关于 Kafka
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 zookeeper 协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于 hadoop 的批处理系统、低延迟的实时系统、storm/Spark 流式处理引擎,web/nginx 日志、访问日志,消息服务等等,用scala语言编写,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源 项目。(以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间的访问性能。)
Kafka 的特点
①高吞吐量,低延迟: Kafka 每秒可以处理几十万条消息 延迟最多只有几毫秒
②可扩展性: Kafka 集群支持热扩展(热扩展指不重启整个集群的前提下,向集群中添加新的节点)
③持久性,可靠性:消息被持久化到本地磁盘并且支持数据备份防止丢失
④容错性:允许集群中的节点失败
⑤高并发:支持数千个客户端同时读写
Kafka 使用场景
①日志收集:一个公司使用 Kafka 收集各种服务的 log
②消息系统:解耦和生产者和消费者、缓存消息等。(解耦:在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。)
③用户活动跟踪:Kafka 也可用来记录 web 或者 app 用户的操作记录
④运营指标
⑤流式处理
⑥事件源
消息系统
消息系统主要的消息传递模式有两种:①点对点, ②发布-订阅模式。 Kafka 属于第二种传递模式。
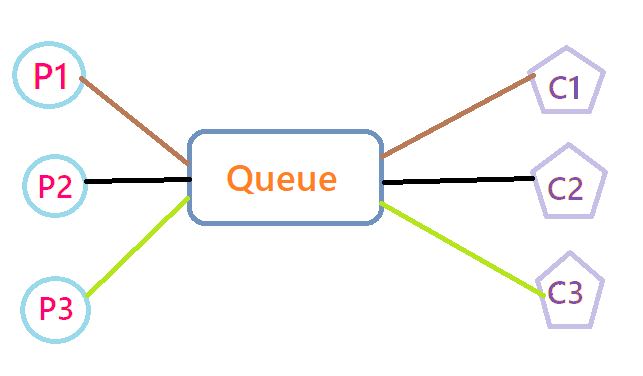
点对点传递:
在点对点消息系统中,消息持久化到一个队列中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序。
生产者发送消息到 queue 只有一个对应的消费者可以收到
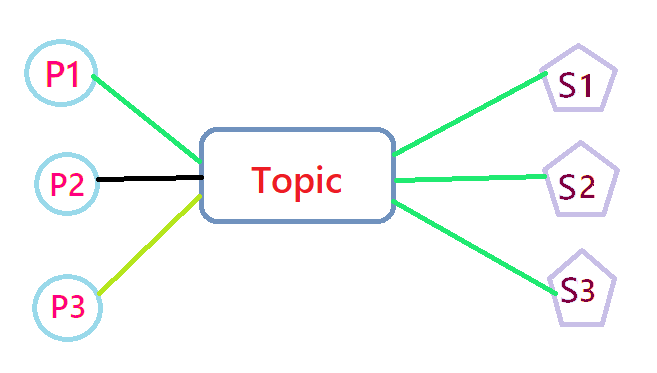
发布-订阅:
在发布-订阅消息系统中,消息被持久化到一个 topic 中。与点对点消息系统不同的是,消费者可以订阅一个或多个 topic,消费者可以消费该 topic 中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。(实际上,提供方和接收方之间会约定一个消息的主题topic,提供方往kafka发送消息时会告知这条消息属于哪个topic,kafka会负责管理和存放到相应的topic下。接收方会向kafka订阅topic,kafka会向订阅者推送消息)
发布者发送一条消息到 Topic 订阅该 Topic 的订阅者就都会收到
可以认为 kafka 是一个消息管理者,提供方可以把消息发给管理者,管理者再把消息发送给接收方,而消息通常是字符串。 至于 kafka 是单节点部署,还是集群部署,就好比管理者内部到底是只有一个人,还是一群人,都可以。节点多了的话查找和存放消息的效率会降低,通常一条消息只存放在一个节点上,而我们是向主节点获取信息,主节点会通过某种方式从集群中其他节点获取你所需要的信息,这样会慢一点但是优点是如果某个节点挂了还有其他的节点。一般生产环境中部署三个节点,一个主节点两个从节点。从节点挂了之后,还有另一个。主节点挂了会在从节点中 选举 新的主节点。三个节点可靠性相对较强。
Kafka 术语解释
broker
Kafka 集群包含一个或多个服务器,服务器节点称为 broker。
broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
如果某 topic 有 N 个 partition,集群有 (N + M) 个 broker,那么其中有 N 个 broker 存储该 topic 的一个 partition,剩下的 M 个 broker 不存储该 topic 的 partition 数据。
如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
Topic
每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)
Partition
topic中的数据分割为一个或多个 partition。每个 topic 至少有一个 partition。每个 partition 中的数据使用多个 segment 文件存储。partition 中的数据是有序的,不同 partition 间的数据丢失了数据的顺序。如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将 partition 数目设为 1。
Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。如果 Leader 失效,则从 Follower 中选举出一个新的 Leader。当 Follower 与 Leader 挂掉、卡住或者同步太慢,leader 会把这个 follower 从 “in sync replicas”(ISR) 列表中删除,重新创建一个 Follower。

Kafka 居然真的不是小饼干