摘要:
传统的评分预测只考虑到了文本信息,没有考虑到用户的信息,因为同一个词 在不同的用户表达中是不一样的。同样good 一词,
有人觉得5分是good 有人觉得4分是good。但是传统的文本向量表达无法区分。所以每个人都应该有一个属于自己的词向量。
传统的是word embedding的方式,这样处理,忽略了文档的生成者的特性。
因此本文讨论的是如何利用用户信息,来“修正”单词的特征表示。
作者提出了一套自己的表达词向量的方式,并不是用的word embedding.。
作者提出了将用户表示为一个转换矩阵,利用矩阵(用户)与向量(单词)的乘来得到新的单词向量。
然后 用修正的单词向量输入模型,进行预测。模型架构如下:
其中p是修正后的单词表示,u是用户,w是word.

UWCVM模型
User-Word Composition Vector Model(UWCVM)模型利用用户信息修正单词的特征表示。
Mitchell&Lapata[2]提出的两种基于向量的语义和用户组合的方法,如下图所示:

一种是加法模型:一种是乘法模型,乘法模型适合本文的假设,就是e可以修正u。
最初的想法是每个用户算一个word embeding,但是这样计算量比较大,另外每个
用户的词也比较少,训练不充分。

所以采用的是
每个用户的转换矩阵Uk的维度为dxd,其中d=50或100。把Uk分解为两个低秩矩阵,即矩阵分解:
Uk=U_k1*U_k2+diag(u')
在乘积模型(b)的线性转换的基础上,增加一层非线性变换的连接层,采用tanh作为激活函数。

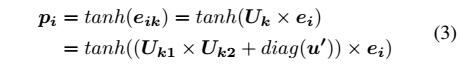
DCVM模型
Document Composition Vector Model(DCVM)模型用于综合所有的单词向量,生成文档(即每条评论review)的向量表示。
本文采用了Hermann&Blunsom[3]提出的方法,即用biTanh迭代地生成文档的向量表示。
包括以下两个步骤:
以修正后的单词向量作为输入,应用biTanh函数得到句子的向量表示。以句子的向量表示作为输入,应用biTanh函数得到文档的向量表法。
文章指出,这样迭代地使用biTanh函数可看作是两对词袋的卷积神经网络。
其实就是卷积神经网络。
评分预测
将学习得到的文档模型应用到有监督的metriclabeling[4]框架中。主要包括以下两个步骤:
(1)仅基于用户-评论对的向量表示,学习一个初始预测器。以下的损失函数是我们要优化的目标:
(2)将初始的分类器应用到metriclabeling框架中,其主要思路是“similaritems,similarlabels”。Metriclabeling的训练目标是最小化如下的损失函数:
关于公式的参数含义和详细定义,请查阅原文。
实验结果
文章给出了在两个真实数据集上的实验结果,如下图所示:

作者在presentation中提到该模型的一个扩展版本,发表在ACL2015[5]。主要区别是后来的版本添加了物品的文本描述信息。两个模型的具体对比如下:
IJCAI2015:

ACL2015:
