Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
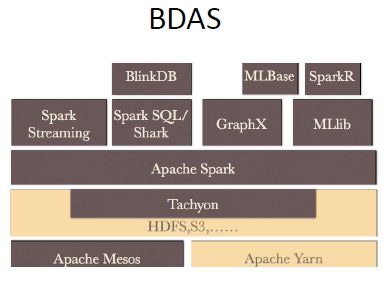
其中包括:资源管理框架,Apache YARN、Apache Mesos;基于内存的分布式文件系统,Tachyon;随后是Spark,更上面则是实现各种功能的系统,比如机器学习MLlib库,图计算GraphX,流计算Spark Streaming。再上面比如:SparkR,分析师的最爱;BlinkDB,我们可以强迫它几秒钟内给我们查询结果。
正是这个生态圈,让Spark可以实现“one stack to rule them all”,它既可以完成批处理也可以从事流计算,从而避免了去实现两份逻辑代码。
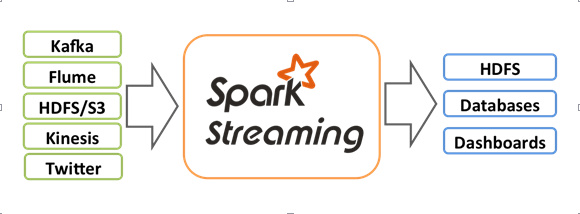
Spark Streaming是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘上。
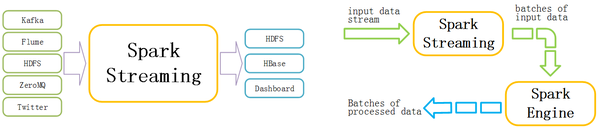
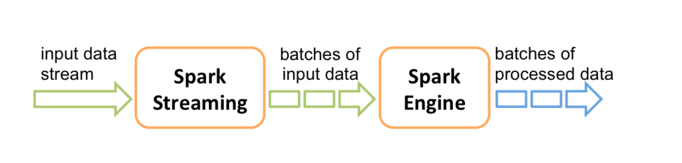
Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
Spark生态之Spark Streaming
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDD,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者-消费者模型
什么是DStream?
对应的就有生产者-消费者模型的问题,即如何协调生产速率和消费速率。
Spark Streaming的内部处理机制流程图
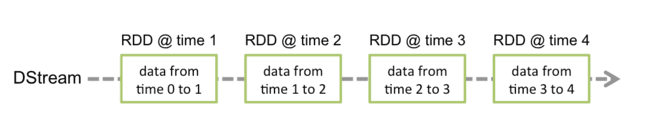
DStream内部的处理机制流程图