select * from user into outfile '/tmp/user.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by ' ';
####参数说明
into outfile '导出的目录和文件名'
执行导出的目录和文件名
fields terminated by '字段间分隔符'
定义字段间的分隔符
optionally enclosed by '字段包围符'
定义包围字段的字符(数值型字段无效)
lines terminated by '行间分隔符'
定义每行的分隔符
1.介绍:
1.搭建主从复制 ***
2.主从原理熟悉 *****
3.主从的故障处理 ******
4.主从延时 ******
4.主从的特殊架构的配置和使用
5.主从架构的演变
2. 主从复制的介绍
(1)主从复制基于binlog来实现的
(2)主库发生新的操作,都会记录binlog
(3)从库取得主库的binlog 进行回放
(4)主从复制是异步方式进行的
3.主从复制的前提(搭建主从复制)
(1)2个或以上的数据库实例
(2)主库需要要开启二进制日志
(3)server_id 要不同,要区分不同的节点
(4)主库需要建立专用的复制用户
(5)告诉主库,谁是主库,怎么连接? 人为告诉从库一些复制信息(ip ,port , user, 二进制起点位置)
(6)从库应该开启专门的复制线程, 线程(三个) : Dump_thread IO_thread SQL_thread
4. 主从复制搭建过程(生产)
4.1 准备多实例:略
4.2 主库检查二级制日志是否开启和server_id也要不同
4.3 主库创建复制用户
grant replication slave on *.* to repl@'172.19.94.%' identified by '123';
4.4 备份主库
mysqldump -uroot -p123 -A -R -E --triggers --single-transaction --master-data=2 --set-gtid-purged=on >/tmp/full.sql
4.5 把主库的数据恢复到从库上
登录从库
source /tmp/full.sql ;
或者:mysql -uroot -p123 -S /data/mysql.sock </tmp/full.sql
4.6 开始开启主从复制
登录从库
help change master to # 查看帮助信息 CHANGE MASTER TO MASTER_HOST='172.17.94.207', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3307, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154, MASTER_CONNECT_RETRY=10; 或者开了GTID后: change master to master_host='172.17.94.207', master_user='repl', master_password='123' , MASTER_PORT=3307 MASTER_AUTO_POSITION=1;
4.7 开启复制线程
从库中:执行 start slave;
4.8 检查主从复制状态
show slave status;
4.9 如果有报错
1 先停掉从库:stop slave
2. 再重置从库:reset slave all;
5.主从复制原理
主库: binlog (binlog_dump Thread :主库中所用到的线程)
从库:relaylog:中继日志 master.info :主库信息文件 relaylog.info: relaylog 应用信息 (Slave_Io Thread Slave_SQL Thread :这是从库所用到的两个线程)
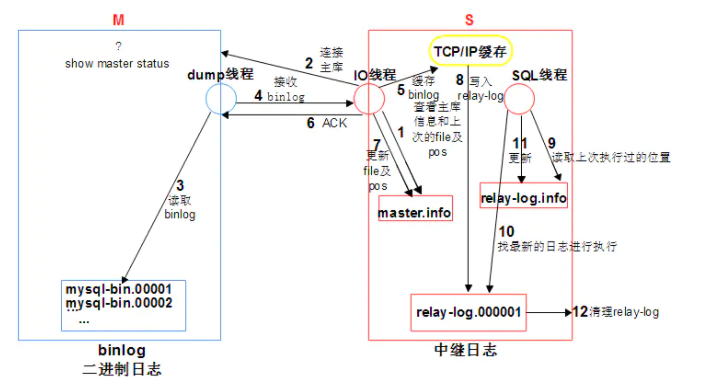
主从复制原理
过程解释:
1.从库执行change master to 命令(主库的连接信息+复制的起点) 2.从库会通过以上信息,记录到master.info 文件 3.从库执行start slave 命令,立即开启IO_T 和SQL_T 4.从库IO_T,读取master.info 文件中的信息获取到Ip,PORT,User,Pass,binlog的位置信息 5.从库IO_T请求连接主库,主库专门提供一个DUMP_T,负责和IO_T交互 6.IO_T根据binlog的位置信息(mysql-bin.00001,888),请求主库更新binlog 7.主库通过DUMP_T将最新的binlog,通过网路TP给从库的IO_T 8 IO_T接受到新的binlog日志,存储到TCP/IP 缓存,立即返回ACK给主库,并更新master.info 9.IO_T将TCP/IP缓存中数据,转储到磁盘relaylog中 10.SQL_T读取relay.info 中的信息,获取到上次已经应用过的relaylog的位置信息 11.sql_T会按照上次的位置点回放最新的relaylog,再次更新relay.info 信息 12.从库会自动purge应用relay进行定期清理 补充说明: 一旦主从复制构建成功,主库当中发生了新的变化,都会通过dump_T发送信号给IO_T,增强了主从复制的实时性。
这里可以在主机上面查看连接的从机信息(补充)
root@localhost:(none)>show slave hosts; +-----------+------+------+-----------+--------------------------------------+ | Server_id | Host | Port | Master_id | Slave_UUID | +-----------+------+------+-----------+--------------------------------------+ | 57 | | 3307 | 47 | 9c9c6940-72e0-11eb-b5ab-000c29adaa80 | +-----------+------+------+-----------+--------------------------------------+
这里还应该显示从库的host的ip地址
6.主从复制监控
命令: show slave statusG; 主库信息 Slave_IO_State: Waiting for master to send event Master_Host: 172.17.94.207 Master_User: repl Master_Port: 3307 Connect_Retry: 10 #重点是看这两个信息 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 628 #从库relay应用信息有关的(relay.info) Read_Master_Log_Pos: 628 Relay_Log_File: node03-relay-bin.000002 Relay_Log_Pos: 794 Relay_Master_Log_File: mysql-bin.000001 #线程判断是否有故障(排错用到的信息) Slave_IO_Running: Yes Slave_SQL_Running: Yes Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: #和过滤复制有关的信息 Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: #从库延时主库的时间(秒) Seconds_Behind_Master: 0 #延时从库(人为) 防止人为的误操作 SQL_Delay: 0 SQL_Remaining_Delay: NULL #与Gtid复制有关的状态信息 Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version:
7 主从复制故障分析
情况1
从库: IO线程故障
连接主库:connecting
网络:连接信息错误或者变更了,防火墙,连接数上限了
如果是以上情况,我们可以尝试一下能否可以使用复制账户在从库连接主库登录
解决方式:重置主从复制: stop slave ; reset slave all ; change master to ... ; start slave ;
情况2:
如果是binlog日志没开或者是损坏
我们需要在配置文件中开启binlog日志,然后在重置一下主库:reset master 这个命令是重新同步主库的binlog日志的日志位置信息
情况3:
如果是SQL线程故障
有如下原因导致:
1,版本差异,参数设定不同,比如:数据类型的差异,SQL_MODE影响
2. 要创建的数据库对象已经存在 这个很常见
3. 要删除或修改的对象不存在
4. DML 语句不符合表定义及约束时
归根接地的原因都是由于人为操作的失误
处理方法: 把握一个原则,一切以主库为准进行解决
如果出现问题,尽量进行反操作
最稳妥的办法就是重新构建主从
方法一:
stop slave;
set global sql_slave_skip_counter=1; # 将同步指针向移动一个,如果多次不同步,可以重复操作
start slave;
方法二:
/etc/my.cnf slave-skip-errors = 1032,1062,1007 ###表示跳过这几个错误 常见错误代码: 1007:对象已存在 1032:无法执行DML 1062:主键冲突,或约束冲突
上面的方式虽然可以解决问题,但是有时操作是有风险的,最安全的做法是重新构造主从复制
如果碰到主键冲突:
这时需要我们采用方式一 来跳过这个错误
所以为了很大程度的避免SQL线程故障
(1) 从库设置只读
read_only:
super_read_only;
(2)使用读写分离中间件
atlas mycat proxysql maxscale 等等
8 主从延时监控分析
8.0 主库方面原因
(1)主库binlog写入不及时 解决: 双一 调参 sync_binlog=1
(2) 默认情况下dump_t 是串行传输binlog
在并发事务量大的时候或大事务,有dump_t是串行工作的,导致传送日志较慢
如何解决这个问题?
必须使用GTID,使用Group commit方式,可以支持DUMP_T并行
(3)主库极其繁忙
慢查询
锁等待
从库太多
8.1 从库方面原因
(1)传统复制中
如果主库开发事务量很大,或者出现大事务
由于从库是单SQL线程,导致不管传的日志有多少,只能一次执行一个事务
5.6版本,有了GTID,可以实现多SQL线程,但是只能基于不同库的事务进行回放,(database)
5.7版本中,有了增强的GTID,增加了seq_no,增加了新型的并发SQL线程模式,logical_clock ,针对事务的并发 MTS技术
(2)主从硬件差异太大
(3)主从的参数配置
(4)从库和主库的索引不一致
1.主库方面原因的监控 主库: -->show master status G; ------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 628 | | | | +------------------+----------+--------------+------------------+-------------------+ 从库: -->show slave statusG; Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 628 2.从库方面的监控 看从库从主库拿了多少 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 628 执行了多少 Relay_Log_File: node03-relay-bin.000002 Relay_Log_Pos: 794 Exec_Master_Log_Pos: 628 Relay_Log_Space: 1002
==============================
进阶:
8.0 配置延时
SQL线程延时:数据已经写入relaylog中了,SQL线程"慢点"运行 一般企业建议3-6小时,具体看公司运维人员对于故障的反应时间 mysql>stop slave; mysql>CHANGE MASTER TO MASTER_DELAY = 300; mysql>start slave; mysql> show slave status G SQL_Delay: 300 SQL_Remaining_Delay: NULL
8.1 恢复思路:
1主1从,从库延时5分钟,主库误删除1个库 1. 5分钟之内 侦测到误删除操作 2. 停从库SQL线程 3. 截取relaylog 起点 :停止SQL线程时,relay最后应用位置 终点:误删除之前的position(GTID) 4. 恢复截取的日志到从库 5. 从库身份解除,替代主库工作
8.3 故障模拟
1.主库数据操作 db01 [(none)]>create database relay charset utf8; db01 [(none)]>use relay db01 [relay]>create table t1 (id int); db01 [relay]>insert into t1 values(1); db01 [relay]>drop database relay;
以下是在从库中操作:
2、停止SOL线程
stop slave sql_thread;
3.找relaylog的截取起点和终点
起点:
Relay_Log_FIle : xxxx-relay-bin.xxxxxx
Relay_log_POS: xxx
终点:
show relaylog events in 'xxxx-relya-bin.xxxxxx'
4.备份sql语句:
mysqlbinlog --start-position=xxx --stop-position=xxx /data/3307/xxxx-relay-bin.xxxxxx >/tmp/relay.sql
5.从库恢复relay
source /tmp/relay.sql
6.从库身份解除
stop slave;
reset slave all;
======================================
9 过滤复制
主库:
show master status;
Binlog_Do_DB
Binlog_Ignore_DB
从库:
show slave statusG
Replicate_Do_DB: ###针对的是数据库
Replicate_Ignore_DB:
#针对表
Replicate_Do_Table:
Replicate_Ignore_Table:
配置,在从库的配置文件添加需要过滤的数据名或表名
vi /data/3308/my.cnf
replicate_do_db=数据库名
10. GTID:
GTID(Global Transaction ID)是对于一个已提交事务的唯一编号,并且是一个全局(主从复制)唯一的编号。
它的官方定义如下:
GTID = source_id :transaction_id
7E11FA47-31CA-19E1-9E56-C43AA21293967:29
什么是sever_uuid,和Server-id 区别?
核心特性: 全局唯一,具备幂等性
GTID核心参数
gtid-mode=on ####这个是核心参数,启动gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true ####核心参数 ---强制GTID的一致性
log-slave-updates=1 ####这个只是基于GTID主从复制的参数 --slave更新是否记录日志
编辑配置文件
[mysqld] basedir=/data/mysql/ datadir=/data/mysql/data socket=/tmp/mysql.sock server_id=51 port=3306 secure-file-priv=/tmp ###这个参数是用于限制load data,select .....outfile, load_file()传到哪个指定的目录下 autocommit=0 log_bin=/data/binlog/mysql-bin binlog_format=row gtid-mode=on enforce-gtid-consistency=true log-slave-updates=1 [mysql] prompt=db01 [\d]>
GTID从库误写入操作处理
查看监控信息: Last_SQL_Error: Error 'Can't create database 'oldboy'; database exists' on query. Default database: 'oldboy'. Query: 'create database oldboy' Retrieved_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-3 Executed_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-2, 7ca4a2b7-4aae-11e9-859d-000c298720f6:1 注入空事物的方法: stop slave; set gtid_next='99279e1e-61b7-11e9-a9fc-000c2928f5dd:3'; begin;commit; set gtid_next='AUTOMATIC'; 这里的xxxxx:N 也就是你的slave sql thread报错的GTID,或者说是你想要跳过的GTID。 最好的解决方案:重新构建主从环境
GTID复制和普通复制的区别
CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3307, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=444, MASTER_CONNECT_RETRY=10; change master to master_host='10.0.0.51', master_user='repl', master_password='123' , MASTER_AUTO_POSITION=1; start slave; (0)在主从复制环境中,主库发生过的事务,在全局都是由唯一GTID记录的,更方便Failover (1)额外功能参数(3个) (2)change master to 的时候不再需要binlog 文件名和position号,MASTER_AUTO_POSITION=1; (3)在复制过程中,从库不再依赖master.info文件,而是直接读取最后一个relaylog的 GTID号 (4) mysqldump备份时,默认会将备份中包含的事务操作,以以下方式 SET @@GLOBAL.GTID_PURGED='8c49d7ec-7e78-11e8-9638-000c29ca725d:1'; 告诉从库,我的备份中已经有以上事务,你就不用运行了,直接从下一个GTID开始请求binlog就行。
=================================================
半同步
1.1 什么是全同步?
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响
1.2 什么是半同步?
半同步复制(Semisynchronous replication)
首先,半同步是5.5版本推出的特性,介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库(详见参数rpl_semi_sync_master_wait_for_slave_count)接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用
1.3 什么异步复制?
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
配置半同步
加载插件 主: INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; 从: INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; 查看是否加载成功: show plugins; 启动: 主: SET GLOBAL rpl_semi_sync_master_enabled = 1; 从: SET GLOBAL rpl_semi_sync_slave_enabled = 1; 重启从库上的IO线程 STOP SLAVE IO_THREAD; START SLAVE IO_THREAD; 查看是否在运行 主: show status like 'Rpl_semi_sync_master_status'; 从: show status like 'Rpl_semi_sync_slave_status';