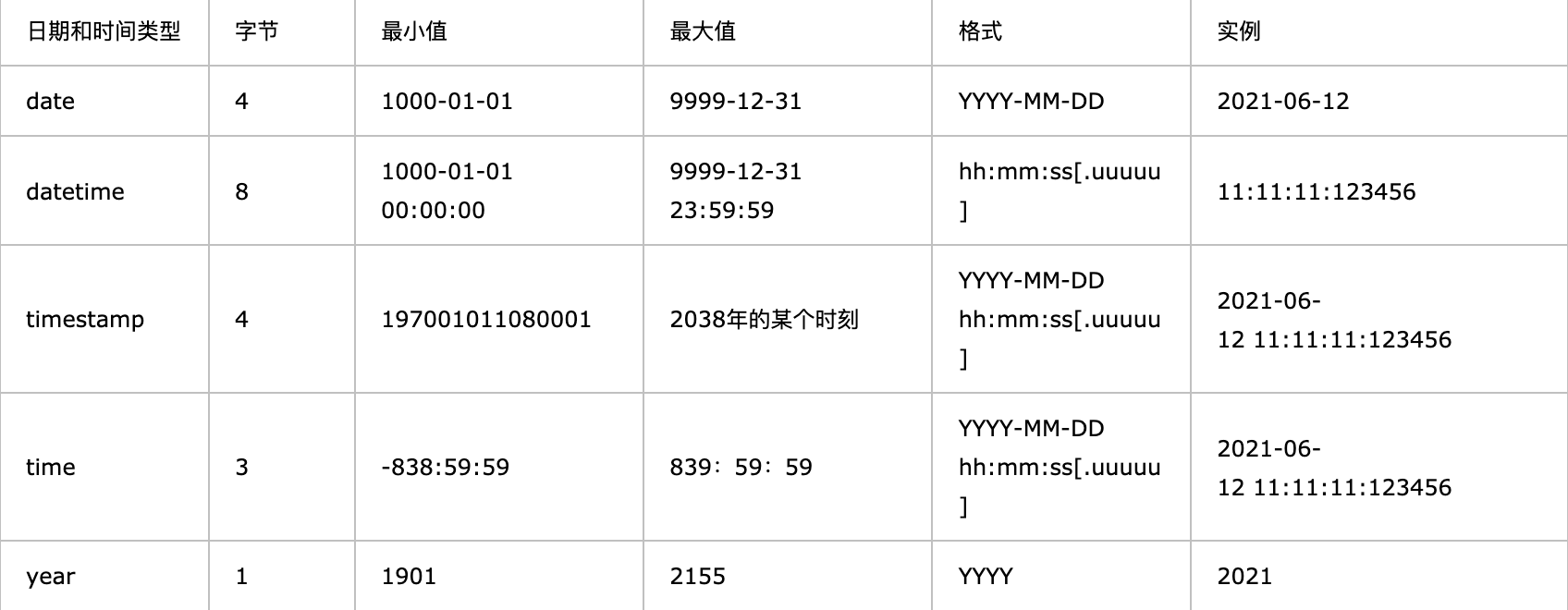
- 如果要用来表示年月日,通常用date来表示
- 如果要用来表示年月日时分秒,通常用datetime或者timestamp表示
- 如果只用来表示时分秒,通常用time来表示
- 如果只是表示年份的,可以用year来表示。
date、time 、datetime的区别如下:
root@localhost 14:59: > create table t4(d date,t time,dt datetime); Query OK, 0 rows affected (0.02 sec) root@localhost 15:00: > insert into t4 values(now(),now(),now()); Query OK, 1 row affected, 1 warning (0.01 sec) root@localhost 15:00: > select * from t4; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2021-06-12 | 15:00:44 | 2021-06-12 15:00:44 | +------------+----------+---------------------+
从 MySQL 5.6 版本开始,DATETIME 类型支持毫秒,DATETIME(N) 中的 N 表示毫秒的精度。例如,DATETIME(6) 表示可以存储 6 位的毫秒值。同时,一些日期函数也支持精确到毫秒,例如常见的函数 NOW、SYSDATE:
Timestamp
首先查看参数explicit_defaults_for_timestamp的设置:
root@localhost 15:03: [liulin]> show variables like '%explicit%'; +---------------------------------+-------+ | Variable_name | Value | +---------------------------------+-------+ | explicit_defaults_for_timestamp | OFF | +---------------------------------+-------+
##这个参数是默认关闭的。
root@localhost 15:02: [liulin]> create table t5 (id1 timestamp); Query OK, 0 rows affected (0.01 sec) root@localhost 15:03: [liulin]> desc t5; +-------+-----------+------+-----+-------------------+-----------------------------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------+------+-----+-------------------+-----------------------------+ | id1 | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +-------+-----------+------+-----+-------------------+-----------------------------+
当默认关闭此参数时此处可以发现,系统给tm自动创建了默认值current_timestamp(系统日期),并且设置了not null和on update current_timestamp属性。
此外:如果将explicit_defaults_for_timestamp设置为on,则默认值、not null和on current_timpstamp 都不会自动设置,需要手工操作。
Datetime VS Timestamp
- TIMESTEMP 存储日期,因为类型 TIMESTAMP 占用 4 个字节,比 DATETIME 小一半的存储空间,Datetime占用8个字节
- 从5.6版本起,若带有毫秒时,类型 TIMESTAMP 占用 7 个字节,而 DATETIME 无论是否存储毫秒信息,都占用 8 个字节。
Timestamp的优点与缺点:
- 优点:TIMESTAMP 最大的优点是可以带有时区属性,因为它本质上是从毫秒转化而来。如果你的业务需要对应不同的国家时区,那么类型 TIMESTAMP 是一种不错的选择。比如新闻类的业务,通常用户想知道这篇新闻发布时对应的自己国家时间,那么 TIMESTAMP 是一种选择。
这时通过设定不同的 time_zone,可以观察到不同时区下的注册时间:
mysql> SELECT name,regist er_date FROM User WHERE name = 'David'; +-------+----------------------------+ | name | register_date | +-------+----------------------------+ | David | 2018-09-14 18:28:33.898593 | +-------+----------------------------+ 1 row in set (0.00 sec) mysql> SET time_zone = '-08:00'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT name,register_date FROM User WHERE name = 'David'; +-------+----------------------------+ | name | register_date | +-------+----------------------------+ | David | 2018-09-14 02:28:33.898593 | +-------+----------------------------+ 1 row in set (0.00 sec)
##以上可以看到设置了时区time_zone后发现插入的时间自动递减或递增。
这里也可以直接设置时区的名字,中国的时区是 +08:00,美国的时区是 -08:00,因此改为美国时区后,可以看到用户注册时间比之前延迟了 16 个小时。当然了,直接加减时区并不直观,需要非常熟悉各国的时区表:
mysql> SET time_zone = 'America/Los_Angeles'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT NOW(); +---------------------+ | NOW() | +---------------------+ | 2020-09-14 20:12:49 | +---------------------+ 1 row in set (0.00 sec) mysql> SET time_zone = 'Asia/Shanghai'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT NOW(); +---------------------+ | NOW() | +---------------------+ | 2020-09-15 11:12:55 | +---------------------+ 1 row in set (0.00 sec)
- 缺点:时限问题:TIMESTAMP 的上限值 2038 年很快就会到来,那时业务又将面临一次类似千年虫的问题
性能问题:虽然从毫秒数转换到类型 TIMESTAMP 本身需要的 CPU 指令并不多,这并不会带来直接的性能问题。但是如果使用默认的操作系统时区,则每次通过时区计算时间时,要调用操作系统底层系统函数 __tz_convert(),而这个函数需要额外的加锁操作,以确保这时操作系统时区没有修改。所以,当大规模并发访问时,由于热点资源竞争,会产生两个问题。
-
-
-
性能不如 DATETIME: DATETIME 不存在时区转化问题。
-
性能抖动: 海量并发时,存在性能抖动问题。
-
-
为了优化 TIMESTAMP 的使用,强烈建议你使用显式的时区,而不是操作系统时区。比如在配置文件中显示地设置时区,而不要使用系统时区:
[mysqld] time_zone = "+08:00"
最后,通过命令 mysqlslap 来测试 TIMESTAMP、DATETIME 的性能,命令如下:
# 比较time_zone为System和Asia/Shanghai的性能对比 mysqlslap -uroot --number-of-queries=1000000 --concurrency=100 --query='SELECT NOW()'
结果如下:

这里姜老师的提高了45%,我这里只是提高了12%,我猜测估计我这个是虚拟机,硬件资源太low, 导致性能提升不大!
因此,建议推荐日期类型使用 DATETIME,而不是 TIMESTAMP。
其次,在做表结构设计规范时,强烈建议你每张业务核心表都增加一个 DATETIME 类型的 last_modify_date 字段,并设置修改自动更新机制, 即便标识每条记录最后修改的时间:
CREATE TABLE User ( id BIGINT NOT NULL AUTO_INCREMENT, name VARCHAR(255) NOT NULL, sex CHAR(1) NOT NULL, password VARCHAR(1024) NOT NULL, money INT NOT NULL DEFAULT 0, register_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6), last_modify_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6), CHECK (sex = 'M' OR sex = 'F'), PRIMARY KEY(id) );
通过字段 last_modify_date 定义的 ON UPDATE CURRENT_TIMESTAMP(6),那么每次这条记录,则都会自动更新 last_modify_date 为当前时间。
这样设计的好处是: 用户可以知道每个用户最近一次记录更新的时间,以便做后续的处理。比如在电商的订单表中,可以方便对支付超时的订单做处理;在金融业务中,可以根据用户资金最后的修改时间做相应的资金核对等。