1、为什么Ranking Model采用了weighted logistic regression作为输出层?在模型serving过程中又为何没有采用sigmoid函数预测正样本的probability,而是使用 这一指数形式预测用户观看时长?
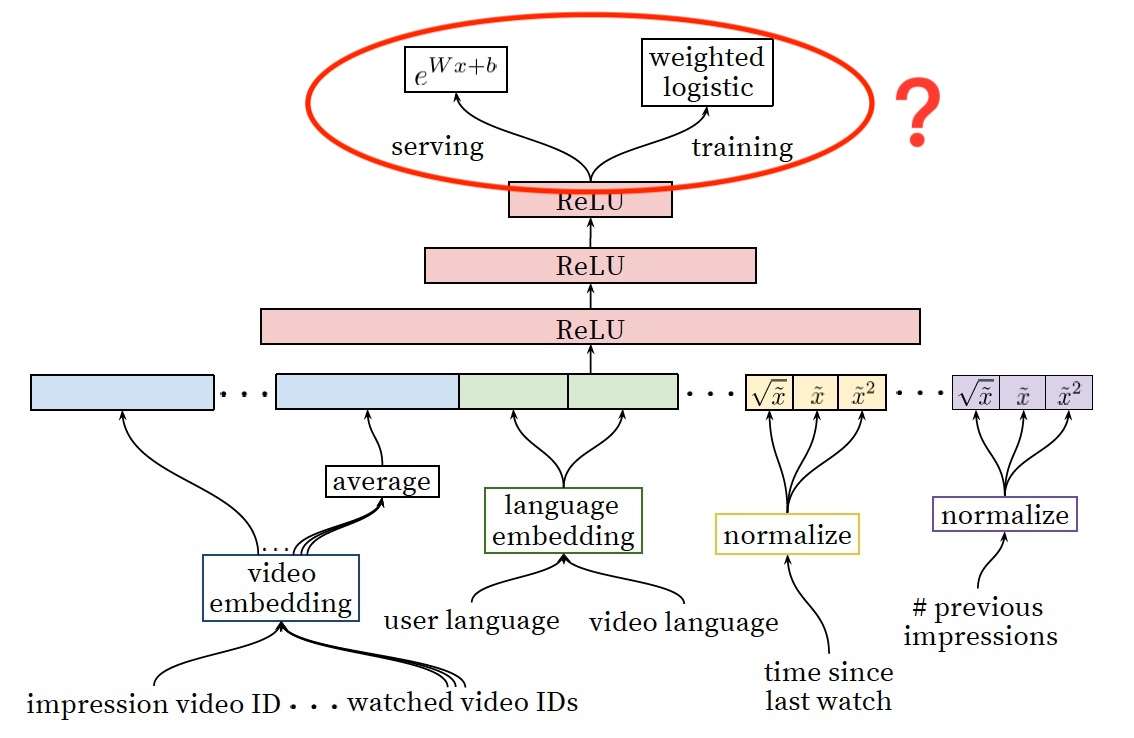

再简要总结一下YouTube Ranking Model的Serving过程要点。
这一指数形式计算的是Weighted LR的Odds;
- Weighted LR使用用户观看时长作为权重,使得对应的Odds表示的就是用户观看时长的期望;
- 因此,Model Serving过程中
2、如果是排序使用的话,odds和sigmoid单调性一致;如果使用时长后续有其他处理,和直接回归或多分类有多大差别,为什么感觉有些迂回?
a:回归有一个问题在于值域是负无穷到正无穷,在视频推荐这样一个大量观看时间为0的数据场景,为了优化MSE,很可能会把观看时间预测为负值,而在其他数据场景下又可能预测为超大正值。逻辑回归在这方面的优势在于值域在0到1,对于数据兼容性比较好,尤其对于推荐这种rare event的场景,相比回归会更加适合。而且odds的值域也是非负的,符合watch time的物理意义。
q:那如果把观看时间quantization成k个bucket然后做多分类 是不是也可以 感觉比weightedLR更简单train起来 当然会损失点效果可能
a:多分类输出粒度不够细,不适合用来做排序。此外多分类的参数数量也比二分类多很多,同样的样本量下训练效果可能不如二分类效果好。
q:serving的时候,sigmoid和和指数函数都是单调递增的。如果取固定的top K个item做曝光,那这两种方式结果完全是一样的,没理解为什么还要用指数函数。
a:如果只是涉及到排序阶段的话,结果应该是一样的,看自己业务需要,如果是广告算法,需要乘以对应的cpc,结果就有不同了;因为预估的时长值后面会用到的,这里不能只看序
q:不明白 我可以在一开始使用观看时长除以视频时长得到一个0到1的数 这样就没有边界问题了 很疑惑 求指教
a:你说这种做法只能对训练数据有效,但不能保证得到的模型预测结果也在01之间。

参考:https://zhuanlan.zhihu.com/p/61827629